EBook
The Modern, Unified GenAI Data Stack: Your AI Data Foundation Blueprint
Manus, a general purpose agentic AI platform, launched in March 2025 and went viral, amassing a two-million-plus waitlist within weeks. Its “Context Engineering” model—persisting thousands of stateful iterations per task—demanded extreme write throughput and low-latency state reconstruction that a monolithic database couldn’t sustain. The team migrated to TiDB Cloud in two weeks, leveraging distributed SQL, online change, and horizontal scale. The result: a successful public launch and a resilient data layer that now powers Manus’s “Wide Research” agent swarms and the features introduced in Manus 1.5.
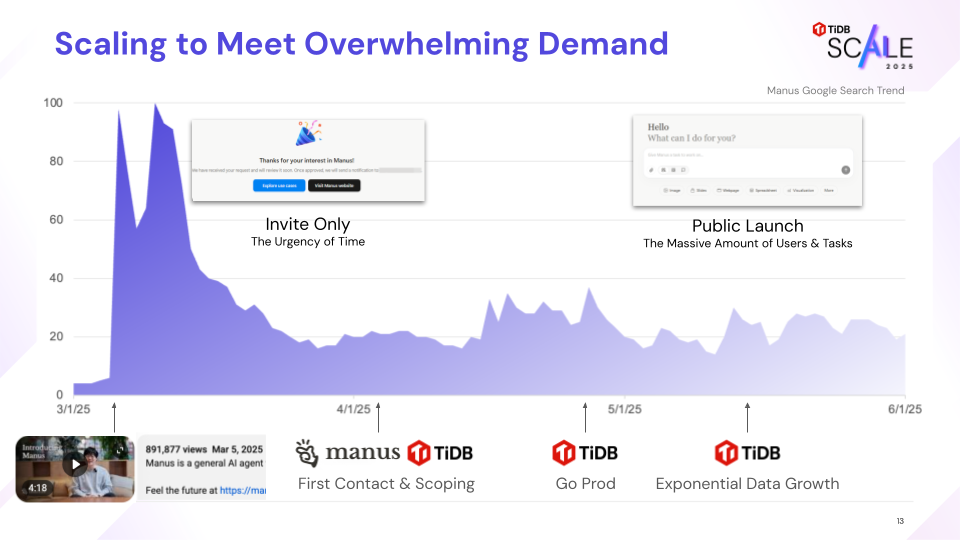
Following its March 2025 launch, Manus’s viral adoption—even under an invite-only model—demonstrated the massive market demand for general-purpose agentic AI.
This is a strategic inflection point. Manus had built something the market wanted at unprecedented scale, and now they needed infrastructure that could match their ambition. But to understand why they needed a fundamentally different database architecture, we must first examine what makes agentic AI workloads unique
To understand why Manus required a different database architecture, we must examine what makes agentic AI fundamentally different from traditional applications. The answer lies in “Context Engineering”, an industry pattern where the database becomes the agent’s cognitive foundation, not just a data store. Manus’s scale amplifies this challenge: with tasks requiring up to 15,000 iterations, their implementation pushes this pattern to its limits.
Manus’s intelligence is derived from a sophisticated “Context Engineering” framework built on top of frontier LLMs. The Manus Action Engine operates on a continuous loop of Planning, Execution, and Verification. This core cognitive process initiates a sequence of steps where each action and its resulting observation are appended to the agent’s context. This context is then persisted and used as input for the next iteration.
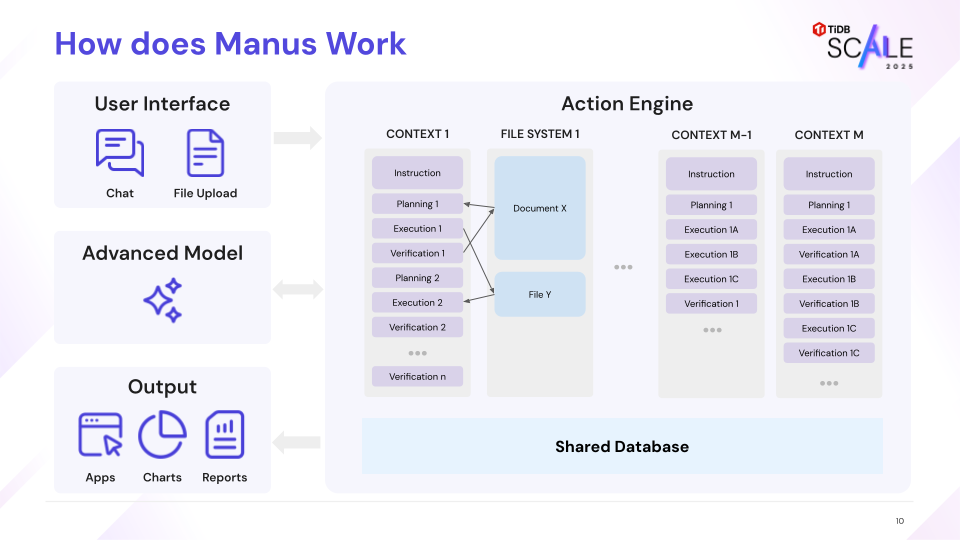
The Manus Action Engine’s core cognitive loop. Each observation is persisted to the database (acting as Long-Term Memory), forming an ever-growing context that feeds back into the next decision cycle.
A single user task can generate thousands of these iterations. As stated in Ziming Miao’s keynote at TiDB SCaiLE 2025, some complex tasks take up to “thousands of iterations to finish,” and “all this context has to go to the persistence in the data infrastructure.” This creates a massive, append-only, stateful workload where the integrity and low-latency retrievability of the entire context chain are critical for task success.
This is where traditional monolithic database architectures reach their limits. Single-instance databases are optimized for transactional workloads with predictable access patterns—not for the relentless, high-velocity context appends that each Manus agent generates, combined with the need for instant retrieval of complete context chains.
The Manus engineering team’s technical blog on “Context Engineering for AI Agents” reflects a core principle: “Use the File System as Context.” This architectural decision directly translates the challenge of long-term memory to the database. This philosophy, and the strategic choice to build on a scalable database like TiDB Cloud, is what later enabled the “Unlimited Context” feature announced in Manus 1.5. When the announcement claims users can “load huge project details without losing track of earlier data,” it is the scalability and persistence of the underlying TiDB X database—chosen months prior with foresight—that makes this possible.
Here, the role of the database undergoes a paradigm shift—from a simple system of record to the agent’s Long-Term Memory (LTM). An agent’s LTM has three fundamental requirements that demand a different architectural approach:
| LTM Requirement | Traditional Database Constraints | TiDB X Architectural Advantage |
| Vast, Scalable Capacity | Single-instance architectures have storage ceilings that require manual intervention to expand. | Decoupled computer-storage (TiDB/TiKV) allows storage to scale horizontally and near-infinitely, providing a limitless memory canvas. |
| High-Throughput, Low-Latency Access | Balancing thousands of writes per second with simultaneous reads for context reconstruction requires careful tuning. | Distributed Query Processing and Raft Consensus handle massive concurrent I/O, ensuring the LTM is not a bottleneck to the agent’s “thinking” speed. |
| Strong Consistency | An agent cannot function with corrupt or inconsistent memory—every context retrieval must be accurate. | Strong Consistency guarantees that once memory is written, it is immediately and correctly retrievable by any part of the agent swarm, ensuring coherent behavior. |
Recognizing these requirements, Manus made the strategic decision to partner with TiDB. But first, they had to execute a high-stakes database migration in just two weeks (while their waitlist continued to grow).
With their public launch scheduled and demand building, the Manus and TiDB teams collaborated on-site to execute the rapid migration. The success of this ambitious operation hinged on a combination of product features and deep partnership:
Manus shared their growth story at TiDB SCaiLE Summit 2025
The entire two-week timeline was only possible because TiDB Cloud is highly compatible with the MySQL protocol. As Ziming Miao noted in his keynote, this allowed Manus to migrate “with almost no structure changes to our code.” The team could lift-and-shift their existing schema and application logic without a costly rewrite, critical when speed was essential.
Despite careful planning, the cutover required three hours of optimization due to query plans that needed tuning for Manus’s unique state-reconstruction workload. This validated their key lesson learned: “Test your real workload, not benchmarks.” Standard TPCC benchmarks didn’t reflect the production queries that Manus agents actually generated: complex context reconstructions that required different index strategies than traditional transactional patterns.
The challenge was solved because on-site TiDB engineers were able to diagnose the issue in real-time and apply SQL bindings directly to force optimal query plans, restoring performance within minutes. As Ziming mentioned during his keynote: “We chose the hardcore approach, but it can work only if your partners can handle it. Thanks to TiDB, the team debugged with us through the night, fixing issues in minutes. That is the difference between disaster and success.”
By early May 2025, the migration was complete. Manus successfully launched to the public on May 12, 2025, and the exponential data growth that followed was absorbed seamlessly by TiDB X’s elastic architecture.
But migration solved the immediate scaling challenge. The next frontier was architectural: how could Manus enable agents to explore thousands of solution paths simultaneously without creating chaos in their shared memory?
With their infrastructure now stable and scalable on TiDB, the Manus team turned their attention to their most ambitious vision yet: agent swarms that could tackle complex problems by exploring thousands of solution paths in parallel.
Consider a real use case: a user asks an agent to “build a modern e-commerce website.” A truly intelligent agent shouldn’t just pick one approach and hope it works. Instead, it should explore multiple architectural paths simultaneously (React + Node.js, Next.js + Serverless, Vue + Python). Each exploration needs its own database tables, schemas, and test data.
Here’s the problem: If all paths write to the same database, they create chaos—conflicting schemas, corrupted test data, overwritten results. Traditional solutions like “create separate databases” don’t scale when you have thousands of agents, each exploring 5-10 paths simultaneously.
As the Manus team began prototyping agent swarms for Manus 1.5, they identified a critical infrastructure gap: traditional databases couldn’t handle the “X×Y×Z Problem”—a multiplicative scaling challenge where X tenants run Y agents, each exploring Z parallel branches.
In a traditional setup, creating isolated environments for thousands of concurrent experiments is slow and cost-prohibitive. Manus needed a database that could operate like a code repository—instantly branching state, isolating schema changes, and merging results without affecting the main production line.
Manus solved this by leveraging TiDB Cloud’s serverless architecture and Database Branching. This allows the platform to treat the database like code:
Technical Deep Dive:How does TiDB X technically achieve sub-second branching for thousands of agents? Read the full Engineering Story -> How Manus 1.5 Uses TiDB X to Let Agents Ship Full-Stack Apps at Scale
Since the public launch, Manus has successfully supported its viral growth while transforming its data layer from a scaling constraint into a driver of product innovation. By adopting a serverless, branching-capable architecture, the database has evolved from a passive store to an active participant in the agent’s cognitive loop—empowering swarms to iterate and evolve schemas autonomously. This operational agility allowed the engineering team to focus on their core AI models rather than database management, securing the foundation needed to define the next generation of software development.
Ready to Build the Next Wave of AI? Scaling agentic workloads are the defining challenges of modern AI development. Find out how leaders like Manus are solving them in our AI Use Case Gallery.
The Modern, Unified GenAI Data Stack: Your AI Data Foundation Blueprint