

Atlassian is an enterprise software company that runs one of the world’s largest SaaS platforms. Best known for Jira, Confluence, Trello, and Bitbucket, the company helps teams plan, build, and run software. As tenant counts and compliance demands grew, Atlassian hit the limits of shared and siloed multi-tenancy models on a massive sharded PostgreSQL estate.
At TiDB SCaiLE 2025, Senior Principal Software Engineer Sergey Mineyev detailed how Atlassian re-platformed Forge, its plugin ecosystem platform, to TiDB for connection scale, metadata scalability, per-tenant operations (BYOK, residency, PITR), and zero-downtime upgrades. Ultimately, the company collapsed hundreds of PostgreSQL database instances into just 16 global TiDB clusters.
In this blog, we’ll break down Atlassian’s journey to scalable multi-tenancy with TiDB. We’ll explore the key architectural choices, the consolidation to 16 global TiDB clusters, and practical takeaways for any SaaS team wrestling with multi-tenant growth.
The Challenge: Multi-Tenancy at Atlassian Scale
Atlassian’s growth introduced a uniquely hard dimension: multi-tenancy at millions of tenants, each with complex schemas (Jira alone has 800+ tables) and hundreds of third-party plugin schemas. On top of that came enterprise requirements: per-tenant BYOK encryption, data residency moves on request, strict security isolation, and per-tenant restore. The result was an ever-expanding fleet of sharded PostgreSQL clusters, complex bin-packing of tenants, heavyweight connection pooling, and constant hotspot management resulting in high cost and high operational drag.
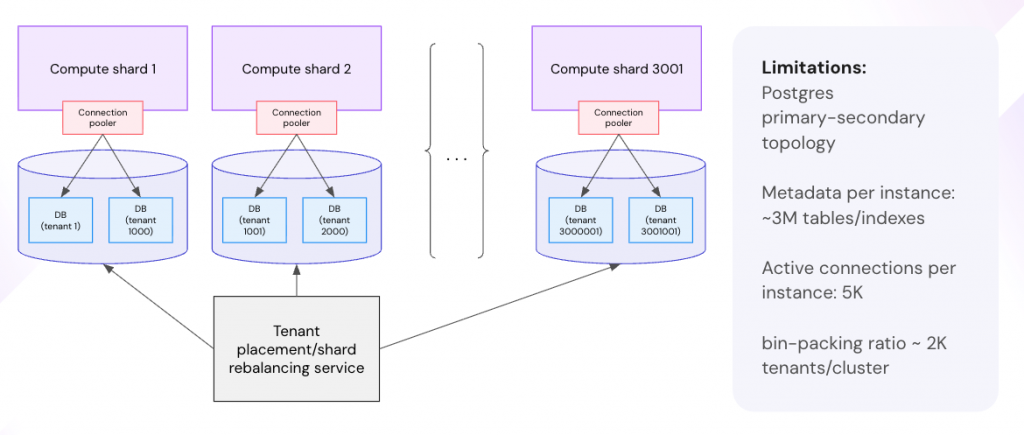
Two standard multi-tenancy models both broke down:
- Shared-schema (all tenants in the same tables) simplified operations, but made per-tenant encryption, residency moves, and workload isolation nearly impossible to guarantee within SLAs.
- Database-per-tenant made per-tenant operations easy, but created metadata explosion (hundreds of millions of objects) and connection-management limits that traditional engines (Postgres/MySQL) couldn’t sustain—leading to brittle, expensive sharding and rebalancing.
A hybrid “shared for most, silo for the top 1%” approach helped, but at Atlassian scale 1% still meant tens of thousands of databases. Again, this pushed the limits of metadata and connections.
The Goal: Collapse Instance Sprawl, Keep Per-Tenant Control
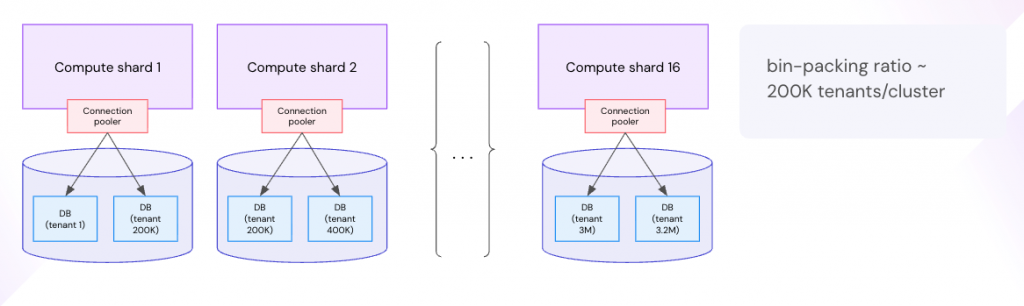
Atlassian set a clear target for its plugin platform: replace ~750+ Postgres clusters with ~16 global TiDB clusters (12 regions plus 4 regulated environments). They wanted to retire bespoke sharding and connection pooling, simplify tenant placement, and gain zero-downtime major version upgrades.
Evaluation covered multiple distributed SQL engines. According to the keynote, TiDB was the only platform that matched the bin-packing ratio and operational profile Atlassian needed.
TiDB to the Rescue! Why Distributed SQL Was the Optimal Choice
Here’s how Atlassian unlocked true multi-tenant scale without sharding: distributed SQL let them raise connection ceilings, shed metadata limits, keep per-tenant ops online, and speed up schema changes. Below are the four capabilities that made TiDB the clear choice.
1. Multi-Master SQL Compute for Massive Connections
TiDB’s stateless SQL layer allows every TiDB server to accept read/write sessions, eliminating the “single writer node” bottleneck. With tuning (e.g., token limits, memory-optimized compute types), Atlassian validated ~500,000 concurrent active connections per cluster in a region. Thread-per-connection engines often struggle to approach these kinds of numbers.
2. Horizontally Scalable Metadata
TiDB stores metadata in the stateless SQL layer and lazily caches only what active queries need. Because most tenants are inactive at any moment, this avoids loading the entire catalog and effectively removes practical metadata ceilings. Upgrades to the metadata cache and startup path cut node initialization from ~20 minutes to ~2 minutes even at extreme catalog sizes. Backup tooling and region sizing were tuned for large catalogs.
3. Per-Tenant Operations without Downtime
The database-per-tenant operating model remains, but is now feasible at scale. Per-tenant encryption, residency moves, and workload/security isolation map cleanly to a database as the unit of operation without the prior fleet sprawl and custom control planes. Major version upgrades run without downtime.
4. Schema Evolution Throughput
Atlassian’s SLO: finish schema changes across the fleet within 24 hours. TiDB’s DDL throughput increased ~6–7× (from ~1,000 DDLs/min to ~6–7k DDLs/min) and foreign-key-related slowdowns were addressed, allowing Atlassian to meet its upgrade SLOs. Further horizontal scaling of the DDL control plane is possible, but today’s throughput already cleared the critical bar.
Migration & Operations: From Complex Shards to a Simple Global Footprint
Atlassian migrated the Forge plugin platform first, historically a proving ground that stressed sharded architectures. The new design replaces hundreds of fragmented Postgres clusters with 16 TiDB clusters mapped to regions and regulated environments. The move eliminates most bespoke tenant placement and shard rebalancing logic, reduces connection-pooling complexity, and makes hotspots visible and correctable through standard TiDB controls and observability.
Operationally, the team:
- Tuned TiDB for high-connection density on the compute tier.
- Adjusted region sizing and moderated auto-splitting to manage region count as metadata scaled.
- Adopted the newer metadata cache to speed restarts/rollouts.
- Validated log/snapshot backups at scale after tool improvements for large metadata sets.
The Results: 3M+ Tables at Scale, Zero Performance Degradation
- Fleet consolidation: From hundreds of Postgres instances to ~16 TiDB clusters globally for the plugin platform.
- Connection scale: ~500k concurrent active connections per cluster validated after tuning; successfully tested with 4,000+ schemas across 3M+ tables.
- Metadata scalability: Practical removal of prior catalog ceilings; ~2-minute TiDB node initialization on the largest clusters.
- Schema velocity: DDL pipeline throughput 6–7× higher, enabling 24-hour fleet-wide schema evolution SLOs.
- No-downtime upgrades: Major version changes proceed without maintenance windows.
Atlassian also reports a dramatic improvement in bin-packing ratio, or how many tenants fit per cluster. This enables the desired consolidation and cost reductions while maintaining per-tenant operations.
What’s Next for Atlassian
With the Forge plugin platform live, Atlassian is onboarding smaller products to TiDB (e.g., Atlas, Loom, and potentially Bitbucket) while also exploring migration paths for flagship products Jira and Confluence. The long-term aim is a unified, globally consistent foundation that preserves per-tenant guarantees without re-introducing fleet sprawl.
Takeaways for Large SaaS Platform Builders
- Choose the multi-tenancy model you can operate at scale. Shared schema simplifies day one but complicates per-tenant obligations; database-per-tenant enables clean operations but demands an engine that can handle connections and metadata at extreme scale.
- Treat connections and metadata as first-class scaling dimensions. Multi-master SQL compute and lazy metadata caching change what’s operationally possible.
- Demand upgrade velocity. Schema throughput and zero-downtime upgrades are core SLOs when you operate at Atlassian’s tenant count.
As emphasized during this talk, distributed SQL at global scale isn’t just about higher QPS. It’s about making per-tenant guarantees feasible without recreating the operational cost and complexity of yesterday’s sharded architecture. This is precisely the outcome TiDB enabled in production.
Want the exact steps Atlassian-style multi-tenancy requires? Check out our multi-tenancy playbook to discover how TiDB enforces tenant isolation and kills noisy neighbors without per-tenant silos.
Webinar
Effective Multi-Tenancy: Scaling SaaS Over 1 Million Tables in a Single Cluster



TiDB Cloud Dedicated
A fully-managed cloud DBaaS for predictable workloads
TiDB Cloud Starter
A fully-managed cloud DBaaS for auto-scaling workloads