

When we unveiled TiDB X, the new core engine for TiDB Cloud, at our recent TiDB SCaiLE annual event, the response was immediate and enthusiastic. Many people reached out afterward with technical and non-technical questions about where TiDB X came from, why we decided to build it, and how it connects to the future of TiDB Cloud. Instead of replying privately to everyone, we decided to write down the story — not just the architecture, but the reasoning, the missteps, and the years of evolution behind this new engine.
TiDB X did not appear suddenly. It grew out of years of building TiDB Cloud, hitting painful limits, challenging long-held assumptions, and eventually deciding that incremental thinking would not get us where the future is clearly heading. In many ways, TiDB X is a return to first principles: why we built TiDB, what customers truly value, and what scalability really means in a world reshaped by AI and cloud-native development.
Revisiting the Core Question: Why Do People Choose TiDB?
For years, one of our biggest internal challenges was the architectural fragmentation between TiDB Cloud Starter and TiDB Cloud Dedicated. While they shared the TiDB name, they diverged significantly in technology, teams, and evolution. We tried to unify them more than once, without success.
What ultimately realigned us was a simple question: why do users choose TiDB? Across countless conversations, the answer consistently came down to one word — scalability.
Not just in data volume or throughput, but across every dimension that breaks databases in practice: indexes, tenants, tables, connections, metadata, and operational complexity. Systems don’t fail at their strongest points, but at their weakest, and TiDB has proven uniquely balanced across all of them.
One example came from Atlassian, which needed to support millions of tables in a single database. The data size was modest, but the metadata demands were extreme. Competing systems failed at a few thousand tables; TiDB scaled to nearly ten million, winning the deployment. It reinforced a core truth we’ve seen repeatedly: scalability is what TiDB does best — and it’s never static.
What Happens at 10× or 100× Scale?
We’ve stretched the legacy TiDB architecture further than we once thought possible, from comfortable 100 TB clusters to stable 1+ PB clusters. But the natural next question is: What happens at 10 PB and beyond?
The honest answer is that the traditional shared-nothing architecture, built on local storage, simply cannot deliver the elasticity, cost profile, or operational dynamics required for that scale.
To survive the next decade of workloads — especially workloads shaped by AI agents generating personalized SQL, exploding long-tail use cases, and a flood of dynamic applications — a database must fully embrace two cloud principles:
- Elastic resources: true pay-as-you-go compute
- Object storage: cheap, durable, massively parallel
If today’s workloads seem manageable, history reminds us that we routinely underestimate the future. Moore’s Law is a humbling reminder: our imagination rarely keeps pace with technological reality. And the last six months of AI progress alone have made this even more obvious.
When applications can be created in minutes — when data collection is trivial — and when each user may have a personalized workload generated by an AI agent, the combination of SQL patterns, table shapes, and query paths will stress every part of a database system.
The question then becomes: How do we design a database that preserves rapid innovation while guaranteeing long-term stability and safety?
This question marks the true beginning of TiDB X.
Origins of TiDB X: The Early Technical Seeds
The earliest sign of TiDB X’s direction dates back to an April 2021 talk I gave at a CCF conference, though the idea had been forming much earlier. Around 2017, Max Liu started a small internal project to explore transaction optimizations and accelerate SQL-layer testing. At the same time, we were influenced by the WiscKey paper (FAST ’16) and BadgerDB, Dgraph’s Go implementation, which explored separating keys and values in LSM-Trees to reduce write amplification.
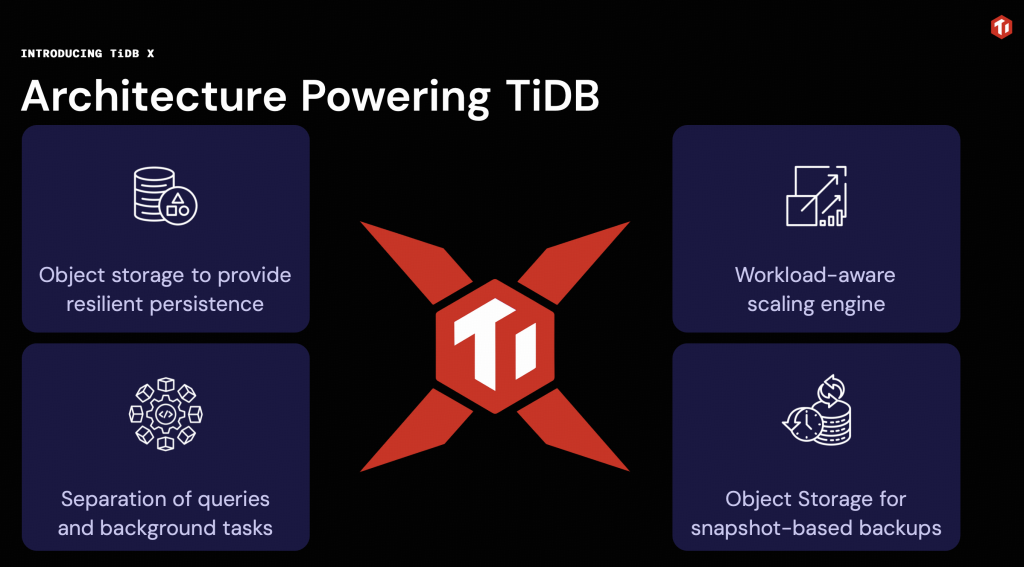
Figure 1: How TiDB X combines object storage, workload-aware scaling, and task isolation.
As Go enthusiasts, we experimented with a TiKV-compatible distributed KV store built on BadgerDB. It felt lightweight and flexible, though we later learned the hard way that this optimism was misplaced — TiDB X was eventually rewritten in Rust. Still, the prototype planted a critical idea: storage concerns could be separated more aggressively.
In parallel, Snowflake’s compute–storage separation was reshaping expectations for cloud-native data systems. While Snowflake targeted OLAP, it pushed us to ask a provocative question for OLTP: could SST files live on S3, with only caches and Raft logs kept locally? Others, like RockSet and the RocksDB team, were exploring similar directions, but within existing constraints. We wanted to go further — to build a fully serverless, cloud-native OLTP database.
The Turning Point: 2022 and the Decision to Break From Incrementalism
By 2022, we restarted the cloud-native engine project with clear, ambitious goals. They were bold enough that incremental engineering could not possibly deliver them:
- Provide a free TiDB Cloud service for developers everywhere.
- Create new clusters in seconds, fully self-service.
- Scale automatically from 0 → 100 million QPS/TPS, and shrink back to 0 just as fast.
- Support datasets from kilobytes to petabytes.
- Use only standard cloud APIs — no assumptions about special hardware or exotic configurations.
At that time, even the smallest TiDB cluster cost hundreds of dollars per month. Spinning up a cluster took minutes. Scaling large clusters could take days because workloads had to be rebalanced slowly across nodes. These constraints were not compatible with the future we envisioned.
To reach a 1,000× improvement, we needed to abandon incrementalism entirely.
A helpful analogy comes from the history of neural networks. Backpropagation existed for decades, but without enough compute, it couldn’t achieve its potential. Only when AlexNet used GPUs in 2012 did the AI boom ignite — even though GPUs had been around for years. In 2022, we realized TiDB needed its own “GPU moment.” The shared-nothing architecture had carried us far, but it had become a conceptual ceiling.
We chose to rethink everything from the ground up.
Five Architectural Principles Behind TiDB X
After many iterations, the key principles that shaped TiDB X can be summarized as follows.
1. Build a Service, Not a Database
This is the most important shift. TiDB X is not a packaged database deployed by users. It is an online, cloud-native service, whose product happens to be a SQL database (in this case, TiDB Cloud). That distinction affects everything: team structure, deployment, monitoring, multi-tenancy, scaling, upgrades, and the role of compute and storage.
This mindset led directly to the next principle.
2. Adopt a True SOA (Service-Oriented Architecture)
This service oriented architecture (SOA) gave us:
- fine-grained scalability
- high-density multi-tenancy
- cost control
- fault domain isolation
- independent evolution of components
It turned out that many of our biggest architectural leaps came not from distributed systems algorithms, but from adopting this SOA rigorously across the entire system.
3. Virtual Clusters (VCs) Instead of Physical Instances
If you want to offer free, globally accessible databases, you cannot give each user a physical instance, not even the smallest one. Most users are “cold” — they send a handful of requests per hour. They matter, but dedicating hardware to them is impossible.
TiDB X introduces Virtual Clusters: logical clusters that share compute and storage but preserve isolation through metadata and routing. VCs make it feasible to serve millions of tenants efficiently. This is also why simply replacing Postgres’s storage layer with S3, as some serverless database vendors do, is not enough. Without full vertical decomposition and service-oriented design, “serverless” remains superficial.
4. Embrace the Principle That “the Log Is the Database”
Aurora popularized this idea, and we consider it one of the most profound contributions to modern database design. When logs are the source of truth, everything else becomes reconstructible:
- NVMe and memory provide fast read caching
- SSDs excel at append-only writes
- replication gives availability and durability
- losing local state becomes cheap, because state can be rebuilt
This simplifies data structures, correctness guarantees, and the mental load for developers working on the kernel.
5. Build on TiDB’s Strengths, Especially Sharding
TiDB’s existing architecture gave us several advantages:
- The SQL layer (tidb-server) was already stateless.
- tidb-proxy, which originally supported seamless online upgrades, became a natural gateway service.
- TiKV’s dynamic range-based sharding already existed; previously, its limitation was that shard movement required physical data movement.
In TiDB X, TiKV becomes stateless, but we retain the shard abstraction. Shards are now logical, and snapshot storage moves to S3. This unlocks enormous advantages:
- Start hundreds or thousands of TiKV nodes instantly, each loading shards in parallel.
- Scale down by updating routing and shutting nodes down immediately.
- Avoid multi-hour data migration operations.
- Partition Raft logs by shard, eliminating single-writer bottlenecks.
- For multi-tenancy, simply prefix keys with tenantID_, and each tenant’s footprint becomes tiny and isolated.
This combination — logical shards + S3 snapshots + stateless compute — delivers the breakthrough elasticity we aimed for.
What’s Possible with TiDB X
TiDB X is designed for the next era of software: one shaped by AI agents, dynamic workloads, and explosive long-tail applications. When SQL is generated per user, per request, and per context, the database must scale not by tens of percent, but by orders of magnitude up and down.
TiDB X lets us do exactly that:
- Launch clusters in seconds
- Serve millions of lightweight tenants
- Scale to petabytes with object storage
- Handle huge bursts of traffic
- Minimize costs for “cold” workloads
- Preserve the SQL abstraction users love
- Maintain long-term correctness and durability
- Provide elasticity that matches cloud dynamics
TiDB has always been a database built to respect application flexibility. TiDB X strengthens that mission by giving us a path to scale further than the shared-nothing world ever allowed.
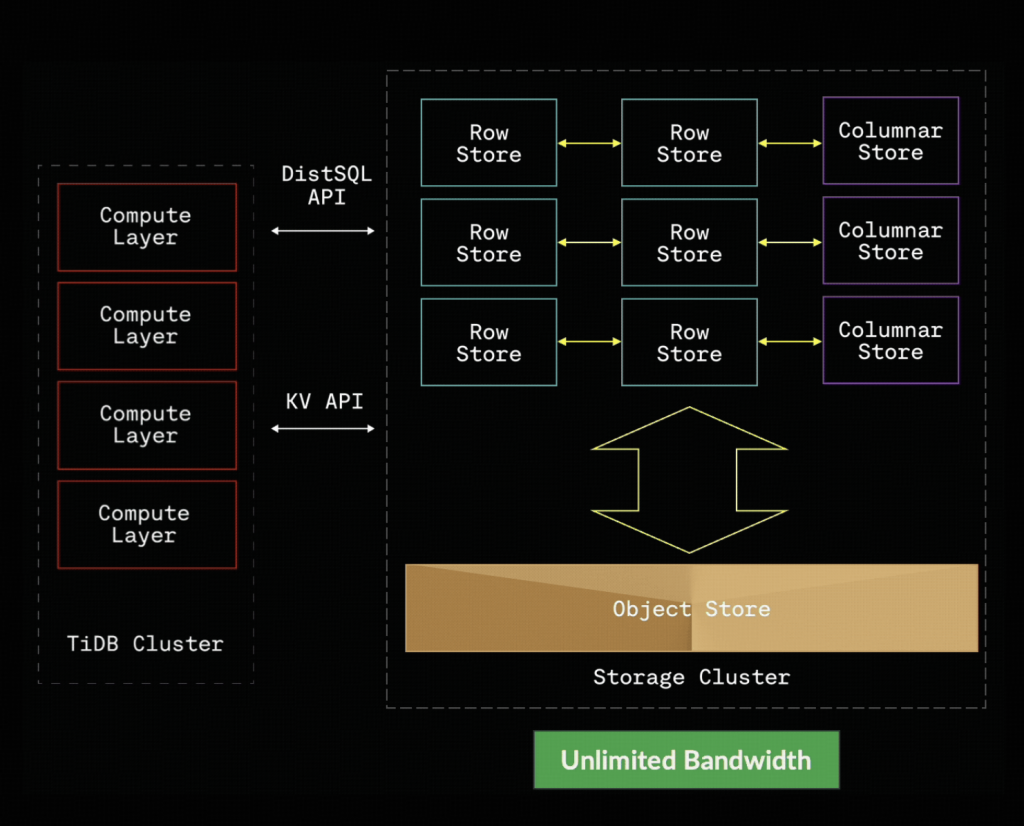
Figure 2: How TiDB X separates compute from storage to scale independently.
What’s Next
In a future post, we’ll go deeper into the cloud management layer of TiDB X — the system responsible for orchestrating Virtual Clusters, workload-aware autoscaling, multi-tenancy, and shared resource pools. This layer is the reason TiDB X behaves less like a traditional database you provision and operate, and more like an adaptive cloud service that continuously responds to real-world demand.
It’s also important to clarify how teams can experience TiDB X today. TiDB X is the core engine powering TiDB Cloud, where its object-storage-based architecture and workload-aware scaling deliver true serverless elasticity out of the box. For most users, TiDB Cloud Essential is the primary and recommended way to get started with TiDB X — offering MySQL compatibility, enterprise-grade reliability, and consumption-based pricing without the need to manage infrastructure, capacity planning, or scaling decisions.
TiDB X itself is not a standalone product or deployment choice. TiDB X provides a foundational architecture that simplifies operations, lowers total cost of ownership, and supports long-term scalability across modern workloads. As TiDB Cloud evolves, TiDB X increasingly serves as the common architectural backbone delivering these capabilities, while TiDB Cloud remains the most accessible way for teams to build fast, run lean, and scale confidently.
Consider this post the start of a broader series on TiDB X — where it came from, how it works, how teams can benefit from it today, and how it shapes the future of TiDB Cloud.
Curious how this architecture works in the real world?
See how Manus 1.5 uses TiDB X to let AI agents spin up, branch, and evolve full-stack applications at massive scale — in production.
Read: How Manus 1.5 Uses TiDB X to Let Agents Ship Full-Stack Apps at Scale
Spin up a database with 25 GiB free resources.



TiDB Cloud Dedicated
A fully-managed cloud DBaaS for predictable workloads
TiDB Cloud Starter
A fully-managed cloud DBaaS for auto-scaling workloads