

Key Takeaways
- Build an AI-powered life simulator app generating realistic 6-24 month outcomes across 6 life dimensions (financial, emotional, career, health, relationships, overall).
- 6 embeddings per decision enable targeted semantic search across specific life dimensions instead of diluted generic results.
- TiDB combines vector search + SQL joins in single queries and offers database-level branching for isolated scenario exploration.
- Prompt for emotional honesty, not optimism as realistic downsides and lived experiences make AI predictions actually useful for decision-making.
For most of 2025, I found myself trapped in an exhausting loop. Every few days, I’d open ChatGPT, Claude, or Gemini and ask the same question in slightly different ways: “Should I buy a house or keep renting?”
The numbers seemed simple on the surface. My rent was $2,000 monthly. The mortgage would run around $3,500. Case closed, right? Keep renting and pocket the $1,500 difference.
But that’s not how major life decisions actually work.
What about building equity? Tax benefits? The opportunity cost of investing that $1,500 difference in index funds? And more importantly—what about the non-financial factors? The emotional security of ownership? The flexibility of renting? The stress of maintenance?
I’d copy-paste my financial details into ChatGPT, tweak one variable, and ask again. Then I’d try Claude with a different framing, then Gemini, then back to ChatGPT with updated assumptions. Each AI gave me reasonable answers, but I was essentially running the same simulation manually, hundreds of times.
After three months of this exhausting cycle, I had an epiphany: I was manually doing what an AI-powered app could do automatically.
That’s when I decided to build Parallel Lives, an AI-powered life simulation tool that generates branching timelines of your possible futures. Not fantasy 20-year projections that are impossible to plan around, but realistic 6, 12, and 24-month scenarios you can actually use.
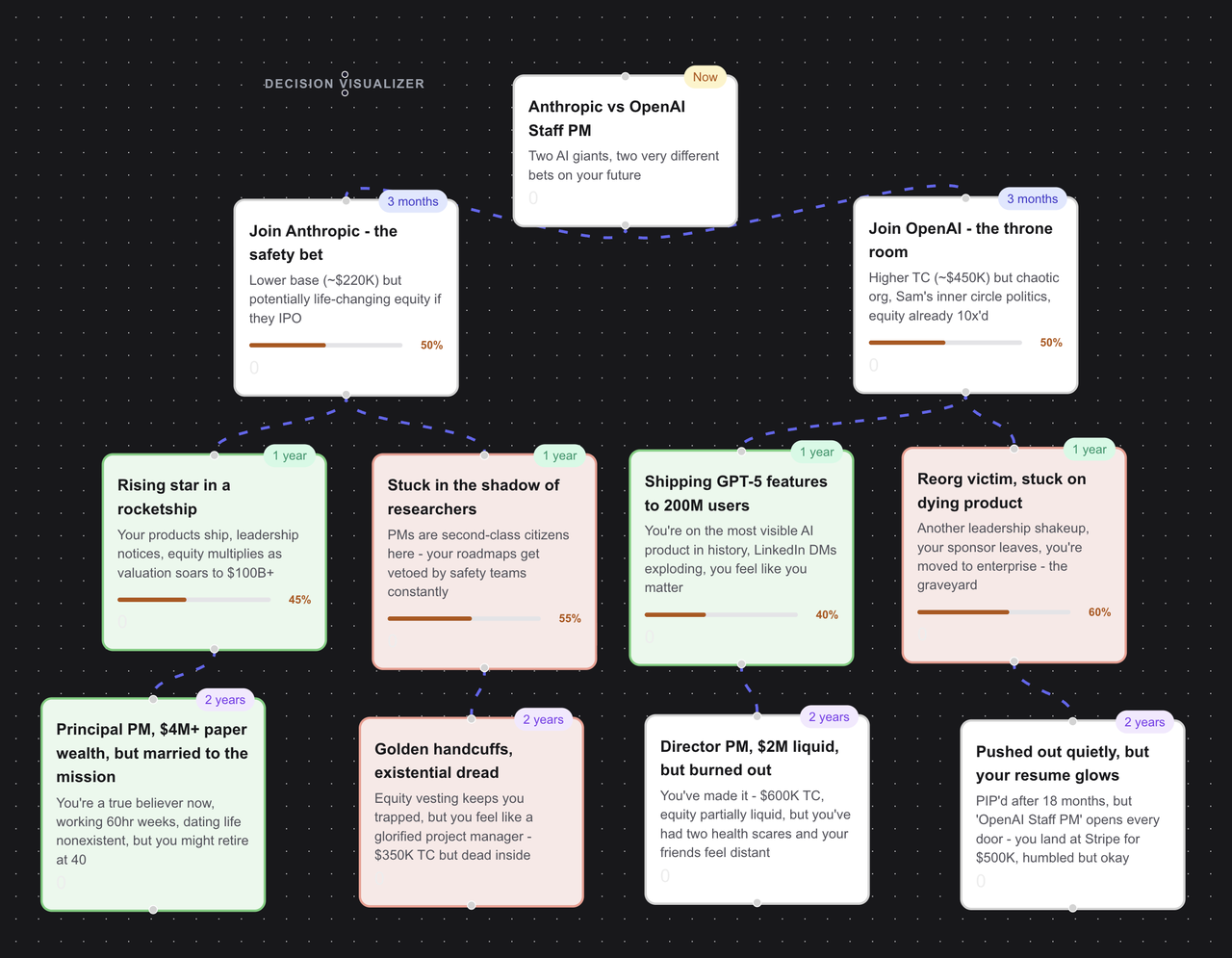
What Parallel Lives Does: An AI-Powered Life Simulator
Parallel Lives takes any major life decision and shows you how different choices might unfold across multiple dimensions—not just financially, but emotionally, professionally, and personally.
The core workflow:
- Input a decision (buy vs. rent, job offer vs. current role, relocate vs. stay).
- AI generates two initial paths with realistic outcomes.
- Click any path to explore deeper consequences.
- Create alternate branches at any decision point.
- Search across all past decisions semantically.
- Compare paths side-by-side with AI analysis.
Think of it as a decision tree visualizer powered by large language models, with each node representing not just an outcome, but a lived experience across six life dimensions.
The Technology Stack: Why I Chose These Tools
Building an AI decision simulation app requires balancing multiple capabilities: Natural language understanding, vector similarity search, relational data management, and real-time streaming. No single tool does everything perfectly, so I selected specialized solutions for each layer.
TiDB Cloud Starter: The Database Foundation for Everything
I needed a database that could handle:
- Relational data (decision trees, user sessions, branching paths).
- Vector embeddings (1,536 dimensions per node).
- Semantic search across multi-dimensional data.
- Real-time queries joining vectors and relations.
- Cost-effective scaling for unpredictable traffic.
TiDB Cloud Starter delivers all of this in one MySQL-compatible system. Instead of managing Postgres + Pinecone + Redis, I write SQL queries that join relational tables and perform vector similarity search in the same statement. This Starter tier scales to zero during idle periods, so I’m not burning money when users aren’t actively making decisions.
Claude Opus 4.5: Primary Scenario Generation Engine
Opus is the heart of Parallel Lives. When you input a decision, Opus generates branching scenarios with realistic emotional nuance. This isn’t a lookup task or simple prediction—it requires understanding context, anticipating second-order effects, and being honest about downsides.
I tried GPT-4 and Gemini 1.5 Pro first. They both generated plausible scenarios but consistently skewed too optimistic. Opus captures the messy reality of life decisions: The promotion that strains your relationship, the startup that fails but teaches you invaluable lessons, the house that builds equity but limits career flexibility.
Claude Sonnet 4: Dimensional Extraction and Structured Data
Before storing decision nodes, I need to extract summaries across six life dimensions (financial, emotional, relationship, career, health, overall). Sonnet 4 excels at this structured extraction task—faster and cheaper than Opus for cases where nuance matters less than consistency.
GPT-4o mini: Path Comparison Analysis
When users want to compare two branches side-by-side, GPT-4o mini generates the tradeoff analysis. It’s fast, cost-effective, and particularly good at weighing competing priorities in a digestible format.
OpenAI Embeddings (text-embedding-3-small): Semantic Search Foundation
Every dimensional summary gets converted into a 1,536-dimensional vector. This enables semantic search like “show me decisions that affected work-life balance” without requiring exact keyword matches.
The Data Architecture: Multi-Dimensional Decision Modeling
Here’s where Parallel Lives diverges from typical AI applications. Most apps create one embedding per document. I create six embeddings per decision node.
Why Six Dimensions Matter for Life Decisions
A major life choice doesn’t impact just one area of your life. Taking a new job affects:
- Financial: Salary, benefits, commute costs, relocation expenses.
- Emotional: Stress levels, fulfillment, anxiety, excitement.
- Relationship: Time with family/friends, romantic relationship health, professional network.
- Career: Skill development, reputation, future opportunities, trajectory.
- Health: Physical wellness, mental health, energy, burnout risk.
- Overall: The holistic picture combining all factors.
When someone asks “show me decisions that affected my relationships,” they don’t want results diluted by financial content. Targeted dimensional search beats generic embedding search.
Database Schema for Multi-Dimensional Decisions
The core data model uses three tables:
-- Stores complete decision trees
CREATE TABLE trees (
id VARCHAR(36) PRIMARY KEY,
decision TEXT NOT NULL,
tree_data JSON NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
INDEX idx_created (created_at)
);
-- Tracks user's exploration path through decisions
CREATE TABLE decision_history (
id VARCHAR(36) PRIMARY KEY,
session_id VARCHAR(36) NOT NULL,
parent_id VARCHAR(36),
decision TEXT NOT NULL,
choice_made TEXT,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
INDEX idx_session (session_id),
INDEX idx_parent (parent_id)
);
-- Stores six embeddings per decision node
CREATE TABLE decision_embeddings (
id VARCHAR(36) PRIMARY KEY,
decision_id VARCHAR(36) NOT NULL,
node_id VARCHAR(255) NOT NULL,
dimension ENUM('financial', 'emotional', 'relationship',
'career', 'health', 'overall'),
summary TEXT NOT NULL,
embedding VECTOR(1536),
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
INDEX idx_decision (decision_id),
INDEX idx_dimension (dimension),
VECTOR INDEX idx_embedding (embedding) USING HNSW
);The tree_data JSON column stores the complete branching structure, with each node containing scenario descriptions, timeframes, sentiment scores, and child nodes for further exploration.
How Data Flows Through the System
[User inputs a life decision]
↓
[Claude generates 2 initial paths with 2-year outcomes]
↓
[User clicks a path to explore further]
↓
[Claude generates next decision point + consequences]
↓
[User can branch: "what if I chose differently?"]
↓
[Extract 6-dimensional summaries from each node]
↓
[Generate embeddings, store in TiDB]
↓
[Semantic search across all past decisions]AI-Powered Life Simulator: Why Choose TiDB Cloud Starter
Most vector databases force you to choose between vector search and relational queries. TiDB Cloud Starter uniquely combines both, which unlocked three capabilities essential for decision modeling.
Multi-Dimensional Vector Indexing
Each decision node needs six separate vector indexes—one per life dimension. With Pinecone, that means six namespaces or six separate indexes. Querying “decisions affecting health and relationships” requires six API calls, then merging results in application code.
With TiDB Cloud Starter, it’s one SQL query:
SELECT * FROM decision_embeddings
WHERE dimension IN ('emotional', 'health')
AND VEC_COSINE_DISTANCE(embedding, ?) < 0.5
ORDER BY distance ASC;The database handles multi-dimension filtering natively. No client-side merging required.
Joining Vectors with Relational Data
When searching “decisions that affected my relationships,” I need to:
- Find matching embeddings in the relationship dimension.
- Join to decision_history for original decision text.
- Join to trees for full context and branching paths.
With split architecture (Pinecone + Postgres), that’s vector search, then manual joins, then result merging. With TiDB Cloud Starter, it’s one query:
SELECT
de.summary,
d.decision,
t.tree_data
FROM decision_embeddings de
JOIN decision_history d ON de.decision_id = d.id
JOIN trees t ON d.session_id = t.id
WHERE de.dimension = 'relationship'
AND VEC_COSINE_DISTANCE(de.embedding, ?) < 0.5
ORDER BY distance ASC;Vector similarity search and relational joins execute together, enabling semantic search with full context retrieval.
Database-Level Branching for Scenario Exploration
This feature made me realize TiDB Cloud Starter was purpose-built for decision modeling applications.
Parallel Lives is fundamentally about exploring alternate realities. “What if I took the job?” versus “What if I stayed?” Each path branches into more paths. Users click around, explore, backtrack, try different scenarios.
TiDB Cloud Starter’s branching API creates isolated database copies in milliseconds:
const response = await fetch(
`https://serverless.tidbapi.com/v1beta1/clusters/${clusterId}/branches`,
{
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify({
displayName: `scenario-${scenarioId}`,
parentId: clusterId
})
}
);Each branch is a complete database copy. Users can explore a decision path, generate new nodes, store embeddings, and if they want to reset or try different assumptions, the original branch remains untouched. Real isolation. Real rollback capability.
This is the same feature Manus.ai uses to let agents explore thousands of solution paths simultaneously. For Parallel Lives, it means users can branch decision trees at the database level, not just the UI level.
Bonus: Scale-to-Zero Economics
Decision-making has bursts of intense usage (when someone faces a major choice), then silence for weeks. Traditional database pricing punishes this pattern with always-on costs.
TiDB Cloud Starter scales to zero. During idle periods, I pay nothing. When a user explores decision trees, capacity spins up instantly. For a side project with unpredictable traffic, this is the difference between sustainable and prohibitively expensive.
AI-Powered Life Simulator: Making Predictions Emotionally Honest
My first attempt at scenario generation was garbage. I told Claude to “generate possible outcomes” and received pure fantasy. Every scenario worked out perfectly. No stress, relationship strain, or hidden costs. Completely useless for actual decision-making.
The breakthrough came from reframing the prompt to demand emotional honesty over optimism.
The System Prompt That Changed Everything
const SYSTEM_PROMPT = `You are simulating possible futures for a major life decision.
CRITICAL RULES:
1. Be emotionally honest. Include realistic downsides, not vague risks.
- BAD: "You might face some challenges"
- GOOD: "You'll probably feel isolated for the first 6 months. Most people do."
2. Show the lived experience, not just outcomes.
- BAD: "Your salary increases to $150k"
- GOOD: "You're making $150k but working 60-hour weeks. You've missed
three family events this quarter."
3. Preserve specific facts from the user's input.
- If they said "$120k offer" keep saying $120k, not "a good salary"
4. Different timeframes show progression, not repetition.
- 6 months: immediate adjustment period
- 1 year: patterns emerging
- 2 years: new normal established
5. Every positive has a cost. Every negative has a silver lining.
- Promotion → less time for side projects
- Startup fails → but you learned to ship fast`;The difference was transformative.
Before: “You succeed and feel fulfilled.”
After: “You close the funding round but your co-founder relationship is strained. You haven’t exercised in two months. The equity is valuable on paper, but you’re questioning whether the stress is worth it.”
This kind of nuanced prediction is what separates useful decision tools from motivational fantasy.
Domain-Specific Guidance for Different Decision Types
A job offer decision requires different considerations than housing or relocation. My first version used generic prompts for everything. The outputs were bland and similar.
Now I detect the decision type and inject domain-specific guidance:
function getScenarioGuidance(decision: string): string {
const lower = decision.toLowerCase();
if (lower.includes('job offer') || lower.includes('salary')) {
return `JOB OFFER GUIDANCE:
- Total comp matters more than base salary (equity, bonus, benefits)
- Consider: commute impact on daily energy, team culture fit, growth ceiling
- Hidden costs: relocation, lifestyle inflation, golden handcuffs`;
}
if (lower.includes('house') || lower.includes('mortgage') ||
lower.includes('rent')) {
return `HOUSING GUIDANCE:
- True cost = mortgage + property tax + insurance + maintenance
(budget 1-2% of home value/year)
- Renting isn't "throwing money away" - run the actual numbers
- Location lock-in: how does this affect job flexibility?`;
}
if (lower.includes('move') || lower.includes('relocate') ||
lower.includes('city')) {
return `RELOCATION GUIDANCE:
- Cost of living differences can erase salary gains
- Social network rebuild takes 1-2 years minimum
- Consider: weather impact on mental health, proximity to family`;
}
return ''; // Generic decision, no special guidance
}This contextual prompting dramatically improved output quality. Housing decisions now surface maintenance reserves and opportunity costs. Job offers include cultural fit and commute impact. The details people forget to consider.
Streaming Responses for Better UX
Tree generation takes 10-15 seconds with Claude Opus. That’s too long to stare at a loading spinner without feedback.
I stream the AI response so users see the decision tree building in real-time:
export async function POST(request: NextRequest) {
const { decision, mode } = await request.json();
const stream = await anthropic.messages.stream({
model: "claude-opus-4-5-20250514",
max_tokens: 4000,
system: SYSTEM_PROMPT + getScenarioGuidance(decision),
messages: [{ role: "user", content: buildPrompt(decision, mode) }]
});
return new Response(
new ReadableStream({
async start(controller) {
for await (const chunk of stream) {
if (chunk.type === 'content_block_delta') {
controller.enqueue(
new TextEncoder().encode(chunk.delta.text)
);
}
}
controller.close();
}
}),
{ headers: { 'Content-Type': 'text/plain; charset=utf-8' } }
);
}The frontend parses the stream incrementally and renders nodes as they appear. Users watch the tree grow, which creates the perception of speed even when generation takes the same time.
Semantic Search Across Past Decisions
Once you’ve explored several decisions with six-dimensional embeddings each, powerful search becomes possible:
export async function POST(request: NextRequest) {
const { query, dimensions = ['overall'], limit = 10 } = await request.json();
const queryEmbedding = await generateEmbedding(query);
const [rows] = await pool.execute(`
SELECT
de.decision_id,
de.node_id,
de.dimension,
de.summary,
d.decision as original_decision,
VEC_COSINE_DISTANCE(de.embedding, ?) as distance
FROM decision_embeddings de
JOIN decision_history d ON de.decision_id = d.id
WHERE de.dimension IN (${dimensions.map(() => '?').join(',')})
AND VEC_COSINE_DISTANCE(de.embedding, ?) < 0.5
ORDER BY distance ASC
LIMIT ?
`, [queryEmbedding, ...dimensions, queryEmbedding, limit]);
const grouped = groupByDecision(rows);
return NextResponse.json({ results: grouped });
}Example queries users can ask:
- “What decisions affected my relationships?”
- “Show me choices where I prioritized career over health”
- “Which scenarios involved financial stress?”
- “What happened when I took risks?”
The system searches the relevant dimensions across all past decision nodes and returns contextual results. It’s like having a conversation with your decision history.
Comparing Alternative Futures Side-by-Side
Sometimes you don’t need more exploration—you need clarity on two specific paths. “What’s actually the difference between buying and renting for my situation?”
The comparison feature uses GPT-4o mini with structured output:
const response = await openai.chat.completions.create({
model: "gpt-4o-mini",
response_format: { type: "json_object" },
messages: [{
role: "system",
content: `Compare these two life paths. Return JSON with:
- recommendation: "A" | "B" | "depends"
- path_a_strengths: string[]
- path_a_weaknesses: string[]
- path_b_strengths: string[]
- path_b_weaknesses: string[]
- future_voice: "A message from your future self about this choice"
- key_questions: "Questions to ask yourself before deciding"`
}, {
role: "user",
content: `Path A: ${pathA.description}\n\nPath B: ${pathB.description}`
}]
});The future_voice field generates a first-person message from a hypothetical future version of yourself who made that choice. It sounds corny, but users consistently mention it as their favorite feature. There’s something powerful about reading: “Hey, it’s you from 2 years in the future. I took the startup job. The equity never materialized, but I learned more in 18 months than I did in 5 years at BigCo. No regrets.”
AI-Powered Life Simulator: Ongoing Improvements and Known Limitations
No software is perfect, and Parallel Lives has some rough edges I’m actively working on:
Calibration Challenge: Optimism vs. Realism
How pessimistic should the predictions be? Too optimistic and the tool is useless. Too pessimistic and it creates decision paralysis.
Right now I lean toward realistic downsides because most people’s mental models are too optimistic. But some users report the app made them anxious about decisions they were excited about. That feedback is making me reconsider the balance.
Fact Preservation Issues
If a user says “I got a $150k offer with 0.5% equity,” those specific numbers need to stay consistent throughout the tree. Claude sometimes rounds (“about $150k”) or paraphrases (“a strong equity package”). I’ve added explicit preservation instructions, but it’s not 100% reliable yet.
Timeline Standardization
Currently, all scenarios use fixed timeframes: 6 months, 1 year, 2 years. But “2 years” means different things for different decisions. A startup might pivot three times in 2 years. A mortgage is a 30-year commitment.
I’m working on scenario-specific timeline generation that adjusts to the decision’s natural rhythm.
Handling Uncertainty
Some decisions have genuinely unpredictable variables (will the startup get funding? will the housing market crash?). Right now, the app shows multiple scenarios but doesn’t quantify probability. Adding probabilistic modeling would help, but risks creating false precision.
What This AI-Powered Life Simulator Taught Me About AI Decision Tools
Building Parallel Lives clarified what makes AI useful for decision-making versus what’s just theater:
What works:
- Emotional honesty over optimism.
- Multi-dimensional analysis instead of single-axis thinking.
- Short-term scenarios (6-24 months) over long-term fantasy.
- Domain-specific context (housing vs. job vs. relocation).
- Streaming UX that shows thinking process.
- Semantic search to learn from past decisions.
What doesn’t work:
- One-size-fits-all prompts.
- Pure numerical analysis without lived experience.
- Long-term projections (3+ years).
- Single embedding per decision.
- Optimistic bias that ignores downsides.
The core insight: Decisions aren’t spreadsheets. They’re stories. A good decision tool should show you lived experiences, not just cells in a table.
AI-Powered Life Simulator: Check Out Parallel Lives
Parallel Lives is built on TiDB Cloud Starter for:
- Branching decision trees with database-level isolation.
- Multi-dimensional vector embeddings (six per node).
- Semantic search across all past decisions.
- Relational joins combined with vector similarity.
- Scale-to-zero economics for unpredictable usage patterns.
All of this in one MySQL-compatible database.
Next Steps
Experience modern data infrastructure firsthand.



TiDB Cloud Dedicated
A fully-managed cloud DBaaS for predictable workloads
TiDB Cloud Starter
A fully-managed cloud DBaaS for auto-scaling workloads