
Database sharding is a data architecture strategy that increases database performance by splitting up data into chunks and then spreading these chunks “intelligently” across multiple database servers (or database instances). These chunks of data are called shards, while each shard contains a subset of our data. All shards represent the entire set of data, and each row of data exists in only one shard.
Sharding enables databases to handle more transactions and store more data because the work is performed by more machines. Database sharding is very effective for large-scale, distributed environments that require scalability.
Database shards are an example of shared-nothing architecture. The shards are independent database servers; a shard doesn’t share any computing resources with the other shards. Remember: A shard represents a subset of the database’s data, and all shards represent the entire set of data.
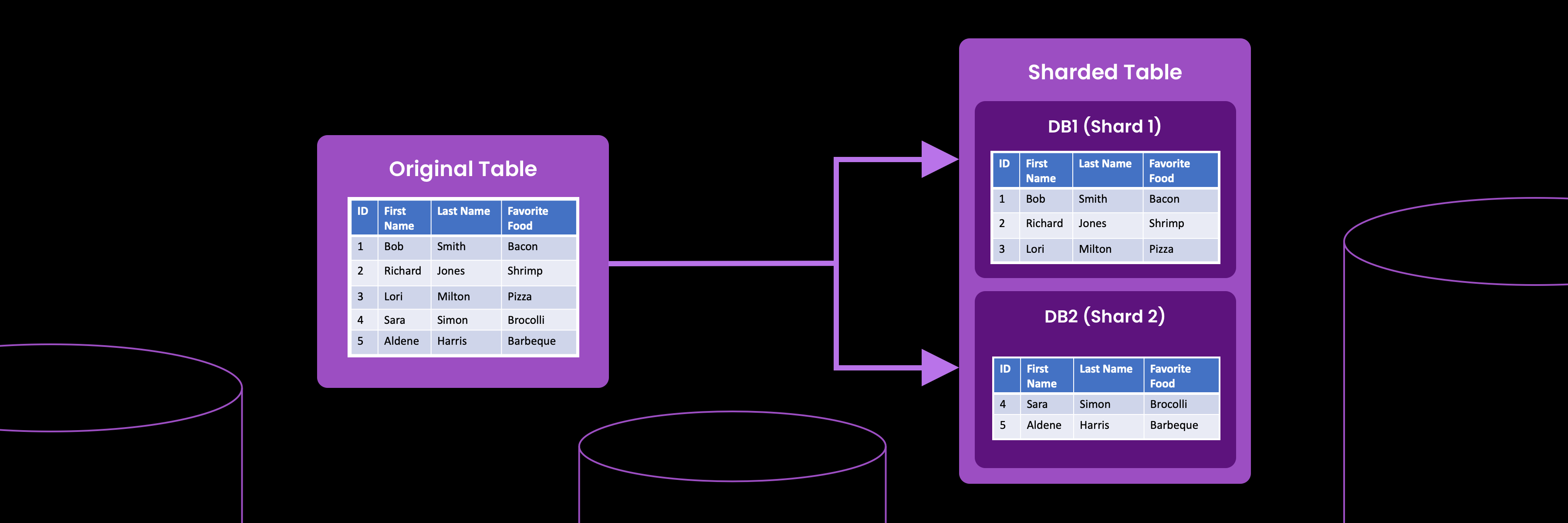
The diagram below shows a table (labeled Original Table) on a single computer.

Imagine that the Original Table is huge; querying it takes a long time. If we change to a sharded architecture, we can increase query performance. The right side of the diagram shows this. The table is now sharded. A portion of the data lives on database server DB1. The remainder of the data lives on database server DB2. This is sharding, splitting data, and spreading it across multiple servers.
When you set up database sharding, how you choose to split up your data can make the difference between a fast database and a very slow database. We’ll revisit this topic in a later section.
In this post, we’ll dive deep into the concepts behind database sharding, exploring all the ins and outs that define this popular architecture pattern.
What is Database Sharding?
Database sharding is the practice of splitting one large logical dataset into smaller, independent pieces—called shards—that are spread across multiple servers. The big win is a horizontal scaling database: as load or data grows, you add more shard nodes instead of buying ever-larger machines. Most sharded systems follow a shared-nothing architecture, where each shard owns its data and resources, minimizing contention and allowing shards to scale and fail independently.
Why Traditional Databases Struggle with SQL Scalability
Traditional databases typically run on a single machine. You may have heard these machines described as servers, virtual machines (VM), or nodes. Regardless of what we call them, they have an upper limit on performance.
This performance limit means you may eventually need to move the database to a more capable machine. When you hear a computer described as “more capable,” you should immediately think, “way more expensive.” A rapidly growing database typically leads to paying for more computing power than is necessary so that the database has time to grow. Once your database outgrows its current machine, you’ll repeat the process by moving to a bigger and even more expensive machine.
There is another way to handle this situation. However, it’s expensive and complicated. You can add new database machines to your environment. But this requires some way of intelligently spreading the data across multiple machines. This can be accomplished by adding a software layer over multiple database servers or adding this capability to your application. This practice is so common that it has a name: Database sharding.
Data Partitioning vs. Sharding: Key Differences Explained
We’ve defined database sharding as splitting one big dataset across many machines, with each piece (a shard) living on its own server and handling a slice of the traffic. Now let’s compare this with partitioning. Partitioning splits one big table into chunks on the same machine with each piece (a partition) managed by a single database server.
In partitioning, the division occurs within a single database server. The data is split into segments, called partitions, but remains under one database system. It’s like organizing different sections within a single warehouse instead of sharding, which spreads the goods across multiple warehouses (shards). Each partition, like a shard, holds a subset of the entire dataset, but unlike sharding, they all reside in the same database server. This approach is particularly beneficial for managing large tables and can improve query performance without distributing the load across multiple servers.
The diagram below is similar to the previous one. The main difference is that the original table is divided into chunks, which live on a single database server. The sharded data lives on multiple database servers.

While database sharding splits and distributes data across different databases for scalability, partitioning organizes data within a single database for efficient management and access. Both aim to enhance performance but do so in different ways.
We won’t dive into it, but combining partitioning and sharding in a single database architecture is very common. So remember, partitioning and sharding aren’t an either-or deal. The approaches can be combined.
When (and When Not) to Use Database Sharding
Deciding if and when to shard your database is like choosing the right moment to expand your business – it’s all about timing and necessity. Database sharding isn’t a one-size-fits-all solution. It comes with its own complexities.
When Sharding Improves SQL Performance
- High traffic and large data volumes: If your database is struggling under the load of millions of users or terabytes of data, it’s time to consider sharding your database.
- Scalability needs: When your business is scaling rapidly, you foresee continuous data and user base growth.
- Performance degradation: If you notice slower query responses and your analytics show a bottleneck at the database level.
When Sharding Adds Unnecessary Complexity
- Small to moderate database size: For databases that aren’t hitting the upper limits of their storage or processing capabilities.
- Simple workloads: If your database isn’t experiencing complex queries or high transaction rates.
- Limited technical resources: Sharding requires significant expertise to implement and manage. If your team isn’t ready for that complexity, hold off (or look for a simpler solution).
Remember, database sharding is a powerful tool, but it’s not always the first in your arsenal. Consider it carefully, and ensure it fits your database’s needs and challenges.
Sharding Strategies: Choosing the Right Approach
Now that we understand database sharding, we need to understand how to implement it. There are many ways to do this. Fortunately, all the methods revolve around the same concept: Spread your data across shards using a sharding key.
Each of these architectures has its own strengths and weaknesses, making the choice highly dependent on the specific requirements and characteristics of the database in question. The trick is to choose the best sharding strategy for your specific situation.
Key-Based (Hash) Sharding
Key-based sharding utilizes a specific value, like a user ID or timestamp, as a sharding key.
We can see this in the diagram below. In this approach, we must choose a key to determine which shard a row of data will live on. In our diagram, we have chosen Column 1 for the shard key. We then apply a hash function to our data item. The hash key determines which shard our data will go to.

Key-based sharding is ideal for evenly distributed data but can be complex to adjust as data grows.
This sharding method uses a hash function on a specific key (like user ID) to assign data to shards. It’s great for ensuring a uniform distribution of data. However, it can become complex when adding or removing shards, as it requires reshuffling of existing data.
Range-Based (Horizontal) Sharding
With range-based sharding, data is divided based on a range of values, such as date ranges or geographical locations.
In the diagram below, we have chosen to shard based on the Paint Color column. Paint Color is a numeric code. The database will take this code and use the shard’s range to determine where the data should be placed.

Range-based sharding is effective for data with clear, linear divisions but can lead to uneven data distribution.
This approach divides data based on a range, such as alphabetical order or date ranges. It’s straightforward and ideal for time-series data but can lead to uneven data distribution if some ranges hold more data than others (i.e., hotspots).
Vertical Sharding
Vertical sharding divides data based on table columns and distributes different columns across various shards. This pattern is used to split wide tables into multiple tables. One table will be narrower than the other. This narrow table will contain the most commonly queried data. On those rare occasions when you need data from the second table, you can join the second table with the first.

Vertical sharding is suitable for tables with large, unutilized columns, enhancing performance by isolating frequently accessed data.
This strategy is useful in environments where analytics are deployed. Analytical workloads commonly need to access very wide tables. However, it can complicate queries that need to access multiple shards simultaneously.
Directory-Based Sharding
Directory-based sharding divines data based on table columns, and distributing different columns across various shards.
In the diagram below, we revisit the Paint Color column we used previously. In this example, we’re using a dictionary (also known as a lookup table) to place data in a specific shard.

Directory-based sharding is suitable for tables with large, unutilized columns, enhancing performance by isolating frequently accessed data.
This sharding method involves a lookup directory to keep track of which data is on which shard. While it offers great flexibility and can handle uneven distributions well, it introduces the risk of the lookup directory becoming a single point of failure. Maintenance and consistency of the directory are also important considerations.
Manual vs. Auto-Sharding: Which Path to Take?
We’ve already discussed sharding strategies, but we haven’t discussed the most important detail: Who is going to handle the sharding? Let’s put it another way. You can manually shard your database or you can use a middleware layer or a database designed to effectively shard the data automatically.
Let’s take a look at the specific methods we can use to implement a manually sharded or auto-sharded database:
Auto Sharding with a Distributed SQL Database
A distributed SQL database natively supports auto sharding and simplifies scalability and maintenance.
- Pros: Built-in sharding, scalability, and reduced maintenance to deliver a true high availability database. Designed from the ground up to automatically shard your data.
- Cons: May require migration from existing systems and new operational expertise. In fairness, all sharding solutions require environmental changes and learning new skills. Using a database designed for auto-sharding is the best long-term solution.
Auto Sharding with Middleware Solutions
Use middleware like ProxySQL or Vitess for MySQL databases. These tools sit between your application and database, handling sharding logic transparently.
- Pros: Simplifies the sharding process and is transparent to the application.
- Cons: Adds another layer to manage and potentially a learning curve. This can increase software, hardware, and administration costs.
Built-In Sharding Capabilities
Databases such as MySQL Cluster or MariaDB include built-in sharding capabilities for a more MySQL-native sharding solution.
- Pros: Native integration with MySQL ecosystems.
- Cons: Potentially less flexible than other distributed SQL databases because the sharding capabilities were added as an afterthought. From the start, distributed SQL databases were designed to support auto-sharding.
Application-Layer Sharding
Modify your application’s logic to distribute data across multiple database instances. This approach gives you control but requires significant development work.
- Pros: High control over sharding logic.
- Cons: Requires significant development and maintenance effort. Scaling-out requires a great deal of planning, and execution typically requires downtime. Implementing this approach results in a consulting project that will repeat throughout the life of the application. Ouch!
In summary, database sharding can be a lot of work. Below is a rough, very high-level overview of what this type of project looks like in practice.
Key Project Steps for Implementing Sharding
- Identify sharding needs: Assess your database to understand the need for sharding. Consider factors like data volume, transaction rate, and performance issues.
- Determine the compute and storage needs: This is one of the most important steps in this process. You may need to buy hardware if you’re sharding an on-prem database. This step is where you pick your hardware. If you’re running in a cloud environment, this is where you try to estimate the costs of the required virtual machines and storage. And don’t forget the software. You may need additional licenses or products. If you’re using open-source software (smart move), you may need to increase your support agreement.
- Create a test environment: A test environment simplifies the process in many situations. Although painful, messing up a testing environment isn’t nearly as bad as destroying a production system. Don’t forget to return to your sizing document to add your test environment.
- Obtain compute and storage resources: Don’t forget to order your hardware and license the necessary software.
- Choose a sharding strategy: Decide between key-based, range-based, vertical, or directory-based sharding. Your choice should align with your data structure and usage patterns.
- Select a sharding key: This key determines how data is distributed across shards. Choose a key that ensures balanced data distribution and minimizes complex cross-shard queries.
- Implement sharding logic: This can be done at the application level. Add a sharding layer above the database servers or use a database management system that supports automatic sharding.
- Test thoroughly: Rigorously test the sharded database before going live to ensure data integrity and performance.
- Monitor and adjust: Post-implementation, continuously monitor the sharded database for performance, and rebalance shards if necessary.
Why Distributed SQL Databases Simplify Sharding
As we’ve demonstrated already, selecting the right database sharding strategy can be challenging. However, there’s a better option that can evolve alongside your organization.
TiDB, powered by PingCAP, is an advanced open-source, distributed SQL database with built-in auto-sharding. It can power data-intensive applications with elastic scaling, real-time analytics, and continuous access to data. Companies using TiDB for their scale-out RDBMS and internet-scale OLTP workloads can benefit from a distributed database that is:
- MySQL compatible: TiDB is wire compatible with MySQL 8.0. This means developers can continue to enjoy the database’s rich ecosystem of tools and frameworks.
- Horizontally scalable: TiDB grants total transparency into data workloads without manual sharding. The database’s architecture separates compute from storage to instantly scale data workloads out or in as needed.
- Highly available: TiDB guarantees auto-failover and self-healing for continuous access to data during system outages or network failures.
- Strongly consistent: TiDB maintains ACID transactions when distributing data globally.
- Mixed workload capable: A streamlined tech stack makes it easier to produce real-time analytics. TiDB’s Smart Query optimizer chooses the most efficient query execution plan, which consists of a series of operators.
- Hybrid and multi-cloud enabled: With TiDB, IT teams can deploy database clusters anywhere in the world, in public, private, and hybrid cloud environments on VMs, containers, or bare metal.
- Open source: Unlock business innovation with a distributed database that’s 100% open source under an Apache 2.0 license.
- Secure: TiDB protects data with enterprise-grade encryption both in-flight and at-rest.
TiDB’s design is inspired by Google’s Spanner and F1 databases. However, it aims to provide similar capabilities without the need for a globally-distributed file system.
Conclusion & Next Steps
Sharding promotes relational database scaling by slicing data across nodes, boosting throughput and keeping performance steady as you grow. But classic manual sharding brings trade-offs: app rewrites, cross-shard joins, operational toil, and thorny failovers.
Distributed SQL databases preserve the simplicity of a single logical database while delivering shard-like horizontal scale. This allows you to keep SQL, transactions, and operational calm without building a sharding framework yourself.
Learn more about TiDB’s distributed SQL architecture, or start a free TiDB Cloud trial and see the difference on your workload.
Experience modern data infrastructure firsthand.



TiDB Cloud Dedicated
A fully-managed cloud DBaaS for predictable workloads
TiDB Cloud Starter
A fully-managed cloud DBaaS for auto-scaling workloads