

If you have ever tuned a distributed database, you have probably adjusted obvious knobs: CPU, memory, replication factor, concurrency limits. But there is a quieter setting, one that rarely gets headlines, that has an outsized impact on performance, reliability, and operational sanity: Raft region size.
In TiDB, via TiKV, region size refers to the size of data regions (not cloud regions like us-west-1). It determines how data is split up, replicated, moved, and recovered. It influences everything from hotspot behavior to failure blast radius. And yet, it is often misunderstood as “just a shard size.” It is not.
Region size is more like the size of the shipping containers in a global logistics network. Too small, and you drown in coordination overhead. Too large, and every move becomes slow, risky, and expensive. The sweet spot is not arbitrary. It is the result of physics, networking, and human operations colliding.
Let’s unpack it.
What is a TiKV Region? Understanding Contiguous Key Ranges
A Region in TiKV is:
- A contiguous range of keys (not rows, tables, or files)
- Managed as one Raft group
- Replicated synchronously, usually three replicas
- The smallest unit of scheduling, load balancing, failover, and snapshot transfer
A single logical table is typically split across many Regions. This applies equally to table data and index data, though the distinction is usually not important at this level.
If TiKV were a country:
- Regions are provinces
- Raft groups are provincial governments
- PD is the federal planner
- Leaders are governors
Raft Region Size Is Not a Hard Boundary
First, an important clarification. When we say “region size,” we are talking about a target, not a fixed law of nature.
In TiKV:
- Regions grow organically as data is written
- When a Region exceeds a threshold, it splits
- When adjacent Regions are too small, they merge
So region size is more like: “How big do we prefer our boxes to be?” and not “Every box must be exactly this size.”
This distinction matters because it explains why TiKV allows extreme values without rejecting them, and why the system can still fall apart if you choose badly.
The Three Forces Raft Region Size Must Balance
Every region size decision is a compromise between three competing forces.
1. Parallelism
Smaller Regions mean:
- More Raft groups
- More leaders
- More opportunities to spread load
This is like having many small checkout lanes in a grocery store. You can serve more customers in parallel as long as staffing and coordination do not collapse.
2. Overhead
Each Region incurs:
- Raft heartbeats, periodic reports from the Raft group back to PD. These are more than simple “I’m alive” messages, they include region size, leader and peer information, and scheduling statistics
- Log replication
- Metadata tracking
- Scheduling decisions
- Leader elections
Too many Regions is like running a company where every team has its own weekly executive meeting. Eventually, all you do is coordinate.
3. Recovery and Mobility
Regions are the unit of:
- Failover
- Rebalancing
- Snapshot transfer
Large Regions are heavy freight trains. Powerful, but slow to reroute when there is a derailment.
OLTP vs OLAP: Same Regions, Different Stress
These forces apply differently depending on how data is consumed. Transactional execution in TiKV and analytical execution in TiFlash place very different stresses on the same Region boundaries.
The Analytical Angle: TiFlash Considerations
Region size does not affect TiFlash in the same way it affects TiKV.
TiKV is primarily concerned with recovery, rebalancing, and failure domains. On the other hand, TiFlash is primarily concerned with scan parallelism and ingestion efficiency.
TiFlash executes analytical scans at the Region level. This means Region size directly controls the shape of OLAP parallelism.
When Regions are too small:
- Scan parallelism increases
- Replication fan out increases
- Ingestion and compaction churn increases
- Execution overhead rises due to excessive task coordination
In this case, TiFlash spends more time managing Regions than analyzing data. When Regions are too large:
- The number of concurrent scan tasks drops
- CPU utilization during analytical queries falls
- Tail latency increases because work cannot be evenly distributed
- Replica catch up after write spikes or outages becomes slower, since the unit of ingestion is Region sized
TiFlash appears underutilized and sluggish even when the cluster is otherwise healthy. For TiFlash, Region size does not define a failure boundary. It defines the granularity of analytical work. Too fine grained creates ingestion pressure. Too coarse grained limits parallelism.
The Small Region Trap (Why 1 MB Is a Terrible Idea)
On paper, tiny Regions sound appealing:
- Fine grained load distribution
- Excellent hotspot isolation
- Fast individual operations
In reality, this is what happens.
What the System Does
- Regions split constantly
- Region count explodes into the hundreds of thousands or millions
- PD tracks an ocean of metadata
- Raft groups multiply uncontrollably
What Breaks First
- PD CPU and memory
- Raft heartbeat traffic
- Leader election storms
- Scheduler thrashing
It is like replacing a fleet of cargo ships with millions of drones and then realizing each drone needs air traffic control. The system does not fail correctness. It fails coordination.
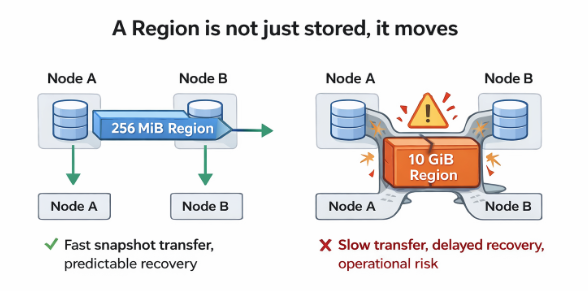
The Large Region Trap (Why 1 PB Is Even Worse)
Now swing the pendulum the other way. Set region size to something enormous, and Regions simply never split.
What the System Does
- You end up with a handful of gigantic Regions
- Each Region becomes a massive failure domain
What Breaks First
- Snapshot transfer becomes infeasible
- Rebalancing grinds to a halt
- Hotspots cannot be isolated
- Failover times balloon
Imagine evacuating a city by moving the entire population at once instead of neighborhood by neighborhood. It is not just slow. It is impossible.
Large Regions do not fail loudly. They fail silently, by making recovery impractical.
Raft Region Size Buckets: The Middle Ground
After seeing both traps, the tension is obvious:
- Small Regions give parallelism but drown you in overhead
- Large Regions reduce overhead but cripple recovery and scans
Enter Region Buckets. Buckets subdivide a Region internally for query concurrency, like adding lanes inside a highway instead of building new highways. They:
- Do not create new Regions
- Do not introduce new Raft groups
- Do not affect replication, scheduling, or failover boundaries
Operationally, this preserves predictable recovery behavior while enabling finer grained execution where it matters.
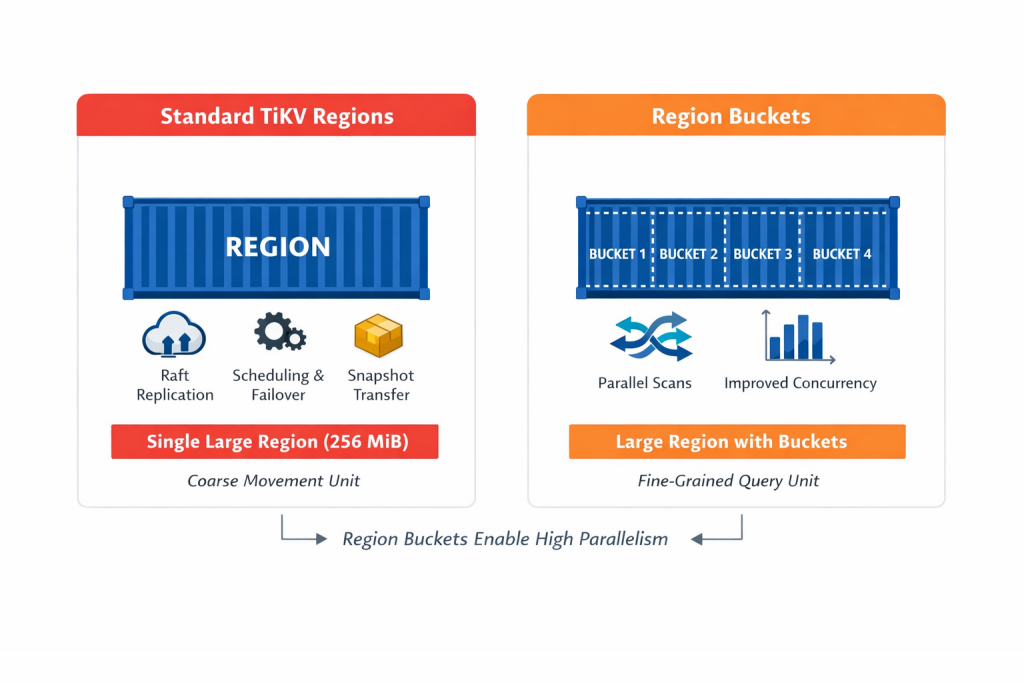
Important note: Region Buckets are currently experimental and intended for targeted, scan heavy workloads, not broad production use.
Raft Region Size: Why TiDB Landed on 256 MB
Defaults in distributed systems are battle scars.
TiDB’s default region size evolved from 96 MB to 256 MB as of 8.4.0. The recommended operating range today is roughly 48 MB to 256 MB, with 256 MB chosen as the modern default.
As hardware improved, NVMe storage, faster CPUs, and 25 or 100 GbE networks, the coordination overhead of managing many small Regions became a larger bottleneck than the cost of moving a 256 MB snapshot.
256 MB:
- Is small enough to move quickly, recover predictably, and limit blast radius
- Is large enough to avoid Region explosion, reduce Raft overhead, and keep PD sane
Think of it as the standard shipping container of TiDB:
- Optimized for ships, trucks, cranes, ports, and labor
- Not perfect for every cargo
- Good for almost all of them
How Region Size Is Configured in Practice
Region size is controlled via the following configuration:
coprocessor.region-split-size |
This determines when TiKV considers a Region “large enough” to split.
When tuning this value, there are important constraints to keep in mind:
- When TiFlash or Dumpling is used, Region size should not exceed 1 GB
- After increasing Region size, Dumpling concurrency must be reduced, or TiDB may run out of memory
This reinforces a key theme of Region sizing: larger Regions reduce coordination overhead, but they increase the cost of every operation that touches the entire Region.
The Documented Guardrails (Not Hard Limits)
TiDB intentionally avoids strict bounds. Instead, it documents safe operating zones:
Recommended: approximately 48 MB to 256 MB
Common values: 96 MB, 128 MB, 256 MB
Strong warning: above 1 GB
Explicit danger zone: above 10 GB
The philosophy is simple:
“We trust operators, but we will tell you where the cliffs are.”When Sizing Goes Wrong: Symptoms and Causes
| Symptom | Likely Cause | Why It Happens |
| High PD CPU/Memory usage and “Heartbeat Storms” | Small-Region Trap (e.g., ~1 MB) | PD must track an “ocean of metadata” and coordinate millions of individual Raft groups. |
| Leader election storms and scheduler thrashing | Small-Region Trap | Too many small “provinces” lead to excessive coordination overhead rather than productive work. |
| Snapshot transfers become infeasible or time out | Large-Region Trap (e.g., >10 GB) | Moving a massive region is like trying to move an entire city’s population at once; it’s too heavy for the “pipes.” |
| Localized hotspots that cannot be split or moved | Large-Region Trap | Because regions are the smallest unit of scheduling, a “giant” region cannot be subdivided to spread load. |
| Ballooning failover times during node outages | Large-Region Trap | Recovery becomes impractical because the unit of failover is too slow to reroute and rebuild. |
| Excessive TiFlash ingestion churn and execution overhead | Small-Region Trap | Smaller regions increase replication fan-out, forcing TiFlash to spend more time managing data than analyzing it. |
| Low TiFlash CPU utilization during scans, high tail latency on OLAP queries | Large-Region Trap | Regions are too few and too large to parallelize efficiently. |
Reducing Region Overhead Without Resizing
Increasing Region size is not the only lever. Below are additional ways to reduce overhead.
Region Merge
Adjacent small Regions can be merged to reduce total Region count and scheduling overhead.
Hibernate Region
Hibernate Region allows inactive Regions to go to sleep. If a Region is not receiving reads or writes:
- Raft heartbeats are suppressed
- Leader activity is reduced
This makes the Small Region Trap far less lethal for massive, cold datasets and especially valuable for users with “long tail” data. Think of it as turning off the lights in empty offices instead of demolishing the building.
Scaling PD with Active PD Follower
Large Region counts also pressure PD.
Active PD Follower mitigates this by:
- Keeping Region metadata synchronized in followers
- Allowing TiDB nodes to query followers directly
- Load balancing metadata requests across PD nodes
This improves scalability without changing Region semantics or consistency guarantees.
Why TiKV Allows You to Shoot Yourself in the Foot
Why not enforce strict limits? Because region size is hardware dependent, network dependent, and workload dependent. A bare metal cluster with 100 GbE behaves very differently from a cloud cluster on shared storage.
TiKV chooses policy over prohibition. The database will not stop you from doing something dangerous, but it will make the consequences unmistakable.
The Mental Model to Keep Forever
If you remember only one thing, remember this: Region size is not about storage. It is about movement.
How fast data can move:
- Between nodes
- During failures
- During rebalancing
- During growth
The best region size is the one that lets your data move as fast as your problems appear.
Final Takeaway: The Goldilocks Zone
Raft region size is the quiet governor of your entire distributed system. It sets the critical balance between throughput, recovery speed, and operational stability.
- The Small-Region Trap (Too Small): You drown in the noise of a million heartbeats. Coordination overhead collapses the system before it can do real work.
- The Large-Region Trap (Too Large): You are paralyzed by the weight of your own data. Recovery becomes impractical because your shipping containers are too heavy to move during a crisis.
- The 256 MB Modern Default: This is the “Standard Shipping Container” of TiDB. It is large enough to keep the PD “federal planner” sane , yet small enough to move quickly when a “derailment” occurs.
In distributed systems, boring is the highest compliment. By choosing the right region size, you ensure your database remains predictably resilient rather than excitingly fragile.
Don’t leave your database stability to chance. Check out our region tuning documentation to audit your current region distribution and implement the modern 256 MB default safely.
Experience modern data infrastructure firsthand.



TiDB Cloud Dedicated
A fully-managed cloud DBaaS for predictable workloads
TiDB Cloud Starter
A fully-managed cloud DBaaS for auto-scaling workloads