

The FinTech industry is innovating at record speed. From embedded payments and AI-driven fraud detection to real-time credit scoring and risk analytics, financial services are becoming faster, smarter, and more personalized. But behind the scenes, many platforms are still powered by legacy databases and architectures built for a different era.
Traditional systems are struggling to keep up. Monolithic databases falter under high-concurrency workloads, choke on regional traffic spikes, and force teams into complex sharding models. The consequences are familiar: missed growth, rising infrastructure costs, and engineering resources spent on firefighting instead of innovation.
To stay competitive, FinTech leaders need more than incremental fixes. They need a data foundation that can scale effortlessly, process both transactions and analytics in real time, and maintain consistency and uptime across global operations.
In this post, we’ll explore the architectural challenges FinTech companies face, and how distributed SQL helps overcome them to support next-gen business growth.
Why FinTech Platforms Are Reaching a Breaking Point
The data demands on FinTech platforms are unlike anything the industry has seen before:
- Transaction volume is exploding: The digital payments segment alone is growing at nearly 20% annually. Instant payments are expected to hit $58 trillion by 2028.
- Real-time analytics are now table stakes: Fraud detection, personalized recommendations, credit decisions, these can’t wait for batch jobs.
- Regulatory pressure is mounting: From GDPR to PSD2 to India’s new data protection law, FinTechs must ensure auditability, encryption, and data integrity at all times.
Legacy RDBMSs and manually sharded MySQL clusters weren’t built for this kind of complexity. They’re hard to scale, difficult to maintain, and often force teams to bolt on additional tools just to survive.
FinTech teams need something better, something built for this moment.
When Growth Outpaces Data Infrastructure
FinTech companies aren’t just building apps, they’re operating high-velocity data engines. And the pressures are stacking up:
- Unpredictable Spikes in Demand: Whether it’s a holiday rush, a viral referral campaign, or market volatility, FinTech traffic is volatile by design. Vertical scaling strategies fall short. Manual intervention becomes the norm. And provisioning for peak demand means paying for idle capacity most of the year.
- The Need for Real-Time Everything: Fraud detection, risk scoring, personalization, compliance triggers, these can’t wait for batch processing. But most legacy architectures separate OLTP and OLAP, forcing teams to run complex ETL pipelines or operate separate systems entirely. That’s added cost, complexity, and latency, right where you can least afford it.
- Cross-Region Complexity: Today’s FinTechs are global from day one. But coordinating data across regions introduces latency, availability risks, and consistency tradeoffs. Many databases prioritize availability over strong consistency, a compromise that’s unacceptable in financial systems, where accuracy and auditability aren’t optional.
- Sharded Systems = Hidden Operational Debt: As usage grows, many companies adopt sharding as a quick fix. But managing schema changes, balancing load, routing queries, and maintaining observability across shards becomes a full-time job. Engineering time shifts from product development to infrastructure triage.
- Compliance Burden Is Rising Fast: Between GDPR, PCI-DSS, India’s DPDP Act, and sector-specific audits, FinTechs now operate under a microscope. Meeting requirements around encryption, audit trails, and disaster recovery requires not just discipline, but infrastructure that bakes those features in from the start.
How FinTech Leaders Are Responding
As the pace of innovation accelerates, leading FinTech firms are rethinking how they manage data. The old model of cobbling together separate systems for transactions, analytics, and caching is too complex, fragile, and slow. Teams are turning to distributed SQL to simplify operations and move faster.
Why Do FinTech Companies Adopt Distributed SQL?
- Seamless Scaling: Traditionally, scaling meant sharding, migrations, and risk. Distributed SQL systems scale horizontally by design, adding nodes to handle surging demand without downtime. This enables smoother rollouts and faster time to market, with less technical debt.
- Unified Architecture: FinTech teams are consolidating OLTP, OLAP, and real-time workloads onto a single platform. Distributed SQL supports mixed workload processing natively, eliminating ETL pipelines and simplifying operations with one source of truth.
- Real-Time Insight: Access live transactional data for analytics without waiting on batch jobs. This shortens the loop from data to decision, empowering teams to experiment, iterate, and launch features with speed and confidence.
- Built-In Availability and Consistency: Distributed SQL systems offer strong ACID guarantees and automatic failover across regions. Transactions are replicated and durable by default, ensuring uptime and accuracy even during hardware failures or network disruptions.
- Simplified Operations and Lower Cost: With fewer moving parts and cloud-native automation, unified architectures reduce tooling sprawl, operational overhead, and staffing requirements. This allows teams to do more with less.
- Compliance from the Ground Up: FinTech platforms require infrastructure that supports encryption, audit trails, access controls, and disaster recovery by default. Distributed SQL helps teams stay ahead of evolving regulatory demands without costly add-ons.
This shift toward data-intensive infrastructure reflects a broader mindset among FinTech leaders: build for scale without sacrificing speed, simplicity, or control. The goal is no longer to just keep up, it’s to stay ahead by investing in platforms that can grow with the business, adapt in real time, and reduce operational friction along the way.
That’s where distributed SQL becomes a game changer. And among the solutions driving this evolution, TiDB stands out by offering horizontal scalability, built-in consistency, and real-time analytics in a single, cloud-native system.
What Makes TiDB Different? A Purpose-Built Database for FinTech Scale
TiDB is an open-source, distributed SQL database built for the realities of FinTech: unpredictable growth, real-time insight, and strict compliance. It combines the horizontal scalability of NoSQL with the strong consistency and SQL compatibility of traditional RDBMSs, without the typical trade-offs.
As FinTech platforms scale and evolve, core architectural advantages like elasticity, workload unification, and built-in resilience are no longer optional, they’re essential.
Horizontal Scalability
As FinTechs grow, so do the volume and velocity of their data. Traditional databases hit bottlenecks as traffic scales, often forcing teams into costly migrations or error-prone sharding.
TiDB solves this by decoupling compute and storage, allowing each layer to scale independently. The compute layer handles SQL processing, while the storage layer uses a distributed key-value engine that automatically shards data into “Regions” and replicates it using the Raft consensus protocol. When traffic surges, new nodes can be added seamlessly to boost throughput with no downtime and service disruption.
This makes it easier to manage sudden spikes, regional expansion, and long-term growth without reinventing your architecture every time.
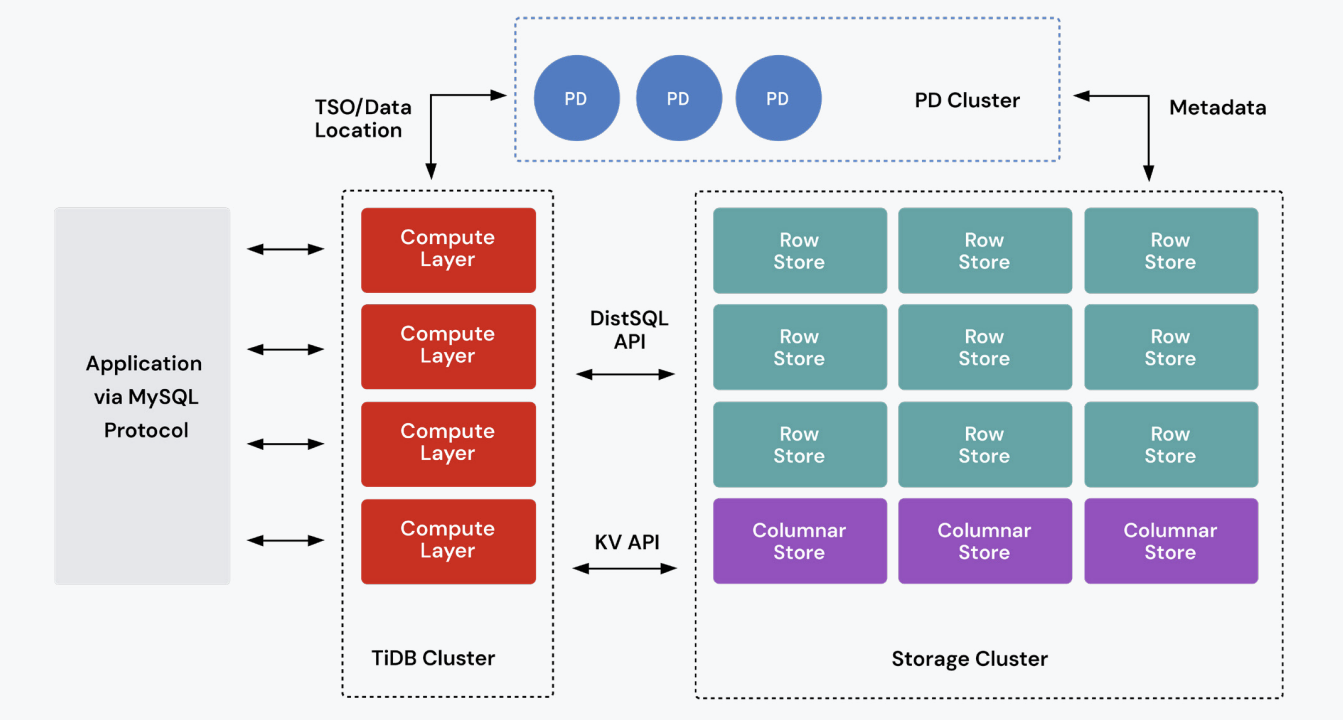
Figure 1. A diagram depicting TiDB’s distributed SQL architecture that separates compute from storage.
Mixed Workload Processing
Many FinTech applications need both fast transactions and real-time analytics, but legacy stacks often require separate systems for OLTP and OLAP, stitched together by ETL pipelines.
TiDB unifies these workloads through its native mixed workload processing capabilities. A built-in columnar storage engine continuously replicates live transactional data from row storage in near real time. The TiDB query optimizer then intelligently routes analytical queries to the columnar layer and transactional queries to the row layer, all within the same database.
The result: faster decision-making, lower operational overhead, and a simplified data stack that supports everything from fraud detection to customer personalization on fresh, reliable data.
Strong Consistency (ACID) and High Availability
In financial systems, consistency isn’t negotiable. A single out-of-order transaction or failed write can have real-world consequences.
TiDB ensures strong data integrity with ACID compliance and Snapshot Isolation by default. Every write is replicated to a quorum of nodes using the Raft protocol before being committed, guaranteeing consistency even in the face of hardware failures or network partitions. And with built-in failover and multi-zone deployment support, TiDB maintains uptime and correctness, even during failure scenarios.
This level of resilience is crucial for FinTechs operating across regions, compliance frameworks, and high-stakes workloads.
Cloud-Native Flexibility
FinTech infrastructure needs to be as agile as the teams building on it. TiDB is cloud-native at its core, designed to run across public clouds, private infrastructure, or hybrid environments. It supports containerized deployment via Kubernetes and comes with the TiDB Operator, which automates provisioning, scaling, upgrades, backups, and recovery.
This gives platform and SRE teams full control over their deployments, while reducing manual effort and enabling DevOps best practices.
How Plaid Reduced Operational Overhead 25% While Eliminating Unexpected Downtime
Plaid, a global leader in financial data connectivity, helps thousands of apps and institutions securely
access consumer financial data. The company’s engineering team faced growing pressure as their largest, most critical services began to hit limits on their hosted MySQL stack. Availability issues, slow schema changes, and weeks-long workarounds were becoming the norm.
Plaid adopted TiDB to eliminate the burden of sharding and future-proof its data infrastructure. With native MySQL compatibility, TiDB allowed Plaid to migrate a greenfield service with minimal code changes. The platform’s horizontally scalable, cloud-native design made it easy to adapt to traffic spikes and evolving application requirements.
Key results included:
- 25% reduction in operational overhead by eliminating sharding and simplifying cluster management
- 5x increase in resource utilization thanks to elastic scaling and improved topology
- Zero-downtime schema changes enabled faster iteration and safer deployments
- Improved developer velocity with centralized query patterns, simplified observability, and faster test cycles
- Option to integrate real-time analytics later using TiDB’s mixed workload processing capabilities, without rearchitecting
“With TiDB, we can now perform upgrades with zero downtime and large table schema migrations,” said Xander Hill, Principal Engineer at Plaid. That shift didn’t just improve reliability, it fundamentally changed how quickly and safely their teams could move.
Plaid’s migration story shows how the right architectural choice early on can set the foundation for long-term scale, compliance, and developer efficiency.
Download Our Complete Guide to FinTech Resilience
Legacy databases weren’t built for today’s FinTech demands. As digital services become more personalized, intelligent, and compliance-intensive, infrastructure must do more than just store data. It has to scale seamlessly, operate without interruption, and support real-time decisions.
Our latest white paper explores how FinTech leaders are using distributed SQL, and specifically TiDB, to modernize their data architecture. From global payment processors to digital banks and embedded finance pioneers, discover how next-gen platforms are eliminating downtime, simplifying operations, and accelerating product velocity.
Download the full guide to see how TiDB supports FinTech growth, compliance, and resilience at scale.
Spin up a database with 25 GiB free resources.



TiDB Cloud Dedicated
A fully-managed cloud DBaaS for predictable workloads
TiDB Cloud Starter
A fully-managed cloud DBaaS for auto-scaling workloads