

Key Takeaways
- SingleStore uses an aggregator–leaf design with “Universal Storage,” while TiDB is layered (TiDB SQL + TiKV row store + TiFlash columnar).
- SingleStore replicas are asynchronous (eventual windows); TiDB is strongly consistent (linearizable) via Raft.
- SingleStore relies on hash partitioning with partition counts set at creation; TiDB auto-shards into Regions that split and rebalance automatically.
- SingleStore is proprietary; TiDB is Apache 2.0 and includes MySQL migration tooling (DM, Lightning, TiCDC).
As data volumes explode and applications demand real-time insights alongside high-throughput transactions, teams increasingly turn to distributed SQL databases that promise to handle both OLTP and OLAP workloads in a unified system. SingleStore (formerly MemSQL) and TiDB are leading players in this space, offering MySQL compatibility, horizontal scalability, and Hybrid Transactional/Analytical Processing (HTAP) capabilities.
But while these databases share similar positioning in the market, their architectural philosophies, consistency models, and operational characteristics differ significantly. For teams evaluating which distributed SQL database best fits their needs, understanding these differences can impact performance, operational complexity, and long-term scalability.
In this blog, we’ll explore how SingleStore and TiDB approach distributed database design, where each excels, and how to determine which solution aligns with your workload requirements and team capabilities.
SingleStore vs TiDB: At-a-Glance Comparison
| Dimension | SingleStore | TiDB |
| Licensing | Proprietary, commercial | Open source (Apache 2.0) |
| Architecture | Aggregator-leaf with Universal Storage (rowstore + columnstore in same table) | Layered with separate TiDB (SQL), TiKV (row storage), TiFlash (columnar storage) |
| Consistency Model | Eventual consistency for replicas, asynchronous replication | Strong consistency (linearizability) via Raft consensus |
| HTAP Approach | Unified storage with automatic rowstore-to-columnstore conversion | Separate optimized engines (TiKV for OLTP, TiFlash for OLAP) with async replication |
| Sharding | Hash partitioning, partition count set at creation | Automatic Region-based sharding, dynamic splitting and rebalancing |
| Query Execution | Code generation (compiles to machine code via LLVM) | Interpretation with cost-based optimization, vectorized execution in TiFlash |
| Storage Efficiency | Multiple formats within same table (memory rowstore, columnstore segments, logs) | Explicit replicas (TiKV rows + optional TiFlash columns), clear storage cost model |
| MySQL Compatibility | MySQL protocol and partial syntax support | High MySQL compatibility including protocol, syntax, and ecosystem tools |
| Horizontal Scalability | Add leaf nodes for storage/compute, aggregator nodes for coordination | Add nodes for any layer independently (TiDB, TiKV, TiFlash) |
| Best For | Memory-optimized HTAP, high-concurrency analytics with repeated queries, teams prioritizing managed services | Strong consistency requirements, predictable OLTP latency with OLAP, open-source governance, MySQL migration |
What is SingleStore? Understanding the Architecture
SingleStore began life in 2011 as MemSQL, positioning itself as an in-memory distributed database optimized for speed. The original design focused on keeping hot data in memory for blazing-fast query performance, later evolving to add disk-based columnar storage and rebranding as SingleStore to reflect its broader capabilities.
SingleStore’s Core Architecture
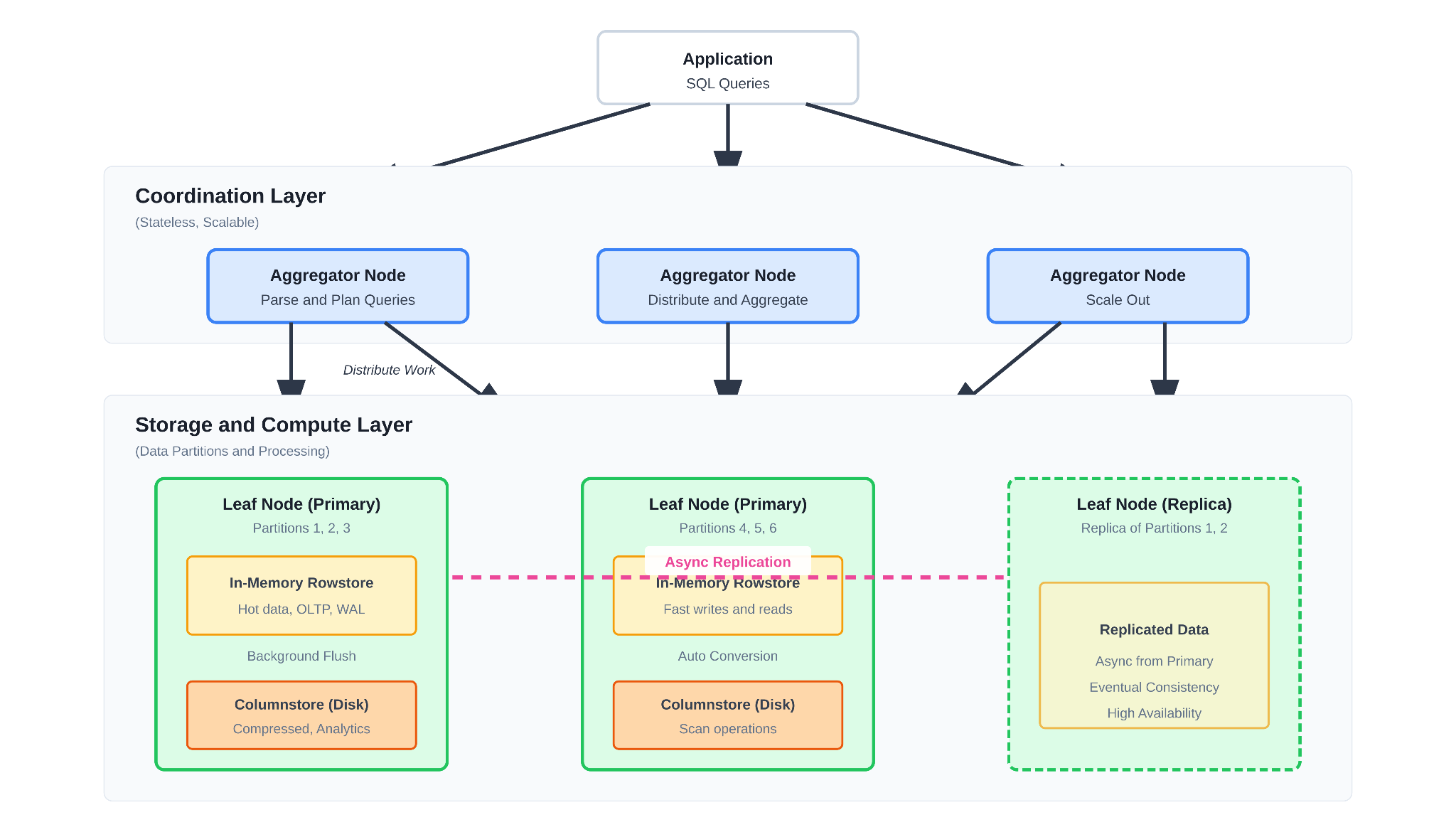
As shown above, SingleStore operates on a distributed aggregator-leaf architecture that separates query coordination from data storage and processing. The system consists of two primary node types:
- Aggregator nodes receive SQL queries from applications, parse them, generate execution plans, distribute work to leaf nodes, and aggregate results back to clients. Aggregators are stateless and can be scaled independently based on connection and coordination requirements.
- Leaf nodes store actual data partitions (shards) and execute query operations locally. Each leaf contains multiple partitions, with data automatically distributed using hash partitioning on primary keys. For high availability, SingleStore replicates each partition to secondary leaf nodes.
This separation allows teams to scale coordination layer capacity independently from storage and compute capacity, with typical deployments running a 5:1 ratio of leaf to aggregator nodes for balanced performance.
The Universal Storage Approach
One of SingleStore’s distinguishing features is its Universal Storage architecture, which combines rowstore and columnstore within the same table type. Rather than forcing developers to choose between row-oriented tables for transactions and column-oriented tables for analytics, Universal Storage automatically manages data in both formats:
- In-memory rowstore handles incoming writes and recent data with low-latency random access patterns typical of transactional workloads.
- Columnstore segments are created by background processes that flush row data from memory into compressed columnar format on disk, optimizing for analytical scan operations.
This tiered approach aims to deliver strong OLTP performance while simultaneously supporting analytical queries on the same data without maintaining separate copies. Writes go to the rowstore and are asynchronously persisted to write-ahead logs, while background flushers convert mature data into columnstore segments for efficient analytics.
Query Compilation and Execution
SingleStore leverages code generation to compile SQL queries into native machine code rather than interpreting them at runtime. Query plans are transformed into SingleStore Bytecode, then compiled via LLVM into executable machine code that’s cached for reuse. This approach delivers performance advantages for repeated queries and complex analytical workloads, though it introduces compilation overhead for ad-hoc queries.
Where SingleStore Excels
SingleStore’s architectural choices make it particularly well-suited for specific use cases and workload patterns:
High-Concurrency Analytical Queries
SingleStore’s code generation and in-memory processing deliver exceptional performance for analytical queries that benefit from compiled execution and cached plans. For workloads where the same or similar queries run repeatedly against large datasets, the compilation investment pays dividends in reduced latency and higher throughput.
Unified HTAP Without ETL
Teams that need to run analytics on fresh transactional data without building separate ETL pipelines appreciate SingleStore’s ability to query the same tables for both OLTP and OLAP workloads. The Universal Storage approach means there’s no need to explicitly replicate data between row and column stores or maintain multiple table types.
Memory-Optimized for Hot Data
Applications with working sets that fit comfortably in memory can leverage SingleStore’s in-memory rowstore for extremely low-latency access patterns. This makes SingleStore attractive for real-time applications, dashboards, and systems where sub-millisecond query response times matter.
Cloud-Native Deployment Flexibility
SingleStore Helios (the managed cloud offering) provides workspaces with compute-storage separation, autoscaling capabilities, and “bring your own cloud” deployment options. For teams prioritizing managed services and elastic scaling in cloud environments, SingleStore offers a polished operational experience.
Where SingleStore Faces Trade-offs
While SingleStore delivers compelling performance for certain workloads, teams evaluating it should understand the architectural trade-offs and operational considerations:
Proprietary Licensing and Lock-in
Unlike TiDB, which is fully open-source under Apache 2.0, SingleStore is a proprietary database with commercial licensing. While the technology is proven and mature, teams need to factor in licensing costs, vendor lock-in considerations, and the inability to fork or extend the codebase for specialized requirements. For organizations that value open-source ecosystems, community governance, and the ability to self-support without vendor dependencies, this represents a significant difference.
Consistency Model Complexity
SingleStore’s replication between primary and secondary partitions introduces eventual consistency windows. While the system offers “high availability” mode where replicas can take over during failures, the asynchronous nature of replication means that secondary replicas may lag behind primaries during high write loads. This can create complexity for applications that require strict read-after-write consistency or need to reason about which data is visible on which nodes.
Storage Efficiency Trade-offs
Although SingleStore’s Universal Storage is more efficient than maintaining completely separate rowstore and columnstore copies, it still incurs storage overhead from maintaining data in multiple formats within the same table. The in-memory rowstore, columnstore segments, write-ahead logs, and snapshots all consume storage capacity. Teams with extremely large datasets (multiple petabytes) need to carefully plan storage requirements and understand the memory-to-disk ratios that work for their access patterns.
Write Amplification in HTAP Scenarios
The process of writing to the in-memory rowstore, persisting to write-ahead logs, replicating to secondary partitions, and eventually converting to columnstore segments creates write amplification. For extremely write-heavy workloads (hundreds of thousands of transactions per second), this amplification can impact throughput and increase infrastructure costs compared to systems with more streamlined write paths.
Query Compilation Overhead
Code generation delivers performance advantages for repeated queries but introduces latency for one-off or ad-hoc queries. Development and testing workflows that involve many unique query patterns may experience slower response times compared to interpretation-based systems. While query plan caching mitigates this for production workloads, teams should benchmark their specific query patterns.
What Makes TiDB Different: The Open-Source Distributed SQL Approach
TiDB takes a fundamentally different architectural approach, built from the ground up as a distributed SQL database that prioritizes strong consistency, horizontal scalability, and MySQL compatibility without compromising on any of these dimensions.
Layered Architecture with Separation of Concerns
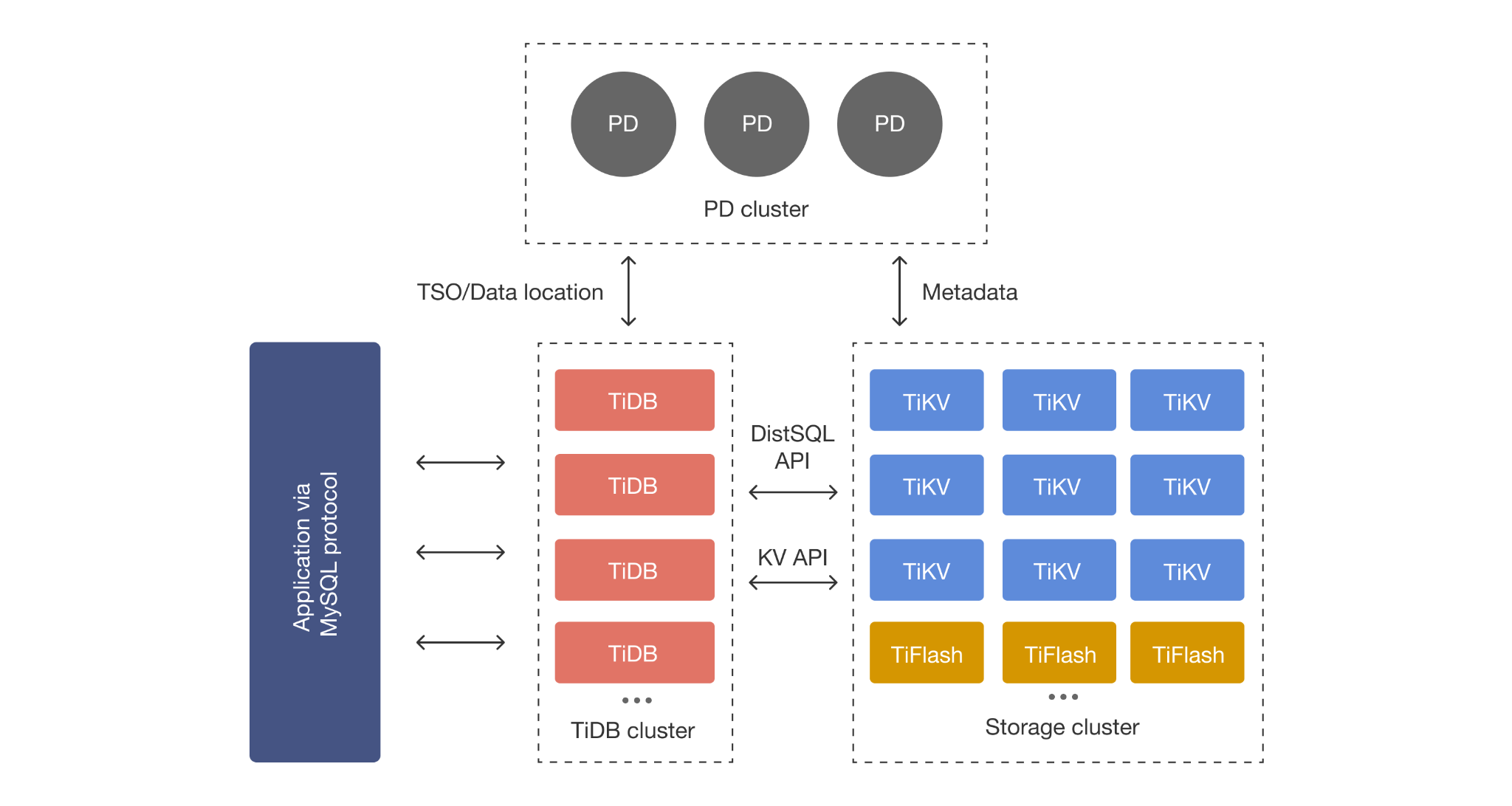
As illustrated above, TiDB’s architecture cleanly separates the SQL layer, distributed storage layer, and analytics engine into distinct components that can scale independently:
- TiDB Server (stateless SQL layer) handles MySQL protocol compatibility, SQL parsing, query optimization, and distributed query execution. TiDB servers can be added or removed elastically without impacting data storage.
- TiKV (distributed transactional storage) stores data across multiple nodes using the Raft consensus algorithm. Data is automatically sharded into Regions and replicated across nodes for fault tolerance and strong consistency.
- TiFlash (columnar analytics engine) provides real-time analytics through asynchronous replication from TiKV. TiFlash maintains a separate columnar replica optimized for OLAP queries while TiKV handles OLTP workloads.
This layered design means each component can be scaled and optimized independently. Need more SQL processing capacity? Add TiDB servers. Need more storage? Add TiKV nodes. Want faster analytics? Add TiFlash replicas. The architecture doesn’t force trade-offs between these dimensions.
Raft Consensus for Strong Consistency
Unlike SingleStore’s asynchronous replication model, TiDB uses the Raft consensus protocol to ensure every write is committed to a majority of replicas before acknowledging success. This delivers linearizable consistency guarantees—meaning applications can always read what they just wrote, regardless of which node they connect to.
For distributed transactions spanning multiple Regions, TiDB implements a two-phase commit protocol with timestamp oracle coordination, ensuring full ACID compliance even across geographic regions. This eliminates the complexity of reasoning about eventual consistency windows or replica lag.
Automatic Sharding Without Application Changes
TiDB automatically shards data into Regions (96MB by default) and distributes them across TiKV nodes. As data grows, Regions split automatically. As the cluster scales, Regions rebalance automatically. Importantly, this happens transparently—applications see a single logical database and don’t need to manage shard keys, routing logic, or cross-shard operations.
This contrasts with SingleStore’s hash partitioning approach, where partition count is set at database creation time and changing it later requires careful planning. TiDB’s dynamic Region splitting means the system adapts organically to data growth and access patterns.
True Separation of OLTP and OLAP
While SingleStore combines rowstore and columnstore within the same table, TiDB maintains them as separate replicas. TiKV handles transactional workloads with row-oriented storage, while TiFlash maintains asynchronously replicated columnar copies optimized for analytics.
Critics sometimes point to this as “storing an extra copy,” but this design choice provides key advantages:
- OLTP and OLAP workloads are physically isolated—heavy analytical queries on TiFlash don’t impact transactional performance on TiKV.
- Each engine can be optimized specifically for its workload without compromises.
- Analytics replicas can be scaled independently based on query concurrency needs.
- Queries can be intelligently routed to the optimal engine based on patterns.
For organizations where predictable transactional latency matters as much as analytical throughput, this separation provides operational advantages that outweigh the storage cost.
Open-Source DNA and Community Governance
TiDB is fully open-source under Apache 2.0, with development guided by the PingCAP team and an active global community. This means teams can inspect the codebase, contribute features, deploy and support it themselves, or leverage PingCAP’s commercial support. There’s no vendor lock-in or proprietary black boxes—just transparent technology that can be forked, extended, and operated however your organization needs.
When SingleStore Makes Sense
SingleStore is a strong fit when your team needs:
- Memory-first performance: Your working dataset fits comfortably in memory and you need sub-millisecond query latency for both transactions and analytics.
- Unified table model: You prefer querying a single table type for HTAP rather than managing separate row and column replicas.
- Repeated analytical queries: Your workload involves the same or similar analytical queries that benefit from compiled execution plans.
- Managed cloud services: You prioritize fully managed operations through SingleStore Helios and don’t need open-source flexibility.
- Strong vendor relationship: You’re comfortable with commercial licensing and building a long-term relationship with SingleStore as your database vendor.
When TiDB Is the Better Choice
TiDB clearly excels when your requirements include:
- Strong consistency guarantees: Your application requires linearizable reads and writes without eventual consistency windows.
- Predictable transactional performance: You need consistent OLTP latency even when heavy analytical queries are running.
- Unpredictable growth patterns: You want automatic sharding that adapts dynamically as data grows without pre-planning partition counts.
- Open-source governance: You value transparency, community development, and the ability to fork/extend the database if needed.
- MySQL migration path: You’re migrating from MySQL and need high compatibility with existing tools, connectors, and application code.
- Multi-region resilience: You need to deploy across geographic regions with strong consistency and automatic failover.
- Workload isolation: You want physical separation between OLTP and OLAP workloads to ensure analytical queries never impact transactional performance.
SingleStore vs TiDB: The Consistency Question, and Why It Matters More Than You Think
One of the most significant differences between SingleStore and TiDB—and one that’s often underestimated until it causes production issues—is their approach to consistency.
SingleStore’s asynchronous replication between primary and replica partitions means there are windows where replicas haven’t caught up to the latest writes. For many applications, this is acceptable. But for systems that require strict read-after-write consistency (financial transactions, inventory management, collaborative applications), this creates complexity. Developers need to reason about which nodes have seen which writes, potentially routing reads to specific primaries rather than load-balancing across replicas.
TiDB’s Raft-based consensus ensures that every write is committed to a majority of replicas before acknowledging success. This means you can read from any TiDB server or TiKV node and always see the latest committed state. There are no “stale reads” unless you explicitly opt into them for performance optimization. For applications being migrated from traditional RDBMS like MySQL or PostgreSQL, this consistency model feels natural and eliminates an entire class of bugs related to replication lag.
The trade-off? Strong consistency incurs some write latency overhead compared to asynchronous replication. But for most applications, the operational simplicity and correctness guarantees outweigh the minor performance difference, especially when you consider the cost of debugging consistency-related issues in production.
Migration Considerations: Moving to SingleStore vs TiDB
SingleStore provides various ingestion mechanisms including Pipelines for continuous loading from sources like Kafka, Spark streaming, and relational databases. For MySQL migrations, SingleStore offers partial compatibility with MySQL protocol and syntax, though teams should expect to review and potentially modify queries, stored procedures, and application logic that relies on MySQL-specific behaviors.
Key migration considerations for SingleStore:
- Assess whether your working dataset fits the memory-first model or requires extensive disk-based storage.
- Plan partition counts carefully at database creation, as changing them later requires careful coordination.
- Test how your query patterns perform with code generation—repeated queries benefit most.
- Validate that your application can handle eventual consistency for replicas if high availability mode is used.
- Budget for commercial licensing costs, including production and non-production environments.
Migrating to TiDB
TiDB offers comprehensive migration tools specifically designed for MySQL and MariaDB migrations:
- TiDB Data Migration (DM): Replicates data continuously from MySQL/MariaDB sources with full-database or table-level filtering, ideal for online migrations with minimal downtime.
- TiDB Lightning: Performs high-speed bulk imports from MySQL dumps, CSV files, or Parquet data, optimized for initial data loading.
- TiCDC: Provides change data capture for downstream systems, useful for gradual cutover scenarios or maintaining parallel systems during migration.
Because TiDB maintains high MySQL compatibility at the protocol, syntax, and behavior level, most applications work with minimal changes. Existing MySQL drivers, ORMs, and tools generally work out of the box. The migration path is well-documented, with extensive community experience and PingCAP support available for production migrations.
SingleStore vs TiDB Performance Realities: Beyond the Benchmarks
Both SingleStore and TiDB publish impressive benchmark numbers, but real-world performance depends heavily on your specific workload characteristics:
For SingleStore, peak performance typically comes from:
- Working sets that fit in memory with high cache hit rates.
- Repeated queries that leverage compiled execution plans.
- Workloads where analytical queries can tolerate some replication lag.
- Data patterns that benefit from hash partitioning distribution.
For TiDB, optimal performance characteristics include:
- Transactional workloads that benefit from strong consistency without application-level retry logic.
- Mixed OLTP/OLAP workloads where transactional latency cannot be compromised.
- Scalability requirements that exceed single-node capacity but don’t require aggressive memory overprovisioning.
- Workloads with unpredictable growth where automatic Region splitting prevents manual resharding.
The best approach? Benchmark your actual workload on both systems. Many teams find that while SingleStore may show better numbers for pure analytical queries on memory-resident data, TiDB delivers more predictable and consistent performance across mixed workloads with strong correctness guarantees.
Cost Considerations: Total Cost of Ownership for SingleStore vs TiDB
Comparing costs between SingleStore and TiDB requires looking beyond just database licensing:
SingleStore’s cost model includes:
- Commercial licensing fees based on deployment size and features.
- Infrastructure costs (compute and memory-heavy due to in-memory architecture).
- Storage costs for rowstore, columnstore segments, logs, and snapshots.
- Support and maintenance fees.
TiDB’s cost model includes:
- No licensing fees (open source), though commercial support is available.
- Infrastructure costs (balanced compute/memory requirements, can run on commodity hardware).
- Storage costs for TiKV replicas and optional TiFlash analytics replicas.
- Optional TiDB Cloud managed service fees (pay-as-you-go or reserved capacity).
For teams with large datasets that don’t fit entirely in memory, TiDB’s architecture can deliver lower infrastructure costs since it doesn’t require massive memory overprovisioning. The open-source nature also eliminates licensing fees entirely for self-managed deployments, though teams should factor in operational expertise requirements.
SingleStore vs TiDB: Making the Right Choice for Your Team
Both SingleStore and TiDB represent mature, production-proven distributed SQL databases with strong HTAP capabilities. The right choice depends less on which technology is “better” in the abstract and more on which aligns with your specific requirements, team capabilities, and long-term strategic direction.
Choose SingleStore if: You have memory-intensive analytical workloads that benefit from compiled query execution, you’re comfortable with commercial licensing and vendor lock-in, and your consistency requirements can tolerate eventual consistency for replicas. SingleStore’s unified storage model and managed cloud service provide a polished experience for teams prioritizing operational simplicity over open-source governance.
Choose TiDB if: You need strong consistency guarantees for distributed transactions, you’re migrating from MySQL and want high compatibility, you value open-source governance and community development, or you require predictable OLTP performance even when running heavy analytics. TiDB’s layered architecture, Raft consensus, and separation of OLTP/OLAP workloads provide operational advantages for teams managing complex, mission-critical applications.
For many organizations, the decision ultimately comes down to consistency guarantees and open-source flexibility. If your application requires linearizable reads and writes across a distributed system—without the complexity of reasoning about replication lag—TiDB’s architecture provides fundamental advantages. If your workload fits SingleStore’s memory-optimized profile and you’re comfortable with proprietary licensing, SingleStore delivers compelling performance for specific use cases.
The good news? Both technologies have successful production deployments at scale. The key is understanding your workload characteristics, team capabilities, and long-term architecture goals before making the commitment.
Want to see how TiDB compares for your workload? Start a free TiDB Cloud trial today.
FAQ: SingleStore vs TiDB
Which should I choose: SingleStore or TiDB?
If you prioritize memory-optimized analytics and a managed, proprietary experience, SingleStore can be a fit. If you need strong consistency, predictable OLTP latency alongside analytics, and an open-source option with a MySQL migration path, TiDB is the better default.
What is the biggest architectural difference between SingleStore and TiDB?
SingleStore centers on an aggregator–leaf cluster with Universal Storage (row + column in the same table type). TiDB uses a layered architecture: stateless SQL compute (TiDB), distributed transactional storage (TiKV), and optional analytics replicas (TiFlash).
How do SingleStore and TiDB differ on consistency?
SingleStore uses asynchronous replication between primaries and replicas, which can create eventual consistency windows. TiDB uses Raft consensus, committing writes to a majority before success, providing linearizable reads/writes by default.
How do SingleStore and TiDB handle sharding and scale-out over time?
SingleStore distributes data with hash partitioning, and the partition count is set at database creation (changes require planning). TiDB automatically shards into Regions that split and rebalance as data and load grow, without application-level shard management.
How do SingleStore and TiDB approach HTAP (OLTP + OLAP on fresh data)?
SingleStore’s Universal Storage keeps row + column formats within the same table model with background conversion. TiDB separates OLTP and OLAP via TiKV (row) and TiFlash (columnar replicas) to isolate analytical load from transactional latency.
How MySQL-compatible are SingleStore and TiDB, and what does migration look like?
SingleStore offers partial MySQL protocol/syntax compatibility and may require query/procedure changes. TiDB emphasizes high MySQL compatibility and provides dedicated migration tools like DM, Lightning, and TiCDC, often enabling minimal application changes.
Experience modern data infrastructure firsthand.



TiDB Cloud Dedicated
A fully-managed cloud DBaaS for predictable workloads
TiDB Cloud Starter
A fully-managed cloud DBaaS for auto-scaling workloads