

Key Takeaways
- Kimi K2.6’s agent website builder runs on TiDB Cloud, supporting millions of agent-created tenants without per-tenant database instances.
- Per-tenant Postgres (Supabase, Neon) and schema-per-tenant Postgres both failed: One on cost, the other on isolation.
- Agent data infrastructure is now a four-axis race: Long-tail tenants, mutable schemas, burst absorption, and second-scale create/destroy.
- The pattern converging across agent-native companies: One agent, one sandbox, one storage, one database.
A few months back I wrote two pieces about what infrastructure agents actually need: One on the database trends shaping 2026, another on why agents are the new database users. The arguments stayed mostly theoretical. What was missing was a large-scale, practical example. As of this quarter, I can finally point to one.
TiDB Cloud is now the agent database supplier behind Kimi K2.6, powering the website-building service inside the Kimi Agent product. Moonshot AI, the company behind Kimi, released K2.6 in April as an open-weight trillion-parameter model that benchmarks competitively against GPT-5.4 and Claude Opus 4.6 on agentic and coding tasks. With Moonshot’s permission, I want to walk through what we built, what failed first, and what this case tells us about where agent infrastructure is heading.
What an End-to-End Agent Application Actually Looks Like
Kimi K2.6 is the cleanest version of the pattern. A user describes what they want in plain language. The agent generates the front end, the back end, the database schema, ships the application, and hosts it. No developer in the loop, no template selection, no technical background required.
This is different from developer-oriented AI tools like Lovable, where a human reviews the output. In Kimi K2.6, the agent owns the full lifecycle, runtime included. The deliverable is not a code repository. It is a live service.
The hard problem is not code generation. The models are good enough at that. The problem is what happens after: Hosting, running, and keeping the data alive for a long-tail population at a cost structure that doesn’t blow up the unit economics.
Why Agent-Built Sites Break Traditional Database Economics
If your audience is not developers, the user base is much larger and the barrier to entry is words, not syntax. Most AI products run on a monthly subscription.
But the cost shape underneath changes. For code generation aimed at engineers, computational cost is concentrated in inference. Subscription dollars largely pass through to GPU and token bills.
For a website-building agent, the picture inverts. The LLM is expensive during creation, when the agent is reasoning, generating, and provisioning. After that, the site is live, the agent is gone, and the cost of staying online is web servers, bandwidth, and the database. Margin lives in the hosting layer, not inference.
So the question becomes: How do you host the long tail in cost effectively?
The Kimi service may stand up tens of millions of websites in a single week. Allocating a real Postgres or RDS instance per site, the math is hopeless: Storage, network, control plane, and idle compute dominate every line item. Even SQLite per site, while cheaper, transfers the operational burden to you: Backups, recovery, high availability, and schema evolution. Managing hundreds of millions of small databases is its own engineering project, and not one you want competing with the agent product for resources.
Why Postgres-Per-Tenant Collapses at This Scale
We spent real time on the alternatives before settling on the architecture we shipped. Two are worth describing because they’re the answers most teams reach for first.
Option 1: A serverless Postgres instance per agent (the Supabase or Neon model). The cleanest mental model. Each site gets its own database. Tenants are physically isolated. The problem is purely arithmetic. At millions of instances, the cost of even idle instances dominates. Serverless databases scale to zero, but they don’t disappear. Each tenant still carries control plane overhead. Multiply by tens of millions and the bill is unsustainable.
Option 2: One large Postgres instance with schema-per-tenant isolation. The Kimi team tried this. At tens of thousands of tenants, performance fell apart. Connection storms, lock contention, and noisy-neighbor effects made the experience unpredictable. The failure radius was catastrophic. One bad tenant could degrade thousands of others. Flow control, isolation, and data privacy all got harder.
Neither path produced an architecture Kimi could put in front of its users.
The New Race: Long-Tail Tenants, Mutable Schemas, Bursty Traffic, Second-Scale Create/Destroy
I’ve been thinking about this since the back half of last year. For three decades, database benchmark wars were about single-point performance: Higher TPS, lower p99, and larger single-instance capacity. But the race has changed. The new race goes to whoever can do all four of these at the same time:
- Carry a large population of long-tail tenants. Each one has modest request volume, but every one needs to be online on demand.
- Accept schema mutability driven by the model. Agents change schemas ad-hoc. The database must tolerate branching, versioning, and rewrites without DBA intervention.
- Absorb unpredictable burst traffic. A site with three visits yesterday may go viral today. Capacity has to elasticize on the second.
- Allow agents to create and destroy data at machine speed. New databases provisioned in seconds, torn down just as fast. SQL generated dynamically.
When all four happen simultaneously, who provides the smoothest experience? That is a different competition than anything we’ve been benchmarking for.
Three Decisions Behind the Kimi Architecture
Working with the Kimi team over the past few months, three strategic decisions shaped the outcome. All three are about the agent’s experience with infrastructure.
Make the Database Invisible to the Agent
Every task and site is isolated. Every database is created and used by the agent, on demand, in seconds. Only when that property holds does anything else matter.
TiDB Cloud’s warm pool plus scale-to-zero design gives the agent a ready-to-use database instance in under a second. The agent’s delivery chain runs a few minutes end to end. If provisioning eats two of those minutes, the agent has to write retry and polling logic into its own code. That burden belongs on the database, not the agent.
Keep the Agent’s Tech Stack Convergent
Human engineers like a small, opinionated stack because it reduces decision fatigue. For an LLM, the same property directly determines code generation success rate.
Fewer systems means fewer bugs. Skills, scaffolding, and best practices the model can rely on (rather than recreating each time) make generated code substantially more stable as a live service. The shape of the stack is a code-generation input. We treated it that way.
Virtualize the Database, Don’t Allocate It
This is the part of the design I am most proud of, and it distinguishes this approach from Supabase and Neon.
In a traditional serverless setup, each sandbox pairs with a real database instance, reclaimed when it cools off. Because the instance is real, the unit cost is bounded below by running it, idle or not. And the agent feels it: Instances get reclaimed, sessions break, connections drop.
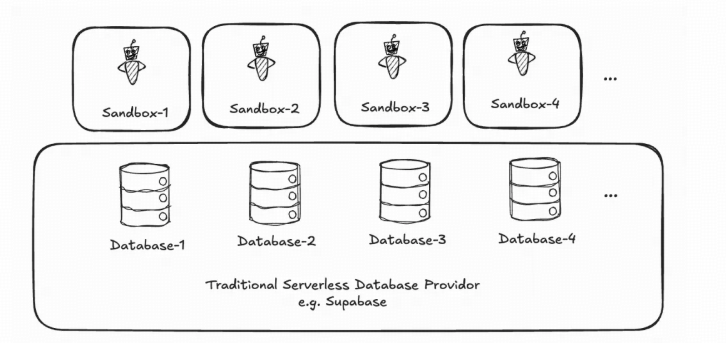
Figure 1. Traditional serverless agent database: A real DB instance per sandbox. Cost rises with the long tail; reclamation breaks the agent experience.
TiDB Cloud takes a different path. There are no per-tenant database instances. The interface is virtual. From the agent’s view inside its sandbox, it sees a complete, independent database. Underneath, all data lives in a large, shared, distributed key-value store backed by object storage. That layer handles tenant isolation, hot/cold separation, and visibility at the logical level, not by spinning up physical resources per tenant.
In the limit, the platform needs only a persistent DB session gateway. Everything else is elastic. The user-facing surface looks like millions of independent databases. The underlying physics is one shared substrate.
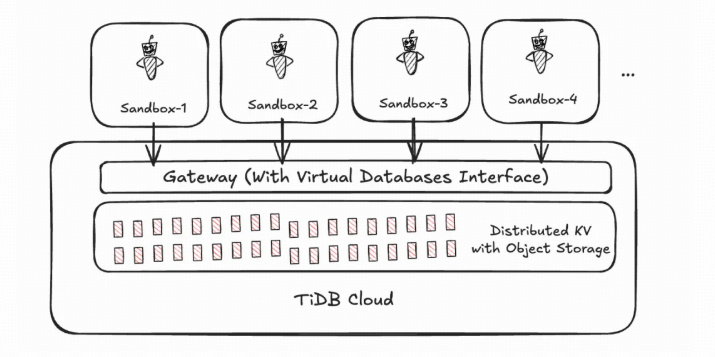
Figure 2. TiDB Cloud: a virtual database per sandbox, backed by one shared distributed KV substrate on object storage.
The result: An order-of-magnitude reduction in data infrastructure cost, and a stable agent experience. No reclamation, no hibernation pauses, no broken sessions. From inside the agent’s view, the database is always there.
While writing this post, I built a small family message board for my house. Front end, back end, schema, hosting. Ten minutes from idea to live URL.
One Agent, One Sandbox, One Storage, One Database
This is not an isolated story. Over the last twelve months, our team has sat in on architecture conversations at many agent companies in the US and Asia.
The pattern is converging. In the previous era, one product served hundreds of millions of users from a shared backend. Now the unit shifts. A single user may have ten or a hundred agents running on their behalf. Each needs its own state, its own data, its own queryable, durable, isolated environment.
Manus saw this early: Agents create 90%+ of new instances, and 99% are single-use. Extreme multi-tenancy is the default. Kimi K2.6 is the same pattern, productized for a website-building workflow.
The mental model the industry is settling on: One agent, one sandbox, one storage, one database.
What the Second Half of Agent Commercialization Looks Like
The first half of agent commercialization was about model intelligence. Whose model reasons better. Whose agent runs longer chains.
The second half, in my view, is about whether the agent’s deliverables actually run. Reliably, cheaply, for real users. That is an infrastructure problem, not a model problem. It is the same transition full-text search went through when it became infrastructure (Elasticsearch), and caching before it (Redis). Agent state and agent data are next.
Our Kimi K2.6 collaboration is, to me, an early data point for what good looks like. A model vendor can ship a category-defining product faster, at better unit economics, when the data layer is built for the workload from the start. What comes next in this category is going to be interesting.
The architecture I outlined above is one slice of a broader thesis. Agentic AI Data Architectures, the O’Reilly report I co-authored with Blaize Stewart, goes deeper on multi-tenant patterns, agent memory infrastructure, and the operational realities of running databases at LLM scale.
Ed Huang is the co-founder and CTO of PingCAP, the company behind TiDB. He has been working on distributed systems and databases for over a decade. Find him on GitHub at @c4pt0r.
Spin up a database with 25 GiB free resources.



TiDB Cloud Dedicated
A fully-managed cloud DBaaS for predictable workloads
TiDB Cloud Starter
A fully-managed cloud DBaaS for auto-scaling workloads