

A distributed database is any system that spreads data across multiple nodes. However, a distributed SQL database is a stricter subset: it keeps full SQL semantics and ACID transactions, automatically partitions data for horizontal scale, and uses consensus replication (e.g., Raft) so writes are consistent and failover is predictable. In short, distributed SQL gives you a relational database that behaves like a distributed system without manual sharding or fragile failover scripts. It preserves ACID transactions in a distributed SQL database even as data scales across nodes.
Today’s apps need to scale elastically, serve users in multiple regions, and stay available through failures. Distributed SQL is built just for that: scale out and in without downtime, place data close to users while respecting residency, and survive node/AZ loss with automatic leader election and quorum writes while teams keep using standard SQL.
In this blog, we’ll define core building blocks (partitioning, replication, transactions), show how distributed SQL elevates application development compared with legacy RDBMS and NoSQL options, and outline concrete advantages for real-time, cloud-native architectures.
What is a Distributed SQL Database?
A distributed SQL database is a cloud‑native database that partitions data across nodes, replicates with Raft consensus for high availability, and preserves ACID transactions at scale. At its core, distributed SQL extends the scalability, availability, and fault tolerance of traditional SQL databases, leveraging the distributed nature of the cloud or clusters.
Distributed SQL vs a Distributed Database (and vs NoSQL)
| Distributed SQL Database | Distributed Database | NoSQL Database | |
| SQL Support | Preserves full SQL semantics, including rich queries and joins. | May or may not support SQL; often drops features to simplify scale. | Typically no or limited SQL; query models vary by engine. |
| Transactions (ACID) | Full ACID transactions across nodes. | Not guaranteed; some systems weaken or drop full ACID. | Often limited or no multi-row / multi-document ACID; may offer per-key guarantees. |
| Horizontal Scale | Automatically partitions and replicates data for horizontal scale, without app-side sharding logic. | Spreads data across nodes; scaling model and guarantees differ by system. | Usually scales out well, but you often manage data modeling and consistency tradeoffs in the app. |
| Consistency Model | Uses a consensus protocol (e.g., Raft) so writes commit only when a quorum agrees; strong consistency & predictable failover. | Varies: some systems favor availability and eventual consistency. | Frequently eventually consistent; strong consistency (if available) can be limited or costly. |
| Schema & Joins | Keeps schema, joins, and relational guarantees in the database. | Some designs drop schema, joins, or other relational features. | Often schema-flexible (or schema-less) and may not support joins; denormalize instead. |
| Failover Behavior | Built-in, predictable failover thanks to consensus and replication. | Depends on implementation; may require custom scripting or ops work. | Often requires bespoke failover scripts and careful app logic. |
| App Complexity | Aims to hide distribution details, so apps can think in terms of a single SQL database. | Can push complexity (sharding, consistency, retries) into application code. | Often re-implement relational guarantees (transactions, constraints) in the app. |
Why Cloud-Native Apps Need Scalable, Fault-Tolerant Data
Cloud-native applications face three non-negotiables: elastic traffic, global users, and continuous change. Distributed SQL meets these requirements by letting you scale out and in without downtime, place data close to users to cut latency, and survive node/AZ failures with automatic leader election and replica quorums while your team keeps using standard SQL.
This matters in practice: seasonal spikes don’t require re-sharding projects, multi-region database deployments hit SLOs with locality-aware placement and follower reads, and rolling upgrades proceed online thanks to background tasks and transactional consistency. The result is a data layer that remains fast, correct, and available. This is exactly what cloud-native services need to ship features without maintenance windows or firefighting.
Distributed SQL Architecture (How it Works)
A distributed SQL database architecture is divided into two primary layers: the compute layer and the storage layer:
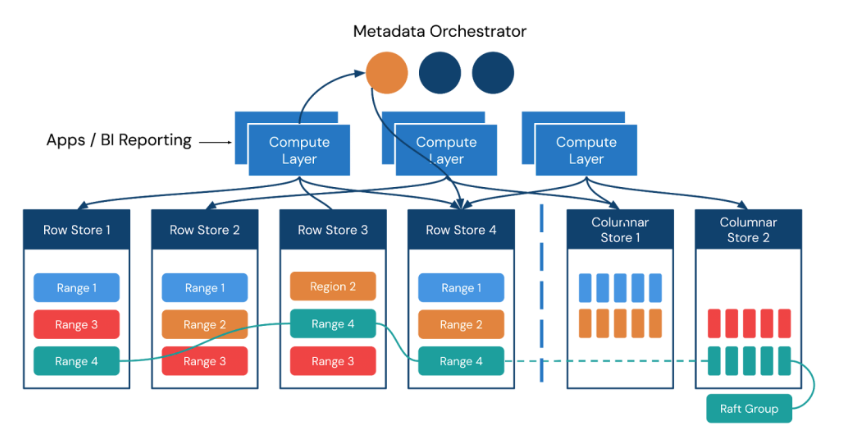
Figure 1. A typical distributed SQL data architecture.
Compute and Storage Layers
The compute layer is a stateless SQL layer that exposes the connection endpoint of the SQL protocol to the outside. The compute layer receives SQL requests, performs SQL parsing and optimization, and ultimately generates a distributed execution plan. It is horizontally scalable and provides a unified interface to the outside world through load balancing components. This layer is only for SQL computing and analyzing as well as transmitting actual data read requests to the storage layer.
The storage layer is responsible for storing data using a distributed transactional key-value storage engine. Region is the basic unit to store data. Each Region stores the data for a particular Key Range, which is a left-closed and right-open interval from StartKey to EndKey.
Multiple Regions exist in each storage node. Storage APIs provide native support to distributed transactions at the key-value pair level and support Snapshot Isolation by default. This is the core of how a distributed SQL database supports distributed transactions at the compute layer.
After processing SQL statements, the compute layer converts the SQL execution plan to an actual call to the storage layer API. Therefore, the storage layer stores the data. All storage layer data is automatically maintained in multiple replicas (three replicas by default). These replicas grant the storage layer native high availability and automatic failover capabilities.
Data Partitioning vs Database Sharding (and When Each Applies)
This section explains database sharding vs data partitioning in practice, or when the database should auto-partition ranges and when app-level sharding still makes sense.
Data partitioning is the system-managed split of a table or keyspace into ranges/regions that are automatically balanced across nodes as data and load grow. The application keeps a single logical database; the platform moves partitions, splits hot ranges, and co-locates related keys to keep latency predictable.
Database sharding is an application-managed scheme that creates many independent databases or schemas. It can work, but you own routing, re-sharding, failover, and cross-shard queries.
Here’s when you should use each:
- Data partitioning: Use for most workloads—especially multi-tenant SaaS and event-heavy systems—because it removes routing logic and rebalancing toil.
- Database sharding: Use app-level sharding only for exceptional constraints (legal isolation, hard per-tenant SLAs, or legacy boundaries), and even then aim to keep each shard internally partitioned by the database.
Database Replication and Raft Consensus for High Availability
Distributed SQL replicates each partition to multiple nodes and coordinates writes with Raft consensus (or a similar quorum protocol). A leader proposes a change, followers replicate the log entry, and writes commit when a majority acknowledges it. If the leader fails, the cluster elects a new one automatically, so clients continue with consistent reads/writes.
Why this matters:
- Predictable failover: Majority agreement prevents split-brain and protects committed data.
- Fault domains: Replicas can span zones/regions; you survive node or AZ loss.
- Read options: Followers can serve follower reads (bounded staleness) to reduce cross-region latency without sacrificing consistency guarantees for writes.
ACID Transactions at Scale (MVCC, Pessimistic vs Optimistic)
Distributed SQL preserves ACID across partitions using multi-version concurrency control (MVCC) for snapshot reads and either pessimistic or optimistic transaction modes for writes:
- Pessimistic: Locks rows on first write intent; best for high contention and long-running transactions where conflicts are costly.
- Optimistic: Proceeds without locks and validates at commit; best for low-contention, high-throughput workloads.
Planner/KV coordination ensures multi-row or multi-table operations stay transactional, with two-phase commit and per-key timestamps so readers see a consistent snapshot while writers proceed safely.
CAP Theorem Tradeoffs in Multi-Region Deployments
In the context of the CAP theorem in distributed systems, you can’t have perfect consistency and availability during a partition. Distributed SQL systems typically choose CP (Consistency + Partition tolerance) and then use placement and read strategies to keep availability and latency high:
- Locality-aware placement: Put leaders near the write path; keep quorum replicas across failure domains.
- Follower/learner reads: Serve bounded-stale reads from nearby replicas to cut cross-region RTT.
- Latency budgets: For write-heavy, globally distributed apps, consider regional write routing (per-tenant or per-key) to avoid globe-spanning quorums on every write.
The result is practical strong consistency for writes and near-local read performance, with graceful behavior during failures.
Why Distributed SQL Elevates Modern Application Development
In recent years, distributed SQL databases have emerged as a popular relational database alternative. They offer the benefits of traditional SQL and NoSQL databases. They also allow for more efficient data processing of mixed workloads and storage across multiple nodes.
Let’s explore why distributed SQL databases elevate modern application development and the advantages they offer over traditional database systems.
Elastic Scale for Unpredictable Workloads (Scalable Database)
In today’s data-driven world, organizations are generating and collecting vast amounts of data at an unprecedented rate. From user interactions to IoT devices, the volume, velocity, and variety of data are continually expanding.
As a result, businesses face the significant challenge of effectively managing and processing this ever-increasing data. Distributed SQL databases have emerged as a robust solution to address these escalating data requirements, and provide the following capabilities:
- Scalable data storage: Instead of relying on a single server, these databases distribute data across multiple nodes in a cluster. As data grows, organizations can seamlessly add new nodes to the cluster, allowing for horizontal scaling.
- Elastic computing power: Distributed SQL databases leverage the distributed nature of their architecture to distribute query execution across multiple nodes. This parallel processing capability enables organizations to leverage the combined computing power of the cluster. This results in faster query response times and improved overall system performance.
- Data compression and optimization: By compressing data, these databases reduce the storage footprint, allowing organizations to store more data within the same infrastructure.
Always-On, Fault-tolerant Database (Failure Domains, AZ/Region Awareness)
Organizations strive to deliver highly-scalable and always-on applications that provide an exceptional user experience. However, traditional database systems often struggle to keep up with the scalability and availability demands of modern applications, which require real-time responsiveness.
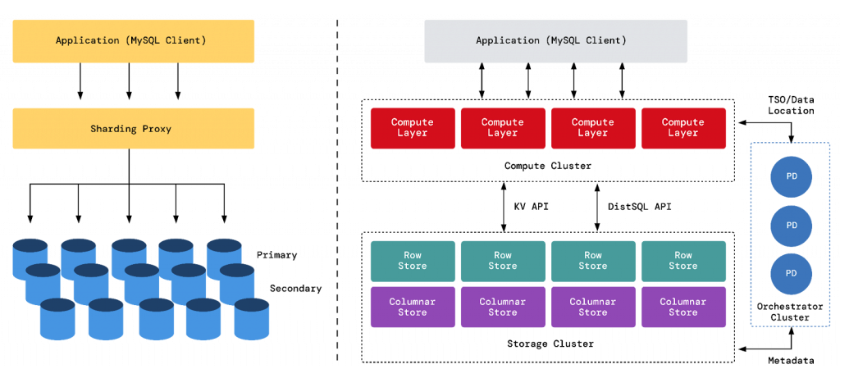
Figure 2. An example of a traditional database system that implements sharding, adding technical complexity, alongside a distributed SQL database system with Raft replication and automatic failover.
Distributed SQL databases have emerged as a powerful solution to address these challenges and significantly improve application scalability and availability. Here’s how they do it:
- Distributed query execution: By dividing query workloads across clusters, distributed SQL databases can harness the collective computational power of the nodes. This effectively reduces the response times for complex queries.
- Disaggregated storage and compute architecture: In a disaggregated storage and compute architecture, different functionalities are divided and allocated to two types of nodes: the Write Node and the Compute Node. This means you can decide the number of Write Nodes and Compute Nodes to be deployed as needed.
- Intelligent data placement: Distributed SQL databases can intelligently distribute and replicate data across data nodes in multiple availability zones (AZs), offering high availability and fault tolerance. This means if a single node or less than half of the nodes fail, the system can continue to function, a characteristic traditional monolithic databases can never achieve.
In summary, high availability is built in. Data is replicated by quorum across failure domains (nodes, AZs, regions), and leaders auto-elect on failure so writes remain consistent and service continues. Health checks, Raft timeouts, and placement policies make failover predictable, delivering an always-on posture that meets strict SLOs without custom scripts.
Simpler Stack—No Manual Sharding and Fewer Moving Parts
With distributed SQL, the database handles partitioning, rebalancing, and failover, so you retire shard routers, re-sharding jobs, and bespoke HA tooling. Cross-partition transactions, online DDL, and rolling upgrades happen inside the platform, reducing operational surface area. Fewer components means fewer incidents—and more time for feature development.
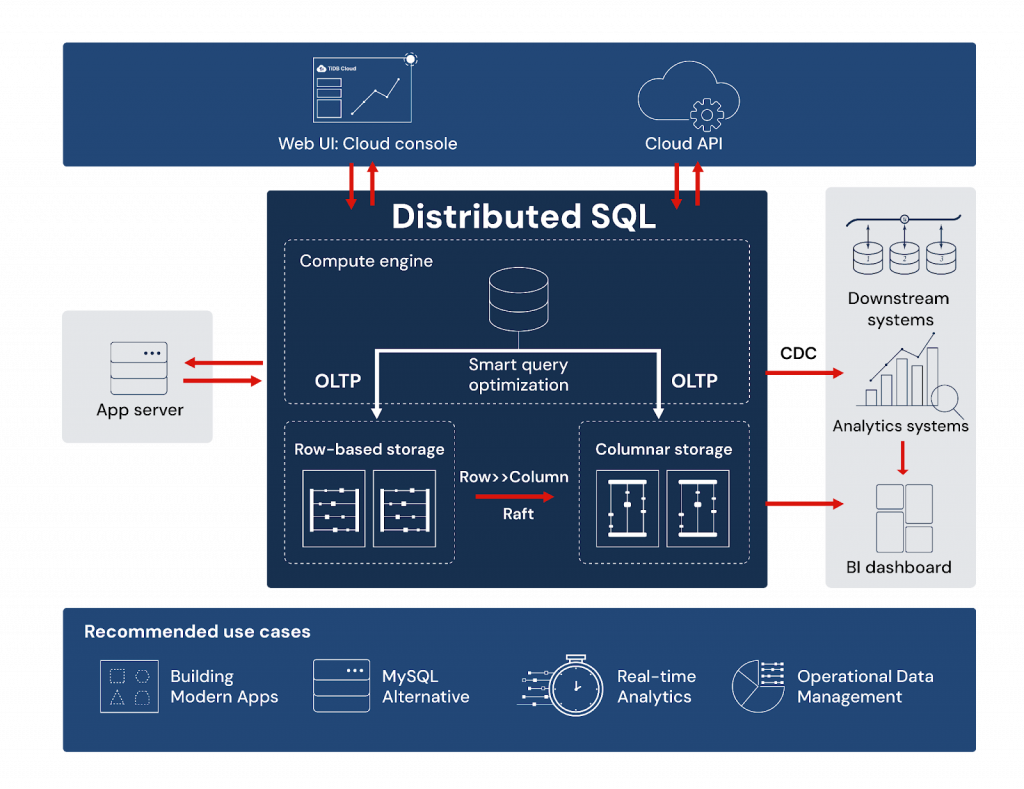
Figure 3. An example of a distributed SQL architecture with scalability and reliability for modern transactional apps coupled with real-time analytics on transactional data.
Distributed SQL databases offer a valuable solution by streamlining the tech stack jungle, simplifying the architecture, and reducing the complexity associated with data management:
- Consolidated data management: Distributed SQL databases consolidate different data management needs into a single, unified system. By consolidating data management, organizations can simplify their tech stack, reduce integration challenges, and streamline their operations.
- Integration with ecosystem tools and frameworks: These databases are designed to seamlessly integrate with popular ecosystem tools and frameworks. They provide connectors and APIs for integration with programming languages, frameworks, and data processing platforms.
- Simplified data operations: Distributed SQL databases provide built-in automation and management tools and utilize automatic rolling upgrades since they upgrade nodes one-by-one, minimizing impact to the running cluster. They also offer intuitive web-based interfaces or command-line tools that provide a unified view and control over the entire distributed database cluster.
Key Use Cases and Patterns
Here are the most common places distributed SQL delivers outsized value and the patterns that make it work in production.
SaaS Multi‑Tenant, Fintech Resilience, E‑commerce Peak Events
- SaaS multi-tenant: Pool hardware while keeping tenant isolation. Use automatic partitioning and per-tenant resource controls to prevent noisy neighbors, place hot tenants near users, and scale tiers independently without manual sharding.
- Fintech resilience: Run ACID transactions with quorum replication and predictable failover for payments, ledgers, and risk; execute online DDL and rolling upgrades during business hours to meet uptime and audit requirements.
- E-commerce peaks: Absorb flash sales and seasonality with elastic scale-out/in and locality-aware placement; keep checkout latency stable by moving heavy reads to analytical replicas and pinning write paths close to buyers.
Cloud‑Native Database Operations and Zero‑Downtime Upgrades
Operate like the rest of your Kubernetes/cloud stack: declarative changes, health-based rollout, and automated remediation. Distributed SQL supports online schema change, rolling version upgrades, and background tasks (index builds, compaction) that respect SLOs. Integrate with CI/CD to treat schema as code, add pre-flight checks (latency/lag budgets), and use backup/restore at minute-level RPO/RTO so you can ship features continuously without maintenance windows.
Implementation Checklist
Use the following checklist to turn concepts into a production-ready plan. Map keys and partitions to real workloads, set replica/quorum and leader placement, define latency budgets for multi-region topologies, and lock in the observability and failure-testing you’ll need for day-2 operations.
Partitioning Strategy, Replication/Consensus, Schema and Indexes
- Keys & access paths: Choose primary keys that align with your hottest queries (e.g., (
tenant_id,created_at)); avoid monotonic keys that create hot ranges. - Partitioning hints: Let the database auto-split ranges; add explicit partitioning only to cap region size or isolate archival data.
- Replica factor & quorum: Set RF per failure domain (e.g., 3 across AZs). Validate write latency against quorum distance; prefer odd replica counts.
- Leader placement: Pin leaders near write-heavy workloads (per-tenant/per-key locality).
- Index design: Create selective secondary indexes for hot filters; verify write amplification and storage overhead. Add covering indexes for read-mostly endpoints.
- DDL safety: Use online DDL with rate-limited backfills. Stage changes behind flags (deploy first, activate later).
Latency Budgets and Topology Design
- Budget by API: Define p50/p95/p99 targets per critical endpoint (e.g., checkout p99 ≤ 300 ms). Work backward to per-hop SLOs (DB ≤ 50% of budget).
- Read locality: Use follower/learner reads for bounded-stale queries; keep OLTP reads/writes co-located with leaders.
- Write locality: Route writes to regional leaders per tenant or shard key to avoid globe-spanning quorums.
- Data residency: Tag data/tenants with region labels; enforce placement policies and validate cross-border flows.
- Failover stance: Pre-compute secondary leader candidates per region; rehearse AZ loss and region evacuation runbooks.
- Cost/latency tradeoffs: Model the impact of extra replicas and inter-region links before rollout.
Observability, SLOs, and Failure Testing
- Golden signals: Standardize dashboards for QPS, p95/p99 latency, error rate, Raft health (leader elections, log lag), region/partition hotspots, and compaction/backfill queues.
- Tenant lens: Break out metrics by tenant/tier to detect noisy neighbors early; alert on budget breaches per tier.
- Tracing & plans: Capture slow query samples with execution plans; track plan drift after releases/DDL.
- SLOs & error budgets: Publish SLOs per API and region; tie deploy gates and throttles to remaining error budget.
- Backup & restore drills: Target minute-level RPO and hour-class RTO; test PITR and table-level restores quarterly.
- Game days: Schedule AZ-loss, leader-loss, and link-flap simulations. Verify automatic failover, client retry behavior, and that p99 remains within agreed bounds.
Getting Started with TiDB (Distributed SQL)
If you’re looking to modernize MySQL workloads with distributed SQL, start by validating scale, failover, and online DDL on a managed cluster. Selecting the right distributed SQL database to power modern applications can be challenging. However, there’s a better option that can evolve alongside your organization. Introducing TiDB, an open-source, distributed SQL database built for cloud-native, data-intensive, and AI-driven applications.
TiDB can power all of your modern applications with elastic scaling, real-time analytics, and continuous access to data. Companies using TiDB for their scale-out RDBMS and internet-scale OLTP workloads benefit from a distributed database that is:
- MySQL compatible: Enjoy the most MySQL compatible distributed SQL database on the planet. TiDB is wire compatible with MySQL 5.7. This means developers can continue to enjoy the database’s rich ecosystem of tools and frameworks.
- Horizontally scalable: TiDB grants total transparency into data workloads without manual sharding. The database’s architecture separates compute from storage to instantly scale data workloads out or in as needed.
- Highly available: TiDB guarantees auto-failover and self-healing for continuous access to data during system outages or network failures.
- Strongly consistent: TiDB maintains ACID transactions when distributing data globally.
- Mixed workload capable: A streamlined tech stack makes it easier to produce real-time analytics. TiDB’s Smart Query optimizer chooses the most efficient query execution plan, which consists of a series of operators.
- Hybrid and multi-cloud enabled: With TiDB, IT teams can deploy database clusters anywhere in the world, in public, private, and hybrid cloud environments on VMs, containers, or bare metal.
- Open source: Unlock business innovation with a distributed database that’s 100% open source under an Apache 2.0 license.
- Secure: TiDB protects data with enterprise-grade encryption both in-flight and at-rest.
Choose Deployment (Managed Cloud vs Self‑Managed)
- Managed distributed SQL database (TiDB Cloud): Fastest path to value. Get automated provisioning, scaling, backups, upgrades, and 24×7 ops, ideal for pilot projects, SaaS products, or teams that want to focus on features over infrastructure. Choose this option if you need quick validation, predictable SLOs, and minimal operational overhead.
- Self‑managed TiDB for full control: Full control on your own VMs/containers/bare metal. You own topology, security controls, and change windows, which is great for specialized networking/compliance, custom observability, or deep performance tuning. Choose this option if you have an SRE bench and strict platform constraints.
Demo, Docs, and Free Trial CTAs
- Clone a sample app: Point a real workload (or sysbench) at TiDB; verify read/write latency under burst and confirm no app code changes for MySQL compatibility.
- Deep-dive docs: Review architecture (compute/storage split, Raft), placement rules for multi-region, and Resource Groups for tenant isolation and cost control.
- Run a 10-minute validation: Spin up a free TiDB Cloud cluster and test connection density, online DDL on a large table, and a rolling upgrade/failover. Capture p95/p99 and error rates to compare against your SLOs.
FAQs
Do I still need database sharding with distributed SQL?
Generally, no. Distributed SQL handles automatic partitioning and rebalancing behind one logical database, so you don’t maintain shard routers, re-shard workflows, or cross-shard joins. You might still segment data for legal isolation or strict per-tenant SLOs, but each segment can remain internally auto-partitioned by the database.
How does Raft consensus ensure a high availability database?
Each data partition keeps multiple replicas. Writes commit only with a quorum (majority) via Raft; if the leader fails, a new leader is elected automatically, preserving consistency and continuing service without split-brain. This makes failover predictable across nodes, AZs, or regions.
Does CAP theorem mean I can’t have ACID transactions?
No. CAP applies during partitions. Distributed SQL systems typically choose CP (consistency + partition tolerance) and use locality-aware placement and follower/learner reads to keep availability and latency strong. You still get ACID transactions with practical performance for real apps.
What’s the difference between distributed SQL and a distributed database?
“Distributed database” is the broad category—many nodes, many designs. Distributed SQL is the subset that preserves full SQL + ACID with consensus replication and automatic partitioning, so you get horizontal scale and strong consistency without manual sharding or custom failover scripts.
Experience modern data infrastructure firsthand.



TiDB Cloud Dedicated
A fully-managed cloud DBaaS for predictable workloads
TiDB Cloud Starter
A fully-managed cloud DBaaS for auto-scaling workloads