


Key Takeaways
- AI agents iterating against a shared database produce three compounding failure modes: schema drift, irreproducible state, and rollback gaps. These are structural outcomes, not edge cases.
- TINE binds every agent iteration to a Git commit, a TiDB branch, and a sandbox runtime. Any prior state is precisely recoverable from that three-way pointer.
- TiDB Cloud’s Copy-on-Write branching makes branch-per-instruction practical at the iteration frequency agents actually operate at. A new branch inherits the parent’s full schema and data within minutes.
- Treat data state as a first-class revision artifact alongside code. Tools that version code without versioning the corresponding data state deliver incomplete reproducibility guarantees.
AI coding agents are no longer a novelty. From Claude Code to Cursor’s agent mode, from GitHub Copilot Workspace to OpenAI Codex, “generate an app from a prompt” demos flood developer feeds. Each one follows the same arc: a developer types a prompt, an application appears, and the audience applauds.
What those demos do not show is what happens on the third prompt, when the agent tries to rename a column, backfill historical data, and migrate a schema it partially broke on the second attempt.
That is the problem PingCAP’s research team addresses in TINE: TiDB Iterative Non-Destructive Environment for Agentic App Building, accepted to SIGMOD Companion 2026. The paper is not about making agents smarter. It is about making the infrastructure beneath them safe enough to absorb the failures that smart agents still produce.
What Breaks When an AI Agent Touches Your Database
Schema drift is not a theoretical risk. When an agent generates and executes a migration, then encounters a runtime error halfway through, the database is left in a state that is neither the old schema nor the new one. Rolling back the application code with git revert does nothing to recover the data layer. The migration already ran.
Three failure modes repeat across agentic development workflows.
Schema drift. A partial migration executes, fails, and leaves behind a schema that no version of the application expects. Subsequent agent iterations build on top of a corrupted baseline.
Irreproducible state. The agent produces a UI that looks correct. Two iterations later, no one can reconstruct which code commit, which schema version, and which runtime environment produced it. Debugging requires reconstructing history that was never recorded.
Rollback gaps. Git handles code. Nothing in a standard single-database workflow handles schema and data together. Reverting a commit does not revert the ALTER TABLE the agent ran before the commit was made.
These are not edge cases. They are the default outcome when an agent iterates quickly against a shared database.
What TINE’s Branch-per-Instruction Paradigm Does Differently
TINE treats every agent iteration as a structured unit called a Revision. Each Revision is a three-way alignment:
Revision = { Git Commit SHA, TiDB Branch ID, Sandbox Runtime ID }
This is not three independent systems loosely associated. It is a binding architectural contract. Together, the three pointers give a complete answer to the question every debugging session starts with: what code ran, against what data, in what environment?
The Code Pointer: Git Commit SHA
Every user prompt causes the agent’s code changes to commit to the task branch. The result is a complete version history of code evolution across every iteration. Any prior Revision can be checked out precisely, and the record of what changed between iterations is always available. The code pointer is the component most teams already have. The other two are what is missing.
The Data Pointer: TiDB Branch ID
This is the structural core of TINE. Revision k+1’s database branch has Revision k’s branch as its parent. Via TiDB Cloud’s Copy-on-Write technology, the new branch receives a full snapshot of the parent’s schema and data within minutes, and all subsequent changes are fully isolated. Three properties follow directly from this design.
Schema migrations on the new branch cannot corrupt the parent. A failed ALTER TABLE, a botched backfill, or a dropped column affects only the branch it ran on. The parent branch is structurally unchanged. Every Revision also carries a complete data state, not just a schema definition, which means reproducibility extends to the data itself, not just the code. The architecture additionally supports forking multiple experimental paths from any Revision, though the current prototype uses a linear chain.
The Execution Pointer: Sandbox Runtime ID
TINE uses Vercel Sandbox as the agent’s execution environment. Each Revision corresponds to an independent sandbox instance running Node 24, handling code generation, dependency installation, migration execution, test runs, and preview serving. The sandbox ID closes the attribution loop: if two Revisions use identical code and an identical database branch but different sandboxes, any behavioral difference has exactly one place to look.
The combined guarantee: for any UI state, the Revision triple answers three questions simultaneously. No inference, no log reconstruction, no “I think it was the run from last Wednesday.”
The branch-per-instruction design means that Revision k+1 receives a Copy-on-Write snapshot of Revision k’s database branch as its starting point. If the agent’s migration fails, the failure is contained to the new branch. The paper’s definition of “non-destructive” is precise: TINE never modifies the database state connected to a prior Revision. That guarantee is structural, not procedural.
TiDB Cloud’s Copy-on-Write branching makes this practical at the iteration frequency agents actually operate at. A new branch inherits the parent’s full schema and data within minutes, at no performance cost to the parent cluster. If branch creation required hours, the paradigm would not survive contact with an agent that generates a new iteration every few minutes.
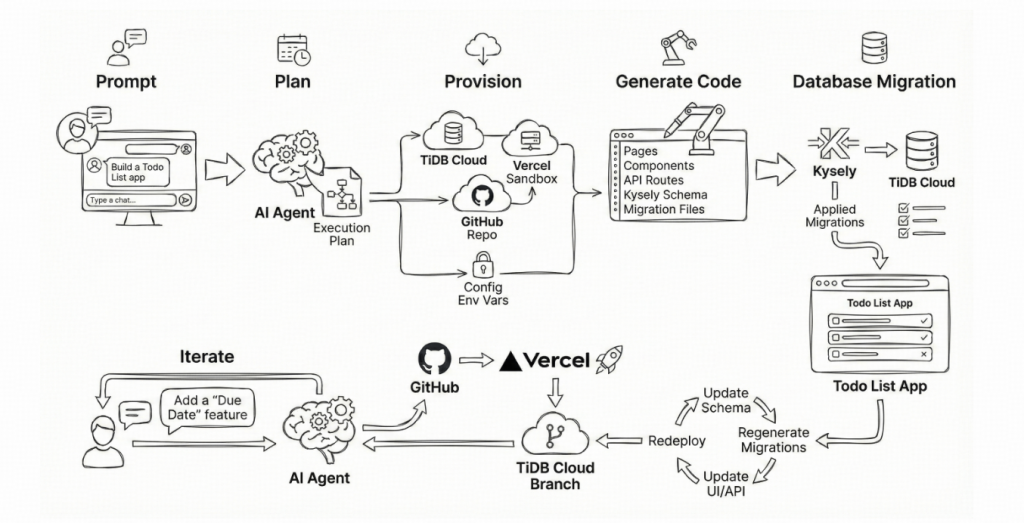
Fig. 1: The TINE development loop, from prompt to deployed application, with each iteration creating a new TiDB Cloud branch.
How the Three Demo Scenarios Map to Real Engineering Problems
The SIGMOD 2026 demo runs three scenarios. Each one surfaces a distinct failure mode that practitioners encounter in production.
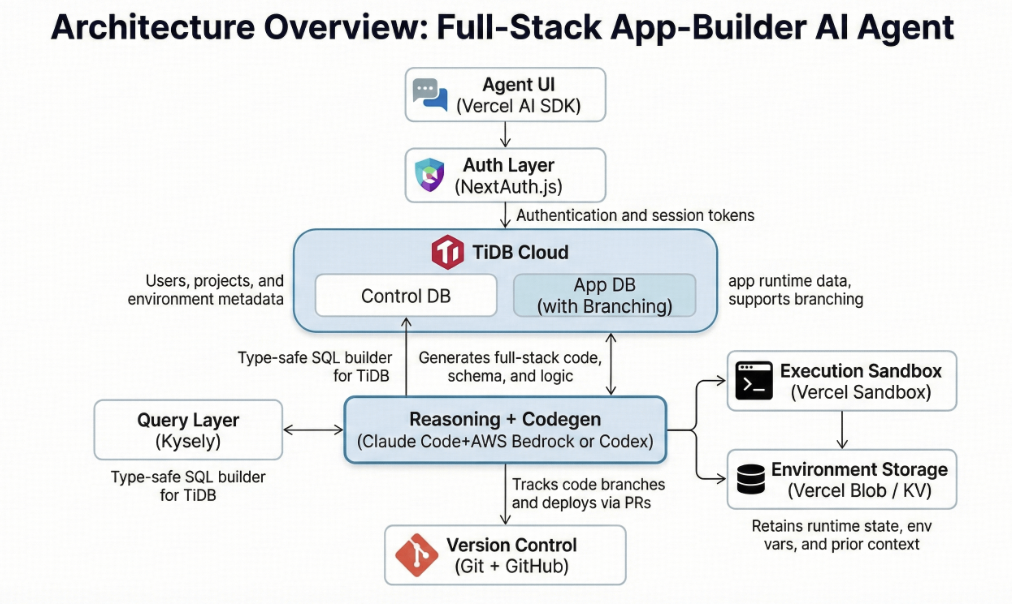
Fig 2: TINE full-stack architecture. TiDB Cloud hosts both the control database and the branched application database at the centre of the system.
- Iterative development. Starting from a data curation dashboard, the agent adds per-user access controls and an audit log table across successive prompts. The Checkpoint Selector lets the developer switch between any prior Revision, with each preview connected to its corresponding database branch. The developer can verify exactly which schema state produced each UI state. This is the core loop.
- Failure recovery. When a Vercel deployment enters an error state, TINE packages the build log as a new Revision Prompt and launches a fresh sandbox. The repair attempt becomes Revision k+2. It carries its own commit, its own branch, and its own sandbox. Fixing an error is not an out-of-band operation in TINE; it is another entry in the versioned history.
Schema rollback. When a schema refactor fails and the agent needs to restart from the previous state, TINE restores the agent’s conversation history from Blob Storage, checks out the prior commit, and applies new changes from that baseline. The developer retains conversation continuity. The execution environment is reset to a clean branch. Neither is sacrificed for the other.
Where TINE Sits in the Agent-First Database Research Landscape
UC Berkeley’s 2025 paper Supporting Our AI Overlords: Redesigning Data Systems to be Agent-First argued that LLM agents will become the dominant load on data systems, characterized by high-throughput speculative exploration: generating alternatives, backtracking, and refining across many rapid iterations. The paper called for data systems with cheap forking and rollback as a baseline requirement, not a premium feature.
TINE is a direct engineering response to that argument. Where the Berkeley paper articulates the requirements, TINE builds a working control plane that satisfies them. Database branching is not new. PlanetScale, Neon, and Dolt all provide branching in different forms. TINE’s contribution is specific: it binds the database branch to the code commit and the execution sandbox, elevating the branch from a DevOps tool to a development primitive with typed semantics.
Here’s the comparison that matters most for practitioners:
| Property | Single shared database | TINE Branch-per-Instruction |
|---|---|---|
| Schema isolation | All iterations share one schema; a failed migration contaminates subsequent work | Each iteration runs against its own branch; failures are contained |
| State reproducibility | Reconstruction requires inference from partial logs | Every Revision carries a precise three-way pointer |
| Storage cost | N environments require N full data copies | Copy-on-Write physical sharing, full logical isolation |
| Rollback scope | Code only; schema and data require manual intervention | Code, schema, and data revert together per Revision |
What the Current Prototype Does Not Cover
The paper is candid about the boundaries of the current implementation. Revisions within a task form a linear, single-writer sequence. Parallel work across agents is handled by modeling it as multiple tasks, coordinated through Git outside of TINE. Branch merging is not automated; reconciling data across branches requires external governance. The reference implementation depends on TiDB Cloud for branching, Vercel for sandboxing, and GitHub for code hosting. The paper notes that these can be replaced with self-hosted equivalents, but does not validate that path at production scale.
TiDB Cloud branches also carry a default quota limit. Long-running projects need explicit branch lifecycle management: retaining milestone branches, pruning intermediate ones. That is an operational concern the paper identifies but does not solve.
The path from prototype to production runs through three areas the authors name directly: deterministic replay (locking dependencies, pinning runtimes, recording model configuration as first-class metadata), multi-agent parallelism (converting the linear Revision chain into a directed acyclic graph with merge semantics), and enterprise security controls (short-lived credentials, log redaction, sandbox egress policies).
Three Shifts That Agent-First Development Forces on Database Design
TINE is a working prototype, but the direction it points toward has implications beyond any single tool. AI agents are forcing three assumptions that have held for decades of relational database design to break simultaneously.
From Human-Query Optimization to Agent-Speculation Optimization
Traditional query optimizers are built for human behavior: precise queries, stable access patterns, transactions that succeed as the norm. Agent workloads do not look like this. They are exploratory, high-volume, and tolerant of approximate results. UC Berkeley’s paper introduced the concept of a “Probe Optimizer” designed for this pattern, and TINE’s branched isolation is the data-layer complement: infrastructure built for “many cheap requests plus frequent rollbacks” rather than “few expensive queries plus high durability per attempt.”
The practical consequence is that a database system optimized for human query precision is not automatically well-suited for the load an agent development loop generates. The optimization target has changed.
From Schema-Stability Assumption to Schema Evolution as the Norm
Traditional OLTP systems assume schemas are relatively stable and that changes flow through controlled processes: a ticket, a review, a migration window. Agentic development breaks this assumption structurally. A schema might be refactored three times in an afternoon by an agent that has no awareness of change management procedures and no incentive to slow down.
TINE converts schema evolution from a controlled exception into a normal, isolated, reversible operation. Each migration runs on a branch. If it succeeds, the branch advances. If it fails, the branch is discarded. The parent is unchanged either way. This is not a workaround for agent recklessness; it is a design that matches how agents actually operate.
From Data as Application Appendage to Data as Revision Core
In standard DevOps practice, code is a first-class artifact managed through Git. Data is a second-class artifact managed through migration scripts, loosely coupled to the code that depends on it. The two systems drift apart in exactly the situations where alignment matters most: failed deployments, rollback scenarios, debugging across environments.
TINE’s Revision triple treats data state as structurally equivalent to code state. Every Revision captures both together, bound to the same identifier. This is the prerequisite for any application lifecycle management tooling that wants to provide real reproducibility guarantees in an agentic development context. Tools that manage code versions without managing corresponding data states will produce incomplete guarantees.
The Infrastructure Debt AI Agents Are Already Accumulating
TINE is a prototype, but the problem it addresses is live. AI agents are already iterating against production databases, and the infrastructure underneath them was not designed for that workload. The three shifts the paper surfaces, speculation over precision, schema evolution as the norm, data state as a first-class revision artifact, are already underway.
TINE shows what a database layer looks like when it is built around those shifts: every iteration recoverable, every failure contained by architecture rather than procedure. TiDB Cloud’s Copy-on-Write branching is what makes that practical today.
Start building with TiDB Cloud branching today. TiDB Cloud Serverless gives you a MySQL-compatible distributed SQL cluster with branch support, free to start. No infrastructure setup required.
Start for free on TiDB Cloud →
Based on: Hao Huo, Linjie Gao, Di Wang, Prachi Ray, Jiawen Ding, Xueting Huang, Qizhi Wang. “TINE: TiDB Iterative Non-Destructive Environment for Agentic App Building.” SIGMOD Companion ’26, Bengaluru, India. DOI: https://doi.org/10.1145/3788853.3801582
Experience modern data infrastructure firsthand.



TiDB Cloud 전용
A fully-managed cloud DBaaS for predictable workloads
TiDB Cloud 스타터
A fully-managed cloud DBaaS for auto-scaling workloads