

When AI workloads first started hitting production systems, many teams assumed the pressure would fall on compute. More GPUs, faster CPUs, larger memory pools — that felt like the obvious scaling path.
But that’s not what broke first.
Systems didn’t fail because they ran out of compute. They failed because they ran out of storage headroom. Query latencies spiked long before CPUs were saturated. Replication struggled to keep up. Compaction jobs spilled past their windows. Costs rose faster than performance.
AI didn’t just increase workloads. It exposed the part of database architecture least prepared for the future: storage.
This pattern has repeated across industries, signaling a fundamental shift. The strategic center of database design is moving from compute to the storage layer.
The Shift: Storage Architecture Now Determines System Advantage
For many years, improvements in compute delivered the biggest gains in database performance. That era is over.
Modern workloads are shaped by large and fast-growing datasets, multi-modal query patterns, frequent vector operations, and multi-agent AI systems generating enormous context windows. Traffic is also far less predictable, especially in consumer-facing and AI-driven applications.
Flipkart’s Big Billion Days illustrate this well. Clusters had to be scaled weeks in advance and scaled down slowly afterward. Even then, much of the cost went into preparing disks and replicas rather than compute.
This challenge is not unique. Across industries, compute is no longer the primary constraint. Storage throughput, IOPS ceilings, replication overhead, and compaction pressure surface first.
Earlier generations of distributed databases — including earlier TiDB architectures — were built on assumptions from a different era of hardware and workloads. As workloads evolved, those assumptions became limiting. Increasingly, competitive advantage depends on how deeply a system is designed around storage.
Three Lessons from Cursor’s Database Journey
This shift is clearly illustrated by Cursor’s recent infrastructure journey, shared by their CTO and co-founder in a Stanford CS 153 talk.
Lesson 1: Distributed SQL is elegant — until complexity slows you down
Cursor initially chose a Spanner-style distributed SQL system for its core indexing workload. On paper, it offered strong consistency, automatic sharding, and horizontal scalability. In practice, the team spent more time managing database behavior than shipping product, and eventually migrated the workload to a simpler managed PostgreSQL setup.
The takeaway wasn’t that distributed SQL is flawed, but that at scale, simplicity often beats theoretical elegance.
Lesson 2: Classic databases struggle with heavy, infinite-write AI workloads
PostgreSQL is a strong general-purpose database, but it remains a single-node storage engine built around MVCC and vacuum. For Cursor’s workload — constant updates, massive tables, and rapid data growth — tuning eventually hit a wall.
The sustainable fix wasn’t more optimization. It was a change in architecture. Cursor moved its largest, hottest table onto a system backed by object storage.
The lesson is clear: for modern AI workloads, classic databases eventually lose to systems built on object storage.
Lesson 3: The future data architecture is object-storage first
Over time, Cursor arrived at a modern pattern: object storage as the durable home for large data, with compute and query engines layered on top. Object storage handled durability, capacity, and cost-efficient scaling. Databases became compute services, not storage systems.
Why Object Storage Changes the Game for Databases
Object storage is often framed as low-cost storage for cold data. But when it becomes the foundation of a database, it changes system behavior much more deeply.
Object storage provides immutable data, extremely high durability, and virtually unlimited capacity. Durability moves to the storage layer instead of living in local replicas, making costs predictable and lifecycle management simpler.
Once data shifts to object storage, core database components must be rethought. Concurrency control, indexing strategy, compaction flow, caching design, recovery logic, workload isolation, and distributed execution all change. Assumptions that work for local or block storage — such as tight coupling between compute and data or replica-heavy durability — no longer apply.
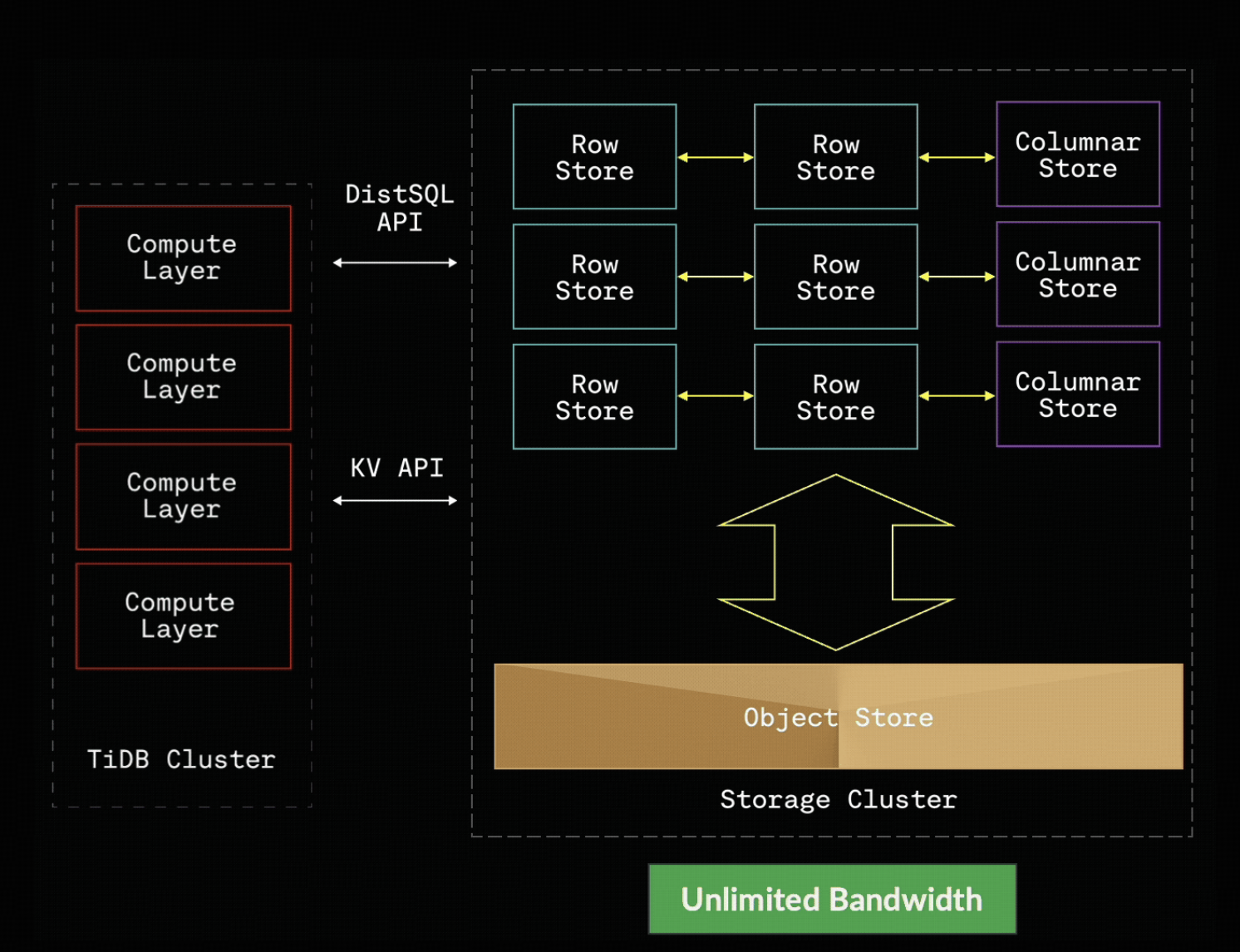
Figure 1: Decoupled compute and shared object storage enable elastic scale and unified workloads.
Because of this, object storage cannot simply be layered onto an existing architecture. To fully capture its benefits, the system must be redesigned from the ground up.
Why This Matters for TiDB
TiDB, like many distributed SQL systems, was inspired by Google Spanner and built around local disks or cloud volumes. Unlike many peers, it has been hardened at massive scale in mission-critical production environments.
But Cursor’s story highlights a deeper point: even the best Spanner-style systems still face fundamental pressure as AI workloads explode. Massive embedding stores, long-term histories, agent traces, and the need to serve OLTP, analytics, and AI retrieval over the same logical data all stress disk-centric architectures.
That’s exactly why we built TiDB X.
TiDB X: Built for an Object-Storage World
TiDB X is the latest version of our distributed SQL database designed around a simple idea: object storage is the source of truth, and databases are the compute and query layer on top.
All core data lives in object storage, providing cheap, durable, and independently scalable capacity. Compute is stateless and elastic, making hybrid workloads — OLTP, analytics, and AI — a first-class capability rather than a workaround. With pay-as-you-go economics in TiDB Cloud, teams pay for actual work done instead of idle clusters, aligning naturally with spiky, AI-driven workloads.
From One Big Database to Millions of Small Ones
AI and agentic systems push this architecture even further. Instead of one monolithic database, each agent may generate its own context store, short-lived state, or temporary vector index.
This shifts the model from one large database to millions of small, elastic, short-lived ones. That model is only viable when durability lives in object storage and compute is stateless and disposable. Without this shift, AI-era architectures quickly become cost-prohibitive and operationally fragile.
Start with TiDB Cloud, Scale Without Rewrites
If you’re building an AI coding assistant, an agentic RAG system, a multi-tenant SaaS platform, or any product with massive, fast-changing data, you face the same structural questions Cursor did.
You can follow the familiar path — start with a traditional database, hit scaling limits, migrate workloads piece by piece, and eventually rebuild around object storage.
Or you can start where that journey ends.
TiDB Cloud, powered by TiDB X, gives teams an object-storage foundation from day one: distributed SQL proven at scale, hybrid workloads in one logical system, and elastic, pay-as-you-go economics built for the AI era.
These architectural shifts are already shaping real AI systems in production. Manus, a general-purpose agentic AI platform, faced the same pressures— massive context growth, heavy write workloads, and the need to scale without re-architecting. By adopting TiDB Cloud powered by TiDB X, they turned object storage into a foundation for viral growth and large-scale agent swarms.
Find out how Manus scaled sub-second branching for thousands of agents with TiDB Cloud.
Spin up a database with 25 GiB free resources.



TiDB Cloud Dedicated
A fully-managed cloud DBaaS for predictable workloads
TiDB Cloud Starter
A fully-managed cloud DBaaS for auto-scaling workloads