Data-intensive applications generate and consume data at an unprecedented rate, placing immense pressure on underlying database scaling strategies. User expectations for performance and availability are higher than ever, demanding instantaneous results and seamless handling of fluctuating loads. Consequently, a database’s ability to scale—adjusting its capacity to meet demand—is a fundamental requirement for business success.
Effective scalability ensures applications remain responsive and efficient, preventing performance degradation, slow queries, user frustration, downtime, and lost revenue. Scalability includes both expansion (scale up vs. scale out) and contraction (scaling down or in) to optimize resources and reduce costs.
Organizations typically face two primary scaling strategies:
Horizontal Scaling (Scaling Out): Adding more machines to distribute the workload.
Vertical Scaling (Scaling Up): Enhancing the power of a single machine.
Which Database Scaling Approach Should I Choose: Scale Up vs. Scale Out?
If your workloads are highly dynamic, require high availability, or need to handle millions of concurrent requests, horizontal scaling is likely the better fit. For simpler architectures or predictable growth, vertical scaling may offer short-term simplicity, even if it comes with hard limits.
Choose Vertical Scaling if:
You need a fast and simple upgrade path
You’re dealing with modest growth
You’re not yet constrained by single-node limits
Choose Horizontal Scaling if:
You need scale-out elasticity
You can’t tolerate single points of failure
You’re building for long-term growth or distributed workloads
Choosing the right strategy impacts performance, cost, complexity, and long-term viability. Neither approach is universally superior; understanding their trade-offs is crucial for addressing current bottlenecks and ensuring sustainable growth. In the cloud era, cloud database scaling is linked to business agility and cost-efficiency, making this choice central to cloud architecture.
This guide explores both strategies, compares their strengths and weaknesses, examines the business drivers for scaling, and provides a modern solution leveraging horizontal scaling.
Discover how leading SaaS teams horizontally scale to millions of tables and support AI-native workloads.
Horizontal scaling (“scaling out”) adds more machines (nodes or instances) to a resource pool and distributes the workload across them, like adding lanes to a highway.
How It Works
Horizontal scaling uses a distributed architecture:
Load Balancing: Distributes incoming requests across multiple servers.
Database Sharding/Partitioning: Divides data into subsets stored on separate nodes.
Database Replication: Maintains data copies on multiple nodes for read scaling or high availability.
Distributed Frameworks: Technologies like Kubernetes manage scaling across machine clusters.
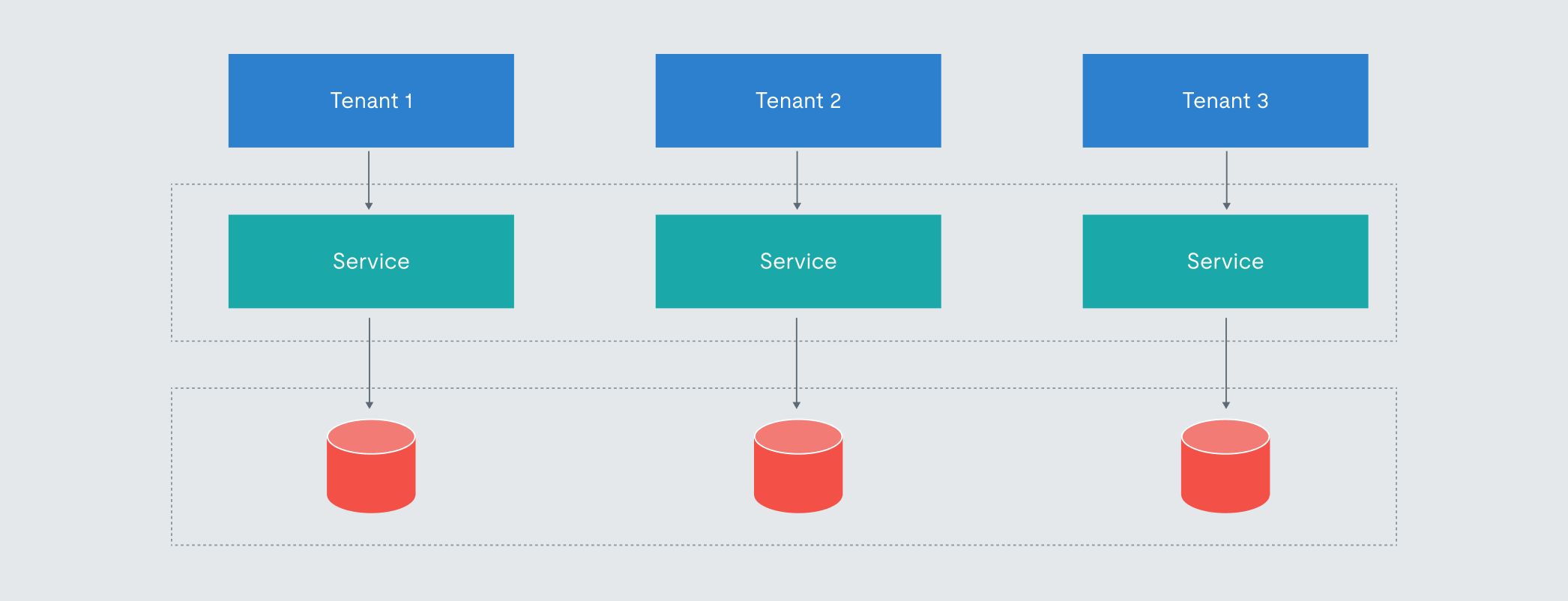
Figure 1. A representation of horizontal scaling in a typical multi-tenant SaaS architecture.
Implementation typically requires designing applications for a distributed environment.
Horizontal Scaling Advantages
High Scalability & Elasticity: Offers virtually limitless scaling by adding nodes. Highly elastic, allowing easy scaling out and in to match demand and optimize costs.
High Availability & Fault Tolerance: Eliminates single points of failure; if one node fails, others continue operating. Enables rolling updates without downtime. Crucial for mission-critical systems.
Potential Performance Gains: Distributes load, preventing bottlenecks. Ideal for parallel processing and high concurrency. Geographic distribution can reduce latency.
Cost-Effectiveness (Long-Term): Often uses commodity hardware, offering better price/performance at scale. Costs are more linear and predictable. Reduced downtime lowers overall costs. Supports pay-as-you-go models.
Flexibility & Future-Proofing: Adapts to changing workloads. Allows adding newer, efficient nodes over time. Supports varied node configurations.
Auto-Sharding Capability: Automatically handles data sharding and rebalancing across nodes, eliminating the need for manual partitioning and complex data distribution logic. Reduces operational overhead, simplifies scaling, and ensures consistent performance as workloads grow or shift.
Find out how Dify consolidated 500,000+ SQLite containers into a single horizontally scalable database cluster.
Increased Complexity: Managing distributed systems (multiple nodes, load balancers, data distribution) is more complex. Requires specialized skills.
Application Architecture Changes: Often requires significant application redesign for distributed operation.
Data Consistency Challenges: Ensuring consistency across nodes, especially for ACID transactions, is difficult. Database joins become more complex. Requires sophisticated mechanisms.
Network Latency & Overhead: Relies on network communication between nodes, introducing latency.
Higher Initial Setup Costs: Requires multiple servers/instances, load balancers, and potentially more complex monitoring solutions initially.
Horizontal scaling dominates large-scale applications but requires careful planning and often specialized distributed database architecture.
What is Vertical Scaling (Scaling Up)?
Vertical scaling (“scaling up”) increases the capacity of an individual server by enhancing its resources, like upgrading a computer’s CPU, RAM, or storage. The goal is to make the existing machine more powerful to handle increased load without adding more servers.
How It Works
Vertical scaling involves upgrading components on the same machine: CPU, RAM, storage, or network interfaces. In cloud environments, this usually means restarting the virtual machine on a larger instance type with more resources. The principle remains: enhance a single node.
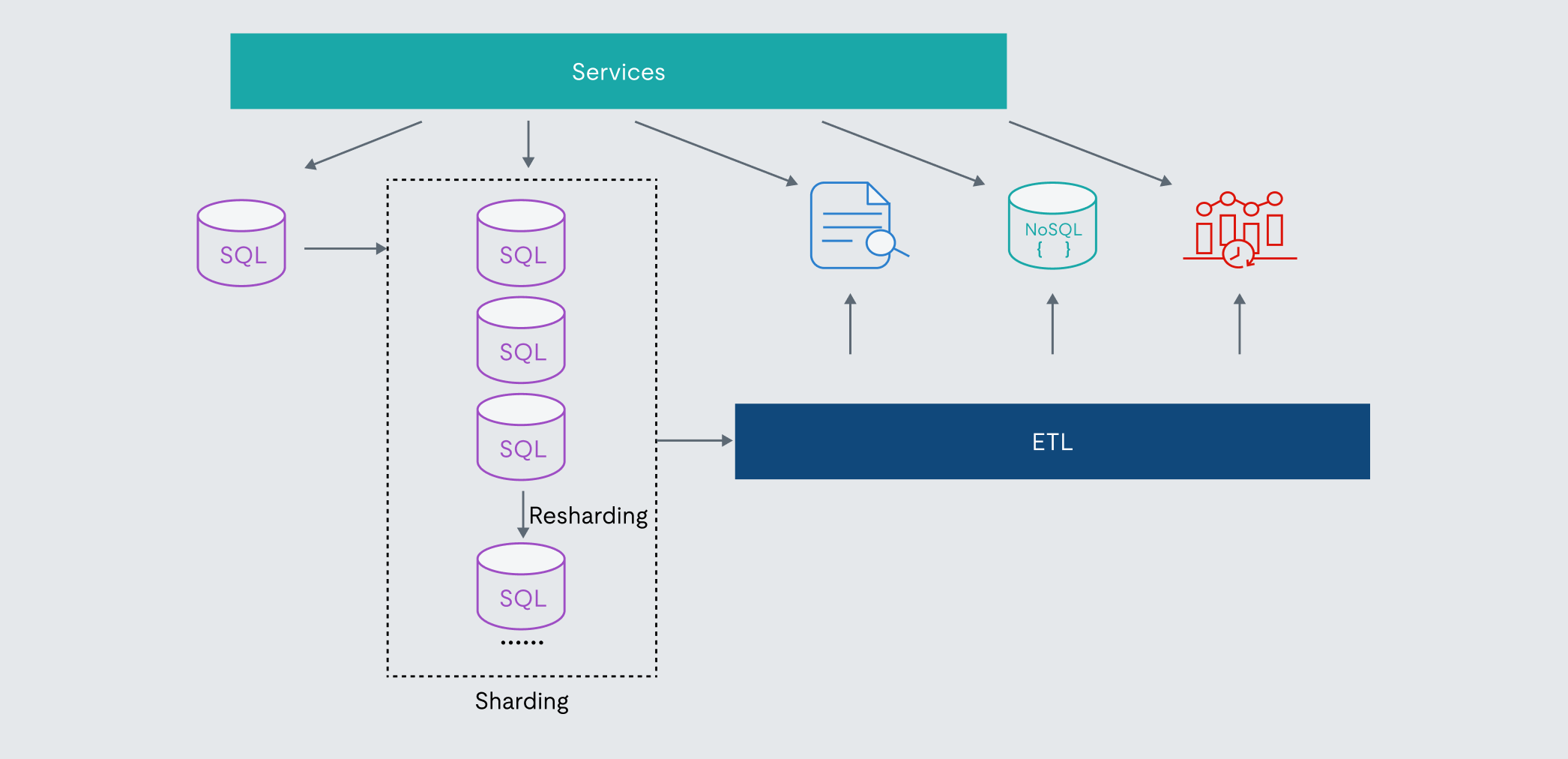
Figure 2. A representation of vertical scaling in a typical SaaS application.
Vertical Scaling Advantages
Simplicity: Often seen as simpler and faster than redesigning for distribution.
Application Transparency: Usually requires few or no application code changes.
Potential Initial Cost-Effectiveness: Upgrading might be cheaper initially than buying multiple new servers.
Lower Communication Latency: Processes communicate faster within a single machine.
Simpler Data Management: Data consistency is easier with data on a single node.
Vertical Scaling Disadvantages Limitations
Hardware Ceiling: There’s an absolute maximum capacity for any single server or instance type.
Downtime Required: Upgrades almost always necessitate taking the server offline, which is unacceptable for high-availability applications. This downtime carries significant business costs.
Single Point of Failure (SPOF): If the single machine fails, the entire system becomes unavailable, increasing risks of data loss and prolonged outages.
Exponentially Increasing Costs: High-end hardware costs increase non-linearly, offering diminishing performance returns. Cloud upgrades can also be inefficient.
Resource Bottlenecks & Amplified Problems: Bottlenecks can shift, and larger hardware might amplify existing application flaws, sometimes leading to slower performance despite upgrades.
Limited Elasticity: Scaling down often requires disruptive downtime, making it inflexible for fluctuating workloads.
Vertical scaling can work for predictable growth and downtime tolerance but is problematic for large-scale, mission-critical systems due to its inherent limits.
Join leading data experts as they explain why teams are replacing vertically scaled systems with distributed SQL.
Lower initial cost; High TCO at scale (premium hardware, downtime)
Implementation Complexity
More complex (requires distributed architecture/app changes)
Simpler (upgrade existing system)
Management Complexity
More complex (manage cluster, distribution, consistency)
Simpler (single node)
Reliability/Availability
Higher (Fault tolerant, no SPOF)
Lower (Single Point of Failure)
Downtime for Scaling
Minimal/Zero (add/remove nodes, rolling updates)
Required for upgrades/changes
Data Consistency Mgmt
Complex (across distributed nodes)
Simple (single node)
Elasticity
High (easy scale out/in, suitable for auto-scaling)
Low (scaling up/down often disruptive)
Hybrid approaches exist, combining larger nodes within a horizontal architecture. The best approach depends on workload characteristics and requirements. Vertical scaling may suit predictable growth and downtime tolerance. Horizontal scaling is preferred for unpredictable workloads, high concurrency, microservices, and high availability needs, often requiring databases designed for distribution.
Why Database Scaling Strategies Become Critical: Business Challenges & Technical Pain Points
The need for database scaling strategies stems from tangible business problems caused by the inability to handle growing demands.
Common Triggers & Pain Points
Performance Degradation & Latency: Applications slow down, queries take longer, impacting user satisfaction and productivity. Databases not optimized for distributed workloads often struggle under high concurrency.
Increased Downtime & Availability Issues: Overloaded systems crash more often. Vertical scaling’s SPOF and maintenance windows cause unavailability. Downtime means lost revenue and damaged trust. A distributed SQL database can mitigate this with built-in fault tolerance and online scaling.
Inability to Handle Growth: Existing architecture cannot keep pace with increasing data, users, or transactions, stifling business expansion and opportunities. A distributed database architecture’s horizontal scalability makes it easier to grow without re-architecting.
High Operational Costs & Complexity: Vertical scaling leads to expensive high-end hardware. Manual horizontal scaling (sharding) is complex and requires specialized skills. Cloud database scaling costs can escalate without elasticity. This diverts resources from innovation. A distributed database architecture can simplify this with auto-sharding and cloud-native elasticity, helping control infrastructure and ops costs.
Architectural Limitations: Monolithic applications are hard to scale incrementally. Traditional relational databases struggle with horizontal write scaling and distributed consistency. Poor schema design or indexing becomes problematic at scale. A distributed database architecture can support both online transactional processing (OLTP) and online analytical processing (OLAP) workloads.
Resource Bottlenecks: Systems hit limits on CPU, RAM, IOPS, or network bandwidth, causing performance issues. A distributed database architecture’s separation of compute and storage allows for more flexible and efficient resource scaling.
Addressing these pain points is critical, as poor scalability directly impacts revenue, productivity, reputation, and growth. A proactive approach to scaling, anticipating future needs, prevents costly emergency fixes and supports smoother growth.
Four Hidden Costs of Database Scaling
While cloud bills and instance pricing are often the most visible costs of scaling, they’re far from the most expensive. Choosing the wrong scaling path—or delaying the right one—can introduce operational drag, engineering inefficiencies, and lost business opportunities. Here are four hidden costs every team should weigh when planning for growth:
1. Downtime and Disruption
Outages caused by vertical scaling limits or brittle sharding schemes don’t just hurt uptime SLAs. They damage user trust, derail internal roadmaps, and divert resources to firefighting.
Example: Schema changes on monolithic databases often require maintenance windows or cause lock contention, creating unacceptable service disruption at scale.
2. Engineering Time and Context Switching
Maintaining and working around systems that weren’t designed to scale horizontally drains developer productivity. Manual sharding, custom routing logic, and hand-stitched failover mechanisms all represent time engineers could spend building features—not fighting infrastructure.
Opportunity cost: Every hour spent on scaling workarounds is an hour not spent shipping differentiated product value.
3. Operational Complexity and Tooling Overhead
Workarounds for scaling limitations often lead to fragmented infrastructure—multiple databases, duplicated monitoring stacks, and brittle deployment pipelines. This increases the surface area for bugs and makes it harder to enforce consistency, observability, and compliance.
Result: Ops teams struggle to manage and monitor a growing patchwork of systems, increasing the risk of human error and prolonged incidents.
4. Business Agility and Opportunity Cost
The real cost of not scaling effectively? Missed market opportunities. Whether it’s delaying an international launch, avoiding a high-growth customer segment, or failing to capitalize on real-time analytics, slow scaling can limit your business model.
Strategic impact: Scaling should be an enabler of growth—not a blocker.
Introducing TiDB: A Distributed SQL Solution That Solves Horizontal Scaling Challenges
Traditional scaling limitations necessitate modern, inherently scalable solutions like TiDB.
What is TiDB?
TiDB is an open-source, distributed SQL database designed for horizontal scalability, strong consistency (ACID compliance via Raft), and high availability (automatic failover). It aims to combine the strengths of relational databases with NoSQL scalability.
Key Differentiators
Horizontal Scalability by Design: Separates compute and storage, enabling independent, elastic scaling by adding nodes.
MySQL Compatibility: Speaks the MySQL protocol, simplifying migration from MySQL-based applications, often requiring minimal code changes.
Mixed Workload Processing: Integrates row-based and columnar-based storage. Real-time data replication allows analytics on fresh data without impacting OLTP database performance or needing separate ETL pipelines. This simplifies architecture and reduces costs.
Cloud-Native Architecture: Runs effectively on public/private clouds and Kubernetes. TiDB Operator automates Kubernetes management, and TiDB Cloud offers a fully managed DBaaS.
AI-Ready Platform: TiDB serves as a unified data platform for AI workloads, combining transactional data, analytical insights, vector search capabilities, and knowledge graph integration. This makes it ideal for building intelligent applications that require real-time context, flexible data models, and low-latency search.
TiDB provides SQL familiarity and strong consistency with massive horizontal scalability, automating the complexities of distributed data management.
Experience horizontal scaling, mixed workload processing, and MySQL compatibility with zero infrastructure setup.
For decades, horizontal scaling was considered the domain of NoSQL databases, while traditional SQL systems remained largely confined to single-node vertical scaling. This belief stemmed from the architectural complexity involved in preserving strong consistency, ACID compliance, and SQL semantics in distributed environments. As a result, many teams assumed they had to choose between scale and structure—either give up SQL’s expressive power or forgo elastic scale-out.
But data-intensive application demands have outgrown that trade-off.
From real-time financial transactions to large-scale SaaS workloads, today’s systems need both: the rigor of relational models and the elasticity of horizontal scaling. TiDB is purpose-built to meet that challenge. As a distributed SQL database, TiDB retains full MySQL compatibility while delivering native horizontal scalability, automatic data sharding, and strong consistency powered by the Raft consensus algorithm.
The result? You get the familiar power of SQL—joins, transactions, indexes—without the bottlenecks of monolithic infrastructure. TiDB makes horizontal scaling a reality for SQL workloads, empowering teams to scale predictably, simplify operations, and meet the performance demands of modern data-intensive systems.
How TiDB Excels at Horizontal Scaling: A Distributed Database Architecture Deep Dive
TiDB’s horizontal scalability stems from its distributed architecture, separating compute and storage layers for independent scaling.
Distributed SQL Architecture Overview
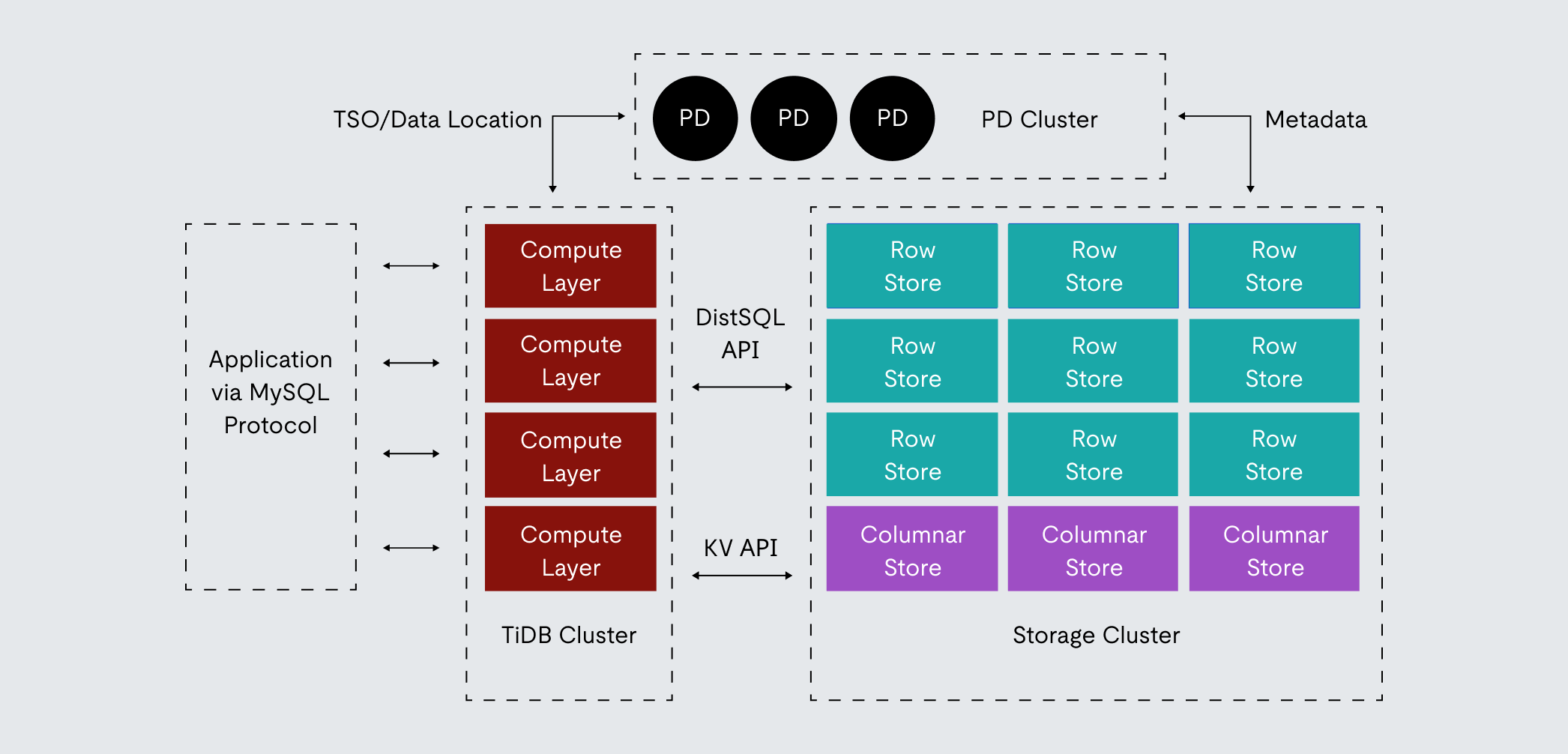
The cornerstone of TiDB’s scalability is the clear separation of its computing and storage layers. This allows each layer to be scaled independently based on specific workload demands, providing flexibility and optimizing resource utilization. This contrasts sharply with traditional databases where compute, storage, and transaction management are tightly integrated within a single system, often leading to bottlenecks and scaling limitations.
Figure 3. A diagram showing the various components that make up TiDB’s architecture.
Core Components
The TiDB cluster comprises several key components working in concert:
Compute Layer: This layer acts as the stateless SQL interface to the cluster. It receives SQL queries from applications (using the MySQL protocol), parses them, performs query optimization (leveraging statistics from the storage layer), and generates distributed execution plans. Because TiDB’s compute layer is stateless (it doesn’t store persistent user data), this layer can be easily scaled horizontally by adding or removing instances behind a load balancer (like TiProxy, LVS, HAProxy) to match query processing demand. This elasticity is crucial for handling variable query loads without impacting the underlying storage or requiring complex data migrations, embodying the core principles of auto-scaling databases.
Row Store: This is the core distributed, transactional key-value storage engine where the actual data resides. Data is automatically partitioned into manageable chunks called “Regions,” typically based on key ranges. Each Region is replicated (usually 3 times by default) across different row store nodes using the Raft consensus protocol for consistency and high availability. The row store layer is horizontally scalable; adding more row store nodes increases both the total storage capacity and the aggregate I/O throughput of the cluster. Row store uses RocksDB as its underlying storage engine on each node.
Metadata Cluster Orchestrator: Often described as the “brain” of the TiDB cluster, this orchestrator manages crucial metadata. It maintains the real-time topology of the cluster, tracks the location of each Region replica on the row store nodes, and allocates globally unique, monotonically increasing timestamps (TSO) for distributed transactions. Critically, this orchestrator actively monitors the state of row store nodes (load, storage usage). It also orchestrates data movement by issuing scheduling commands to split Regions that grow too large, merging small or inactive Regions, and migrating Region replicas between row store nodes. This orchestration ensures even load distribution and handles node additions/removals or failures. This active orchestration is the key to TiDB’s automated scaling and self-healing capabilities. This orchestrator is deployed as a cluster (typically 3 or 5 nodes) using Raft for its own high availability, and orchestrator followers can handle read requests for Region information to reduce load on the leader.
Columnar Store (Optional): This component provides a columnar storage replica of row store data, optimized for fast analytical (OLAP) queries. Columnar store nodes act as special Raft learners, receiving real-time updates from the row store Raft groups, ensuring strong data consistency between rows and the columns. Queries involving large scans or aggregations can be intelligently routed by the compute layer to the columnar store for significantly faster execution, enabling true mixed workload processing capabilities. The columnar store can also scale horizontally and independently from the row store and compute layer.
Key Mechanisms Enabling Horizontal Scaling: Auto-Scaling Databases in Practice
Several core mechanisms underpin TiDB’s horizontal scalability:
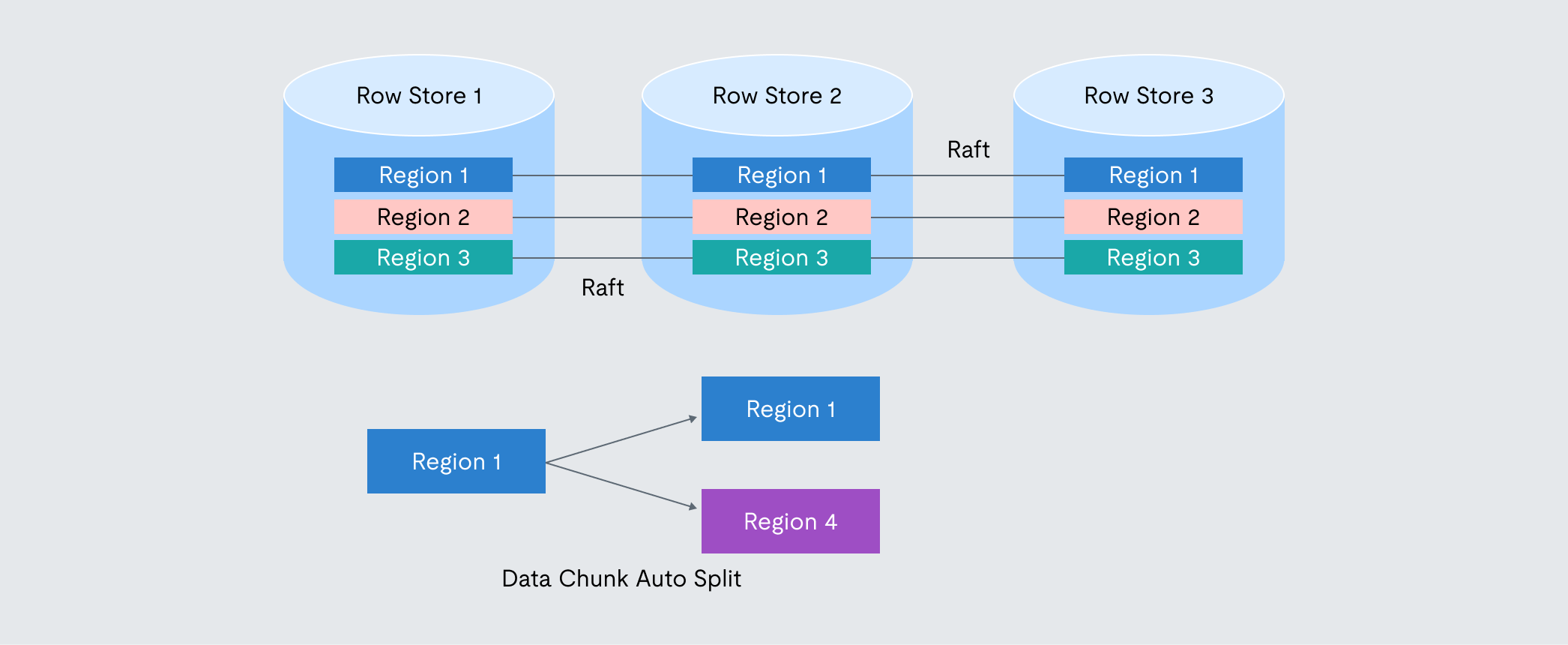
Automatic Sharding (Regions): TiDB automatically partitions table data into Regions (defaulting to around 256MB, but configurable) based on key ranges and distributes these Regions across the available row store nodes. As data is inserted or updated, the metadata and cluster orchestrator monitors Region sizes and access patterns. If a Region grows too large or becomes a “hotspot” with excessive traffic, the orchestrator automatically triggers a split operation, creating smaller Regions, and then rebalances these Regions across the cluster. This dynamic, automatic sharding and rebalancing eliminates the immense complexity and operational burden of manual database sharding required by many traditional systems.
Raft Consensus Protocol: TiDB’s row store uses the Raft algorithm to replicate each Region’s data across multiple nodes (typically 3). Raft ensures that writes are only acknowledged after being persisted on a majority of replicas, guaranteeing strong consistency (no data loss) even if a minority of replicas fail. Raft also handles automatic leader election within each Region’s replica group. If the leader node becomes unavailable, a follower is quickly elected to take over, ensuring high availability and enabling automatic failover with minimal disruption.
Figure 4. A diagram depicting how Raft consensus works in TiDB.
Automatic Load Balancing: The metadata and cluster orchestrator continuously monitors the load (CPU, storage usage, read/write traffic) on each row store node and proactively migrates Region replicas between nodes to maintain a balanced distribution. This prevents individual nodes from becoming performance bottlenecks and ensures efficient utilization of cluster resources, especially as nodes are added or removed. Load balancing can also occur at the compute layer via proxies like TiProxy. This mechanism directly supports the concept of auto-scaling databases.
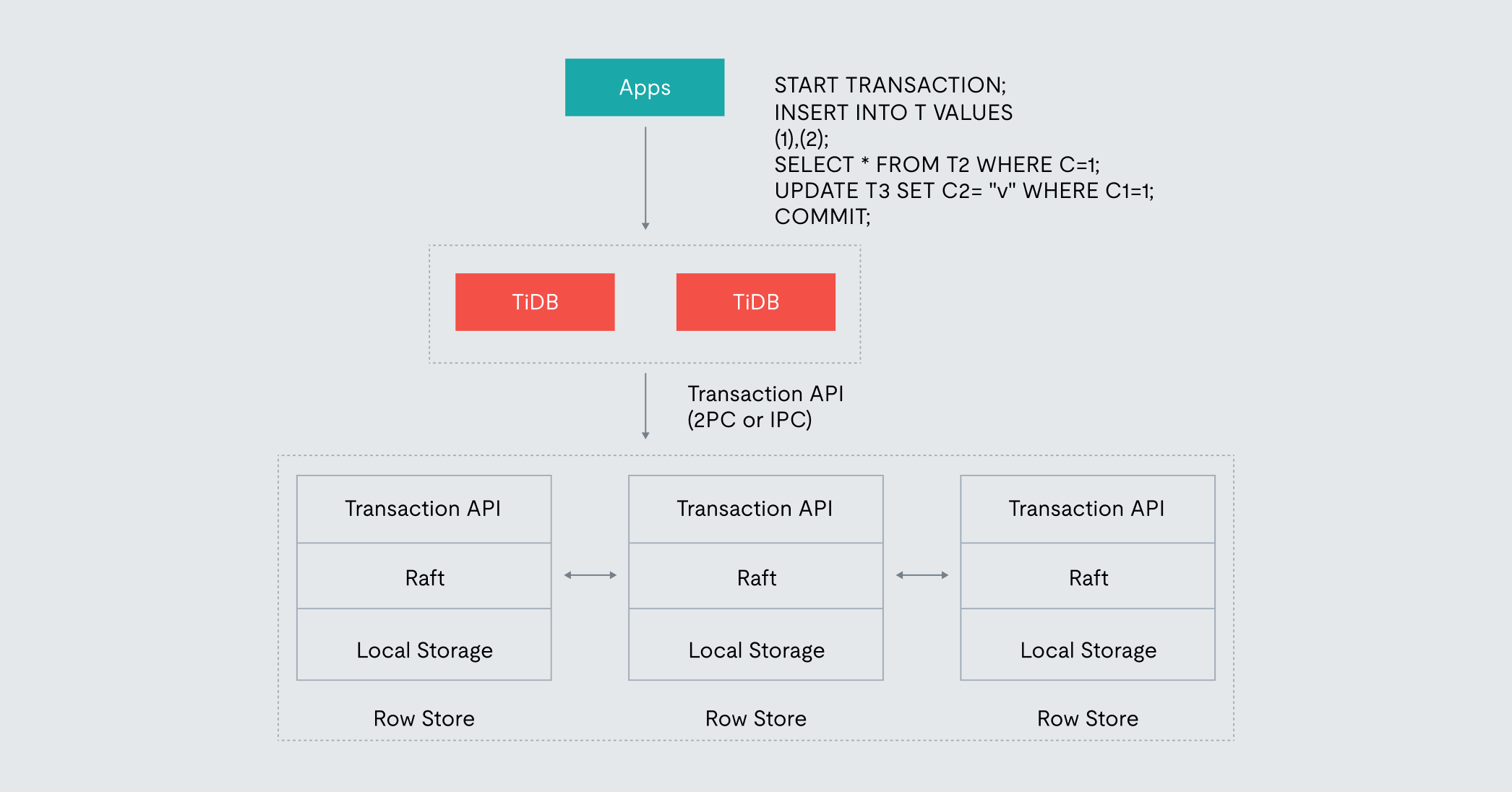
Distributed Transactions: TiDB supports ACID-compliant distributed transactions that can span multiple Regions and nodes. It employs an optimized two-phase commit (2PC) protocol, often leveraging Percolator’s model with PD-managed timestamps, to ensure atomicity and consistency across the distributed system. This complex coordination is handled transparently by the database, simplifying application development.
Figure 5. A diagram depicting how distributed transactions work in TiDB.
Addressing Scaling Limitations
Through this distributed database architecture, TiDB directly addresses the core limitations of traditional database scaling strategies:
Overcomes Vertical Limits: Horizontal scaling by adding compute layer, row store, or columnar store nodes provides a path to virtually limitless scale for compute, storage, and analytical capacity, making it a true scale out solution.
Eliminates Single Points of Failure: The distributed nature, combined with Raft replication and automated failover mechanisms orchestrated by the metadata and cluster orchestrator, ensures high availability and resilience to failures.
Simplifies Horizontal Complexity: By automating sharding (Regions), load balancing, consistency management (Raft, distributed transactions), and failover, TiDB significantly reduces the operational burden and application-level complexity associated with manual horizontal scaling strategies.
In essence, TiDB uses intelligent automation (primarily via the metadata and cluster orchestrator) and proven distributed systems principles (like Raft) to deliver the benefits of horizontal scaling without imposing the traditional complexities onto the user.
Real-World Database Scaling Strategies
Not every system needs to scale the same way. Your database scaling strategies should match your product maturity, user base, and infrastructure goals. Below are three typical growth stages and how vertical vs. horizontal scaling fits into each.
Startup (0–1M Users): When Vertical Scaling Makes Sense
In the early stages, simplicity matters. You’re optimizing for speed of development, low operational overhead, and getting to product-market fit—not building for hyperscale. Vertical scaling (i.e., upgrading to a larger instance) often provides a faster, cheaper path to support modest workloads without the complexity of distributed database architecture.
When to use it:You’re running a monolithic application, working with relatively small datasets, and need to iterate quickly.
What to watch for: As traffic grows, latency spikes, and write throughput or memory constraints may emerge—signaling it’s time to reevaluate your database scaling strategies.
Growth Stage (1M–10M Users): Transitioning to Scale Out
As usage climbs, the limitations of vertical scaling begin to surface. You may find yourself upgrading hardware frequently or dealing with service interruptions during maintenance. It’s at this point that architectural debt compounds, and retrofitting horizontal scalability becomes harder the longer you delay.
What to consider: If you’re experiencing regular downtime during schema changes, slow failover, or region-specific latency, you’re likely hitting the boundaries of a vertically scaled system.
Best practice:Begin evaluating distributed SQL options that maintain SQL semantics but allow for future elastic growth, like TiDB.
Enterprise (10M+ Users): When Horizontal Scaling Becomes Essential
At scale, availability, elasticity, and global performance are no longer nice-to-haves—they’re mandatory. Vertical scaling maxes out fast, and infrastructure that can’t scale out forces brittle workarounds like manual sharding. This increases operational complexity and slows innovation.
What’s needed: A system that can grow with your business, automatically rebalance load, isolate workloads, and scale reads/writes across multiple regions or AZs. This is where auto-scaling databases become invaluable.
How TiDB helps: TiDB provides built-in horizontal scalability, strong consistency, and MySQL compatibility—eliminating the need for custom sharding logic while future-proofing your stack. Its distributed database architecture is designed to handle these demands effortlessly.
TiDB in Action: Real-World Use Cases and Success Stories
TiDB delivers tangible benefits across demanding industries facing scaling challenges.
Target Industries & Scenarios
SaaS High-Growth Tech: Provides elastic scalability, high availability, and simplified operations compared to manual sharding. MySQL compatibility aids migration.
Financial Services Fintech: Meets high demands for consistency, reliability, and availability for payments and core systems. Offers financial-grade high availability, ACID compliance, and horizontal scaling. Mixed workload processing aids real-time fraud detection. Plaid migrated from Aurora due to write bottlenecks, seeking a more robust distributed database architecture.
E-commerce: Handles massive concurrent traffic, especially during peaks, with horizontal scaling and strong consistency for orders/inventory. Mixed workload processing enables real-time analytics.
Gaming: Manages unpredictable loads, low latency needs, and vast player data. Horizontal scaling handles player surges; low latency ensures smooth gameplay; consistency protects player progress. Mixed workload processing allows real-time behavior analysis.
Quantifiable Benefits Across Use Cases
Cost Savings (30-80%+):Pinterest Senior Engineering Manager Lianghong Xu commented: “With HBase, we had multiple instances, and the maintenance overhead was very high. For TiDB, we’ve been operating it for over two years now, and we haven’t experienced any major production issues.” This highlights the long-term TCO benefits of a well-implemented distributed database architecture.
Performance Improvements (up to 60x-1000x): Former Catalyst CTO Sha Ma said her company chose TiDB because: “We have a very diverse set of customers, so our data is more or less schemaless. We actually have wide tables with dynamic DDL formats that we’re storing — and we need that transactional level of performance to power our application. TiDB outshines all of the other database technologies we looked at in terms of performance and costs.”
Operational Efficiency: Plaid Experienced Database Reliability Engineer Zander Hill noted: “We ended up going with TiDB for a few specific characteristics. One was around being able to do upgrades with zero downtime. That’s not something we were able to previously achieve on our former hosted MySQL solution.”
Scalability Demonstrated: According to Bolt Director of Engineering Łukasz Grądzki: “TiDB scales much more seamlessly than our previous MySQL database. It requires much less effort from our engineers to scale up or scale down our clusters, depending on how the business goes. As it scales very well horizontally, it also gives us more time to redesign and improve our overall architecture.”
These successes show TiDB delivers scalability, performance, availability, and operational simplicity, making it compelling for organizations outgrowing traditional databases.
See how companies across SaaS, FinTech, and E-commerce scale effortlessly with TiDB.
Adopting TiDB: Shifts complexity to deploying/configuring the cluster. TiDB automates sharding, balancing, and consistency. Effort involves understanding architecture, choosing deployment, and migrating data (eased by MySQL compatibility). This streamlined approach is a key benefit of a well-designed distributed database architecture.
TiDB Deployment Options
TiDB Self-Managed: Deploy on your own infrastructure (on-prem/cloud VMs). Maximum control, full operational responsibility.
Using TiUP: Command-line tool simplifying deployment, scaling, upgrades for self-managed clusters.
Using TiDB Operator on Kubernetes: Recommended for containerized environments (EKS, GKE, AKS, etc.). Automates full lifecycle management (deployment, scaling, upgrades, backup, failover) via Kubernetes CRDs and controllers. Reduces operational friction for Kubernetes users.
TiDB Cloud (DBaaS): A fully-managed service offered by PingCAP, the company behind TiDB (handles infrastructure, admin, maintenance, and availability). Reduces user operational overhead. Available on AWS, GCP, and Azure.
TiDB Cloud Dedicated: Reserved resources for predictable workloads. Node-based pricing. Suitable for production; offers compliance certifications.
TiDB Cloud Starter: Usage-based pricing (Request Units + storage). Auto-scales compute/storage, scales to zero when idle. Cost-effective for variable workloads, dev/test. Includes a free tier.
Management Overhead & Operations
Vertical Scaling: Simple single-node management, but upgrade disruption remains.
TiDB Self-Managed: Reduced overhead vs. manual sharding via TiUP and TiDB Operator. Users still manage infrastructure, Kubernetes (if used), monitoring, and tuning. Requires distributed systems expertise.
TiDB Cloud: Lowest overhead. PingCAP manages infrastructure and DB admin tasks. Users can focus on application development.
The choice between TiDB Self-Managed and TiDB Cloud balances control vs. operational cost/complexity.
Total Cost of Ownership (TCO)
TCO includes infrastructure, software, labor, and downtime costs.
Vertical Scaling TCO: Can be very high due to expensive hardware, potential license fees, and downtime impact.
TiDB TCO: Aims for lower TCO.
TiDB Self-Managed: Benefits from commodity hardware/instances and open-source license. Costs driven by infrastructure and internal operations (reduced by automation).
TiDB Cloud Dedicated: Predictable node-based pricing. Compare vs. RDS/Aurora considering specs, storage, data transfer, and I/O costs. Often better price-performance for write-intensive, mixed workload processing.
TiDB Cloud Starter: Pay-for-use model can drastically cut TCO for variable workloads vs. provisioned models. Scale-to-zero eliminates idle costs. Case studies show significant savings (30-80%) vs. Aurora/RDS.
When comparing TCO, consider reduced engineering effort (vs. workarounds), consolidated mixed workloads, and managed service savings.
Choosing the Right Path for Scalable Growth: Database Scaling Strategies with TiDB
The choice between vertical and horizontal scaling involves a trade-off between initial simplicity and long-term capability. Vertical scaling is straightforward but hits hard limits, requires downtime, creates single points of failure, and becomes costly. Horizontal scaling offers limitless potential and high availability but traditionally involves significant complexity.
TiDB bridges this gap, providing the benefits of horizontal scaling (scale up vs. scale out elasticity, fault tolerance, performance) while mitigating complexity through its intelligent distributed database architecture and automation (automatic sharding, load balancing, Raft consensus). Its MySQL compatibility eases adoption, and its mixed workload processing capability simplifies architecture and enables real-time insights.
Choosing a scalable, cloud-native solution like TiDB is a strategic investment in future-proofing data infrastructure, avoiding the limitations of vertical scaling and the burdens of manual horizontal scaling. Its proven success across demanding industries makes it a compelling option for any organization implementing Cloud database scaling or leveraging Auto-scaling databases for data-intensive applications.
To evaluate TiDB, sign up for a free trial to enjoy a hands-on, managed experience — and build a resilient, high-performing foundation for rapid data growth.
Yes, many modern systems use a combination of horizontal and vertical scaling. Typically, businesses start by vertically scaling servers until reaching cost or performance limits, then move to horizontal scaling to handle additional growth efficiently. Combining both database scaling strategies offers flexibility and optimizes resource usage based on workload needs.
Vertical scaling has physical and financial limits. High-end servers become increasingly expensive, and downtime is often required for upgrades. Additionally, a single point of failure risk remains, meaning if one powerful machine goes down, the entire system may be impacted.
Horizontal scaling is ideal for cloud-native applications because it allows organizations to add or remove resources dynamically based on demand. This approach improves availability, resilience, and cost-efficiency, especially when serving global user bases or handling unpredictable traffic patterns. This is precisely what cloud database scaling aims to achieve.
Yes, TiDB is built specifically for horizontal scalability. Its distributed database architecture enables businesses to add more nodes easily without service interruption, ensuring high availability, strong consistency, and seamless performance even as workloads grow. This makes it a leading solution for scale up vs. scale out requirements.
If your application is experiencing frequent slowdowns during traffic spikes, requires global accessibility, or faces hardware limitations with vertical upgrades, it’s a strong sign that you need horizontal scaling to ensure future growth and stability. These are common indicators that your current database scaling strategies are insufficient.
Vertical scaling often has lower initial costs but becomes exponentially more expensive as you reach high-end hardware limits. Horizontal scaling requires higher upfront investment but offers better long-term cost efficiency through commodity hardware usage and linear cost scaling. The total cost of ownership (TCO) typically favors horizontal scaling for growing applications. This is a core consideration in database scaling strategies.
Traditional SQL databases struggle with horizontal scaling due to ACID compliance requirements, complex join operations across distributed data, and monolithic architecture designed for single-node operation. These databases rely on strong consistency models that are difficult to maintain across multiple nodes. Modern distributed SQL databases like TiDB solve this by redesigning the architecture specifically for horizontal scaling while maintaining SQL compatibility and ACID guarantees.
Choose vertical scaling when you have predictable, moderate growth patterns, simple applications that can tolerate brief downtime, limited distributed systems expertise, or when your current hardware is significantly underutilized. It’s also suitable for applications with tight data consistency requirements that are difficult to distribute.
“Scaling up” (vertical scaling) means adding more power to existing machines – more CPU, RAM, or storage. “Scaling out” (horizontal scaling) means adding more machines to your resource pool. Scaling up is like upgrading your car’s engine, while scaling out is like adding more cars to your fleet.
Auto-scaling with horizontal scaling automatically adds or removes server instances based on demand metrics like CPU usage, memory consumption, or request volume. Cloud platforms and distributed databases like TiDB can automatically provision new nodes during traffic spikes and scale down during low-demand periods, optimizing both performance and costs.