

A Hybrid Transactional and Analytical Processing (HTAP) database can process OLTP and OLAP workloads in the same architecture without the workloads interfering with each other. Gartner coined the term HTAP in 2014 to refer to in-memory databases with hybrid workload processing capabilities, such as SAP HANA.
However, technical challenges have prevented HTAP databases from really catching on. Only recently, with the emergence of modern data architectures such as TiDB, AlloyDB from Google, and UniStore from SnowFlake, is HTAP on the rise.
In this post, we’ll share the benefits of HTAP and the technological evolution that’s making HTAP possible. We’ll also illustrate the major challenges in modern HTAP architecture and how to solve them by diving into two representative HTAP databases, TiDB and AlloyDB.
A quick bit of history….
For decades, Online Transactional Processing (OLTP) and Online Analytical Processing (OLAP) workloads have been processed separately by different database systems. This has been the norm because the two workloads differ in design factors such as latency, throughput, and data consistency. This is also why an individual database system may focus on either OLTP or OLAP workload. Take latency for example, an operational database usually requires very short latency but a data warehouse or a data lake system can tolerate much longer latency.

Figure 1. Typical latencies of different database systems.
However, this also causes complicated technology stacks and data silos, which limit how fast companies can grow. This calls for a hybrid approach.
The beauty of HTAP
Regardless of how it is implemented, a modern HTAP architecture typically features cloud scalability, and one data entry with one infrastructure stack. There, OLTP data and OLAP data can be synchronized in real time. Some OLAP implementations use a Massively Parallel Processing (MPP) push-down approach to analyze operational data without having to change the application or schema, the extract, transform, and load (ETL) process, or data movement between different systems.
With an HTAP system, data-intensive applications run directly from the mission-critical operational or transactional workloads, with a much easier and more modern architecture design and implementation. The applicable scenarios range from real-time business intelligence, real-time personalized recommendations, and reporting, to online operation analysis, and real-time marketing for e-commerce..
HTAP can tremendously simplify the whole data infrastructure stack as well as application development. This greatly reduces the time-to-market process. As an example, OSS Insight, an open source insight website that builds upon an HTAP system, reduced its time-to-market from months to just a few weeks. In future HTAP posts, I will discuss other benefits.
Making HTAP a reality
With the help of a modernized architecture design, database systems like TiDB and AlloyDB leverage technologies such as a scalable distributed SQL architecture, a row- and column-based storage engine, Raft-based replication, a distributed vectorized execution engine, and a sophisticated cost-based optimizer. These systems incorporate OLTP and OLAP processing capabilities in one system.
In this section, we’ll present the major challenges of implementing HTAP. We’ll also share two real-world HTAP systems—TiDB and AlloyDB—and show how they overcome these challenges and make HTAP come true.
Major challenges to tackle
As mentioned earlier, HTAP is not a new concept, but it didn’t garner much attention until recently. The in-memory approach to HTAP like HANA was fast, but it was expensive and proprietary. A modern and more practical approach has major technological challenges. These include how to leverage the row and column storage for maximized write and read performance, and how to decide the best execution plan for queries.
Row-based and column-based storage engines
OLAP queries typically use column format storage to efficiently access data in batches. In contrast, OLTP operations benefit from row storage for intensive writes. That’s why It is difficult for a conventional database to leverage row-store and column-store to boost performance for hybrid workloads in a single system. This is the primary puzzle to solve for a HTAP database.

Figure 2. Row-based storage vs. column-based storage.
Smart query optimizer
One of the key components of a database is the query optimizer. Its function is so complex that designing an optimizer is sometimes considered “even harder than rocket science.” These challenges become much harder when it comes to optimizing HTAP workloads. They include:
- The search space to explore for the optimal plan expands significantly as more plan choices are evaluated.
- Heterogeneous storage engines pose extra challenges on the cost estimation for optimizers to differentiate the operators in query execution engines.
Therefore, a smarter query optimizer for HTAP overcomes these challenges and makes the right decision on how to process HTAP workloads efficiently.
Real-world HTAP example: TiDB
TiDB is the only open source, MySQL-compatible distributed SQL database that provides HTAP capabilities. It has been adopted as the primary database in thousands of production systems across different industries. TiDB’s flavor of HTAP architecture is typical, in that it uses a decoupled architecture that separates computing and storage. It implements row storage and column storage for hybrid workloads with some major technologies under the hood.
To learn more about TiDB’s HTAP implementation, see the paper we presented at VLDB, TiDB: A Raft-based HTAP Database[1].
Decoupled architecture
To take full advantage of elastic infrastructure in the cloud era, TiDB has a distributed architecture that provides flexible scalability. TiDB cluster consists of three major components:
- TiDB servers receive and process SQL requests.
- Placement Driver (PD) manges cluster metadata and provides global clock service for distributed transactions.
- Storage servers persist data in TiKV row store and TiFlash column store.

Figure 3. TiDB’s HTAP architecture.
In this architecture, the computing and storage resources are separate, and you can scale each one independently. TiDB integrates storage engines of both row and column formats and decides the best way to access data. TiKV is specially designed for OLTP scenarios with row store, while TiFlash is column-oriented storage for OLAP workloads.
Distributed execution engine
The TiDB distributed execution engine has three parts: the TiDB server runtime, distributed TiKV coprocessors, and the TiFlash Massively Parallel Processing (MPP) execution engine. The following figure shows the general execution diagram of TiDB.

Figure 4. TiDB execution diagram.
The TiDB server runtime is the execution “coordinator.” TiKV coprocessors are deployed together with TiKV row stores and provide “near storage” computation. This enables TiDB to process the data on each TiKV instance in parallel.
Similarly, TiDB pushes down the projection, selection, aggregation and sort (TopN) and distributed JOIN to the TiFlash MPP execution engine. This enables the TiFlash MPP execution engine to carry out complex analytical processing.
By incorporating TiKV coprocessors and the TiFlash MPP execution engine, TiDB can process queries efficiently. It handles HTAP workloads that neither row store nor column store alone can serve well.
A real-world example of smart optimizer
As mentioned earlier, how to implement a query optimizer to decide the right execution plan for queries is paramount for HTAP workloads. TiDB’s answer is TiDB optimizer, which generates query plans that can best leverage row storage, column storage, and execution engines. It not only decides whether to use row or column data, but also considers which execution engine to use for each “pushdown” computation.
With an optimized plan, TiDB optimizer pushes down as much computation as possible to the distributed row-based coprocessors or MPP execution engine. This takes advantage of distributed computation and reduces the intermediate results. It also minimizes the computation load on the TiDB server.
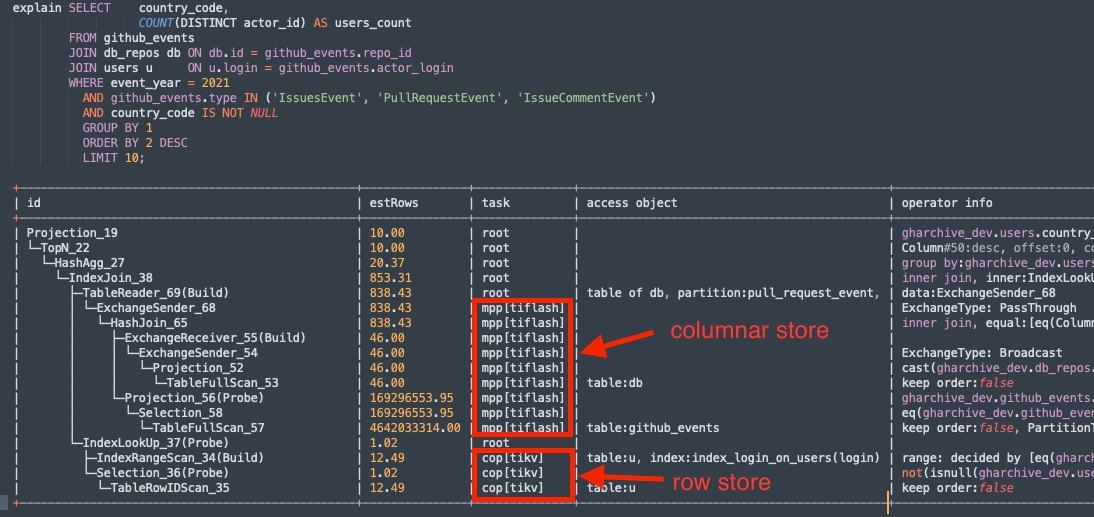
Figure 5. A query and its plan generated by TiDB optimizer.
Here’s an example query from the OSSInsight platform that runs on top of TiDB. The query is to find out which countries and regions had the most database contributions on GitHub in 2021. With the help of TiDB optimizer, the generated plan leverages both TiKV row-based coprocessors and the TiFlash column-based MPP execution engine. The query plan in the figure shows that the index access to the user table is chosen for TiKV row store, while the distributed hash join of tables github_events and db_repos are chosen for the TiFlash MPP engine of column store.
Real-world HTAP example: AlloyDB
AlloyDB is a HTAP system created by Google to help users modernize their legacy databases with open source PostgreSQL compatibility. AlloyDB’s core is an optimized storage service with separate compute and storage. The below figure shows its high-level architecture.

Figure 6. High-level HTAP architecture of AlloyDB.
Some of the key designs and technologies of AlloyDB include:
- In-memory column data. Column data is automatically generated and refreshed without user actions. It’s based on machine learning (ML) assisted prediction.
- Separate compute and storage. A separate database (compute) layer from the storage service offloads operations like log processing to the storage layer. Tiered layers of caches help boost performance and scalability.
- ML-assisted management and inferencing. AlloyDB leverages ML technologies to achieve different system optimizations including storage and memory management, column data conversion, vacuum management, and allows users to call its ML models in a query.
For more information on AlloyDB, see its documentation and its release blog Introducing AlloyDB for PostgreSQL.
An apples-to-apples comparison of TiDB and AlloyDB
In this section, we’ll compare and analyze TiDB and AlloyDB from different aspects of a database system. You’ll begin to see their similarities and differences as HTAP databases.
General aspects and functionalities
TiDB is a fully open source database system, whose three kernel components, TiDB, TiKV, and TiFlash, are all open source projects, and TiKV is a CNCF graduated project. AlloyDB is “compatible” with the open source PostgreSQL; however, none of its own features is open source, and there are no plans to open source them.
TiDB is MySQL compatible, and AlloyDB is PostgreSQL compatible. The compatibility allows current MySQL or PostgreSQL users to easily migrate their applications to the new system with less or no extra effort.
AlloyDB and TiDB both use ML technologies. AlloyDB integrates ML inference computation with its extended SQL syntaxes and leverages it in scenarios such as predicting when to generate in-memory column data. TiDB leverages ML in its system tuning services.
Query processing engine
Query processing engines of both TiDB and AlloyDB can process row format and column format data at the same time with decisions made by the query optimizer. This allows them to better process a hybrid workload of OLTP and OLAP by best utilizing their query processing engines.
The main difference between the TiDB and AlloyDB query processing engine is whether it utilizes a distributed query processing engine. The TiDB query processing engine consists of TiDB server runtime, TiKV distributed coprocessors, and the TiFlash MPP execution engine. The latter two reinforce TiDB with powerful distributed processing capabilities. On the other hand, AlloyDB retrieves data and carries out query computation in a single node (primary or replica server node).
Row and columnar data storage engine
Both TiDB and AlloyDB support row format and column format data. However, AlloyDB only stores row format data in its persistent shared block storage and the block caches in Logic Production System (LPS) nodes. The column data is generated on demand and resides in the memory cache of a primary or replica server node. As data grows, scalability could be a performance bottleneck.
On the other hand, TiDB stores both row and column format data in the persistent storage. TiDB always replicates the column data via its Raft-based replication algorithm. This allows TiDB to access the column data in real-time without any delay or data loss. TiDB’s distributed architecture features horizontal scalability.
Better resource separation is another benefit of keeping both row and column format data in the storage engine. As for TiDB, TiKV and TiFlash can process row and column format data without impacting each other. In many scenarios, this separation can greatly help to boost the query processing performance (for example, throughput) and stability.
TiDB vs. AlloyDB: Comparing two HTAP databases
| TiDB | AlloyDB | |
| SQL compatibility | MySQL | PostgreSQL |
| Fully open source | Yes | No |
| High availability | Yes (cross zone and region) | Yes (cross zone) |
| Scalability | No limit | Up to 1000s of vCPUs |
| Deployment | Multi-cloud (AWS, GCP) and private | Cloud service (GCP only) |
| Dynamic resizing | Yes | Yes |
| Storage | Local storage, Elastic Block Store (EBS) | Distributed file system (Colossus) + tier caches |
| Persistent storage | Row, column | Row (in-memory column) |
| Column data definition | User defined and fully controlled via data definition language (DDL) | System decision (or set via command) |
| Real-time column data | Yes (Raft-based replication, MVCC) | No (on-demand conversion, AI-predicted) |
| Query execution engine | Distributed row store coprocessor + MPP columnar engine | Single execution node without MPP mode |
| Columnar execution | Vectorized | Vectorized |
| Computation pushdown at storage layer | Filtering, aggregation, LIMIT, TopN, JOIN | None |
| ML integration | Integrated with TiDB Autonomous Service (for tuning and advisory only) | Integrated with Vertex AI Platform (for both tuning and ML inference) |
Wrapping up
TiDB and AlloyDB can both serve as a primary database to help users keep up with their fast growing and complex business workloads. They are especially good choices when a single conventional OLTP or OLAP database finds a workload extremely challenging to process.
TiDB or AlloyDB each have their own merits and best applicable scenarios. They are solid solutions that could fit businesses based on the ecosystem, growth, and workloads. Together, both reveal that the era of HTAP is here, and we expect more and more HTAP systems coming on the horizon.
Here are some additional HTAP resources to explore:
- HTAP Summit 2023 session replays
- Real-World HTAP: A Look at TiDB and SingleStore and Their Architectures
- The Long Expedition toward Making a Real-Time HTAP Database
- Build a Better Github Insight Tool in a Week? A True Story
References:
Experience modern data infrastructure firsthand.
Related Resources

Solution
The FinTech Scalability Crisis: How Distributed SQL Unlocks Innovation with Zero Downtime Operations

Product
TiDB Cloud’s New Navigation: Built for Context, Clarity, and Scale

Product
TiDB Cloud Dedicated Now in Public Preview on Microsoft Azure: Distributed SQL, Anywhere You Need It
TiDB Cloud Dedicated
A fully-managed cloud DBaaS for predictable workloads
TiDB Cloud Serverless
A fully-managed cloud DBaaS for auto-scaling workloads