

Key Takeaways
- An agent reading from five separate data systems inherits the weakest consistency guarantee among them.
- In a payment flow, one stale read can become a double-spend, and the failure is intermittent and hard to catch.
- A unified data layer lets an agent read transactional state and semantic memory from one consistent store.
- Consolidation is a real migration, but choosing the data foundation early beats debugging consistency bugs later.
A few months ago I watched a fintech engineering team walk me through their AI agent platform. They had a transactional database for balances and ledgers, a separate vector database for semantic retrieval, a cache for session state, a document store for agent memory, and a stream processor stitching it together. Five systems. Each one is reasonable on its own. Together, they had built a consistency problem that nobody owned.
The agent they were building approved small-dollar transfers. Most of the time it worked. But under load, the balance the agent read from the cache lagged the balance in the ledger by a few hundred milliseconds. A few hundred milliseconds is nothing until an agent makes two decisions inside that window. Then it is a double-spend, and a double-spend in a payment flow is not a bug report. It is a chargeback, a compliance question, and a very uncomfortable conversation.
This is the central claim I want to make: Fintech teams operationalizing AI agents on separate, specialized data systems are accumulating a consistency debt that will come due in production at scale. The fix is not better synchronization between systems. It is fewer systems. An agent that moves money needs to read operational truth and semantic memory from the same consistent store, in the same transaction.
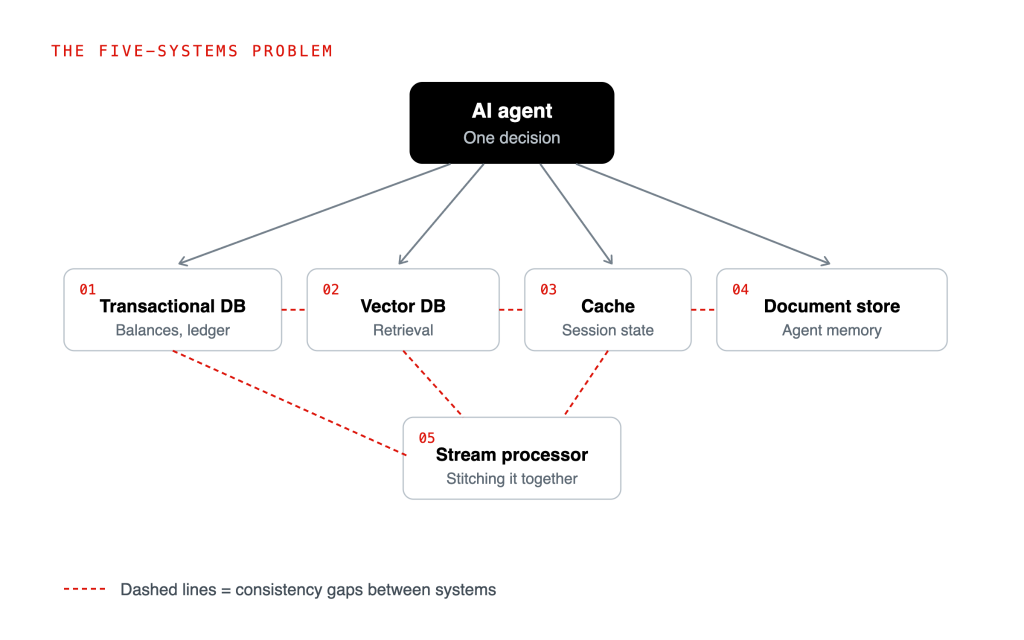
Figure 1: An agent that fuses transactional state and semantic memory inherits the weakest consistency guarantee among its data systems.
The Common Frame: Assemble Best-of-Breed, Sync Later
The standard advice for building an AI platform looks sensible. Pick the best transactional database. Add the best vector database for retrieval. Add a fast cache for session context. Wire in agent memory as its own service. Each layer is independently optimized, and the architecture diagrams look clean.
This frame is not wrong because the individual tools are bad. It is wrong because it was designed for a workload that no longer describes what fintech agents actually do. The best-of-breed model assumes the data accessed by each system is mostly independent (that your search index and your transactional records live different lives and only need to reconcile occasionally). That assumption held when retrieval was a feature bolted onto an application. It does not hold when an autonomous agent is reading vectors, checking a balance, and writing a decision inside a single reasoning step.
When the workloads were separate, eventual consistency between systems was a tolerable trade. When an agent fuses them into one decision, the gaps between your systems become the gaps in the agent’s judgment.
A Reference Architecture for a Fintech AI Agent Platform
Most useful AI platforms in fintech resolve into three layers. The first two are where the industry is investing heavily right now. The third is the one that quietly determines whether the first two work in production.
Layer 1: The AI Gateway
The gateway is the control point for every AI interaction in the platform. It handles model routing across general-purpose and finance-tuned models, enforces authentication and authorization, manages prompt and RAG-pipeline versioning, and provides the observability and audit trail that a regulated business needs. For fintech specifically, this is where you enforce the policy that a model handling KYC data behaves differently from one drafting marketing copy. The gateway answers the question “who is allowed to ask the AI what, and can we prove it later.”
Layer 2: The AI Agents
This is the layer that does the work. In fintech the agents are rarely chatbots. They are fraud-detection agents sitting in the transaction path, underwriting and credit-decisioning agents weighing risk, dispute and chargeback agents reconciling claims, and support agents that need an accurate account balance to answer a customer honestly. Some are autonomous; the higher-risk ones keep a human in the loop. They are modular, and they share two requirements: They must reason over current data, and they must remember what they did.
Agent memory is worth pausing on, because it is usually the layer teams underestimate. A useful agent carries contextual memory (the working state of the current task), procedural memory (the rules and workflows it follows), and episodic memory (a durable record of past decisions and outcomes so it can learn and personalize). In a fintech context, episodic memory is not a convenience feature. When an agent declines a loan or flags a transaction, you need a durable, queryable, auditable record of why. That record is data, and it has the same consistency and durability requirements as the ledger itself.
Layer 3: The Data Foundation
Here is where the architecture either holds or breaks. The first two layers are only as trustworthy as the data they reason over. If the agent’s context comes from five systems with five different consistency guarantees, the agent inherits the weakest one.
This is the argument for 티DB as the data layer: One engine that handles transactions, vector search, and analytical queries with distributed ACID guarantees, so an agent reads from a single source of truth instead of reconciling five. A balance check, a similarity search over transaction history, and an analytical aggregation can happen against the same consistent data, in the same SQL call. The agent’s short-term and long-term memory persist in a store that supports real-time queries and survives failure. And because TiDB is MySQL protocol compatible, fintech teams already running on MySQL or Aurora can consolidate without rewriting their applications.
The friction this removes is not abstract. It is the elimination of the synchronization layer that sat between your systems and quietly introduced the staleness that fed your agent a wrong answer.
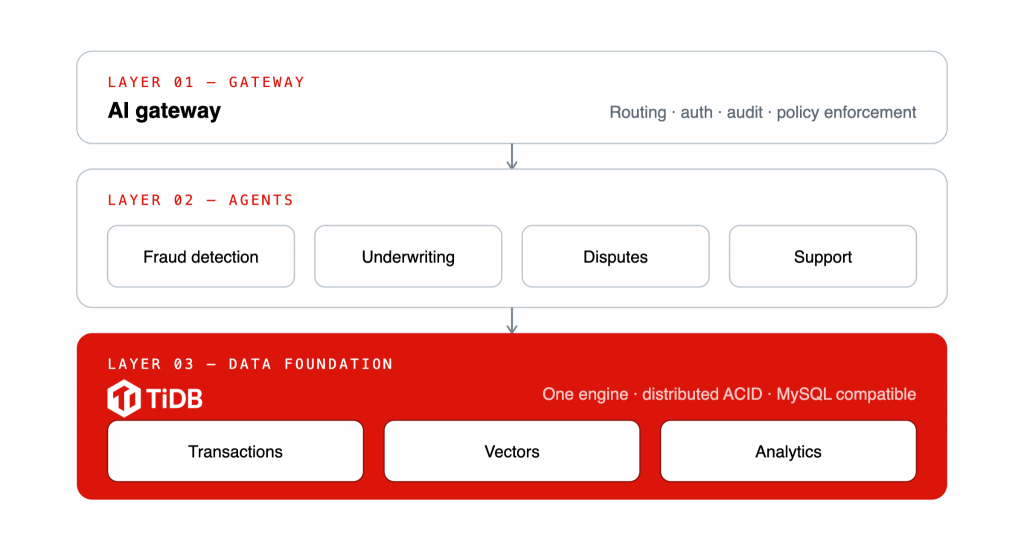
Figure 2: The first two layers are only as trustworthy as the data foundation beneath them.
Fintech AI Agent Platform: Three Architectural Patterns
Once a fintech commits to operationalizing agents, the architecture becomes a strategic choice, not just an engineering one. Three patterns are common.
- A centralized architecture routes orchestration, models, and decisioning through one shared platform. Governance, audit, and regulatory alignment get much easier. The cost is speed: Every new use case waits on a central team, and that team becomes a bottleneck.
- A decentralized architecture gives each product team control over its own agents, pipelines, and models. Teams move fast and build for their own domain. The cost is duplication and drift: Inconsistent controls, repeated work, and an enterprise-wide governance story that gets harder to tell as the company grows.
- A hybrid architecture centralizes the core services (governance, security, the shared data foundation) while letting product teams build their own agents on top. For most growing fintechs this is the practical answer, because it preserves both consistency and speed. But it only works with clear boundaries and real coordination. Without those, you get the worst of both patterns.
There is no universally correct choice. It depends on your risk appetite, your regulatory exposure, and how fast you need to ship. In practice most fintechs start centralized to contain early risk, then move toward hybrid as their use cases multiply. What I would push back on is the instinct to let the data layer decentralize along with the agents. Agents can be distributed across teams. The consistency guarantee underneath them should not be.
What a Unified Data Layer Is Not
I want to be honest about the limits of this argument, because overclaiming is how you lose an engineering audience.
A single consistent data layer does not make your agents correct. It removes one class of failure, stale and inconsistent reads, but a well-architected agent on a bad data model will still make bad decisions. Consolidation is also not free: Moving from five systems to one is a migration, and migrations have real cost even when the destination is MySQL compatible. And distributed SQL is not the right tool for every workload. If your access pattern is a pure key-value cache with no consistency requirement, a cache is still the right answer. The claim is narrower and, I think, more defensible: When an agent fuses transactional state and semantic memory into a single decision, those two things should live in the same consistent store.
The proof that this is more than theory is already in production. Plaid migrated 96 Aurora-backed services to TiDB. Manus migrated more than a million database tenants in roughly two weeks. These are fintech and AI-scale workloads where the cost of an inconsistent read is measured in money, not latency graphs.
The Decision in Front of Fintech Teams
The fintech AI platform is no longer a collection of models. It is a system that reasons, decides, and remembers, and it is only as trustworthy as the data underneath it. The three layers are real, and most teams will build all three. The question that decides whether the platform survives contact with production scale is the one teams answer last and regret first: How many data systems is your agent allowed to be wrong across?
My answer, after a decade of building distributed databases for workloads exactly like these, is one. Pick the data foundation before the architecture calcifies around the wrong number of systems. It is far cheaper to consolidate now than to debug a consistency bug in a payment flow later.
If you are building agents that touch money, see how TiDB serves as the unified data layer for AI workloads.
FAQ
Why do AI agents need a single database instead of separate specialized systems?
When an agent fuses transactional state and semantic memory into one decision, it inherits the weakest consistency guarantee among the systems it reads from. Separate systems were designed for workloads where data stays mostly independent and only reconciles occasionally. An autonomous agent reading vectors, checking a balance, and writing a decision in a single step breaks that assumption, and the synchronization gaps between systems become the gaps in the agent’s judgment.
What is the risk of using a cache and a transactional database together for a payment agent?
The cache can lag the transactional store by milliseconds. If an agent makes two decisions inside that window, it can act on a stale balance, which in a payment flow can mean a double-spend, a chargeback, or a compliance question. The failure is intermittent and load-dependent, which makes it hard to catch in testing.
Can TiDB handle both transactions and vector search in one engine?
Yes. TiDB processes transactions, vector search, and analytical queries with distributed ACID guarantees, so an agent can run a balance check, a similarity search, and an aggregation against the same consistent data in the same SQL call, rather than reconciling separate systems.
Is consolidating onto one database always the right choice?
No. A single consistent data layer removes one class of failure, but it does not make a poorly designed agent correct, and consolidation is a real migration with real cost. A pure key-value cache with no consistency requirement is still best served by a cache. The argument is specific: When an agent fuses transactional state and semantic memory into one decision, those two things should live in the same consistent store.
Does moving to TiDB require rewriting applications?
TiDB is MySQL protocol compatible, so teams already running on MySQL or Aurora can consolidate without rewriting their applications, though any consolidation across multiple systems is still a migration that should be planned and tested.
Experience modern data infrastructure firsthand.



TiDB Cloud 전용
A fully-managed cloud DBaaS for predictable workloads
TiDB Cloud 스타터
A fully-managed cloud DBaaS for auto-scaling workloads