Elevate modern apps with TiDB.
Delhivery is a leading Indian logistics and supply chain services company. It offers a comprehensive range of services, including express parcel delivery, freight, warehousing, and supply chain solutions, catering to a wide range of clientele.
With a vast network comprising over 85 fulfilment centers, 29 automated sort centers, 160 hubs, and more than 3,500 direct delivery centers, Delhivery handles over a million packages daily. This extensive operation generates terabytes (TBs) of data daily, necessitating a robust and scalable data architecture to maintain operational efficiency and support real-time decision-making.
The Challenge: Scaling Data Infrastructure for Real-Time Demands
As Delhivery expanded, its existing data infrastructure faced issues in managing the increasing data volume and complexity. The company recognized the need for a more efficient and scalable solution to ensure data integrity, low latency, and the capacity to handle both transactional and analytical workloads effectively.
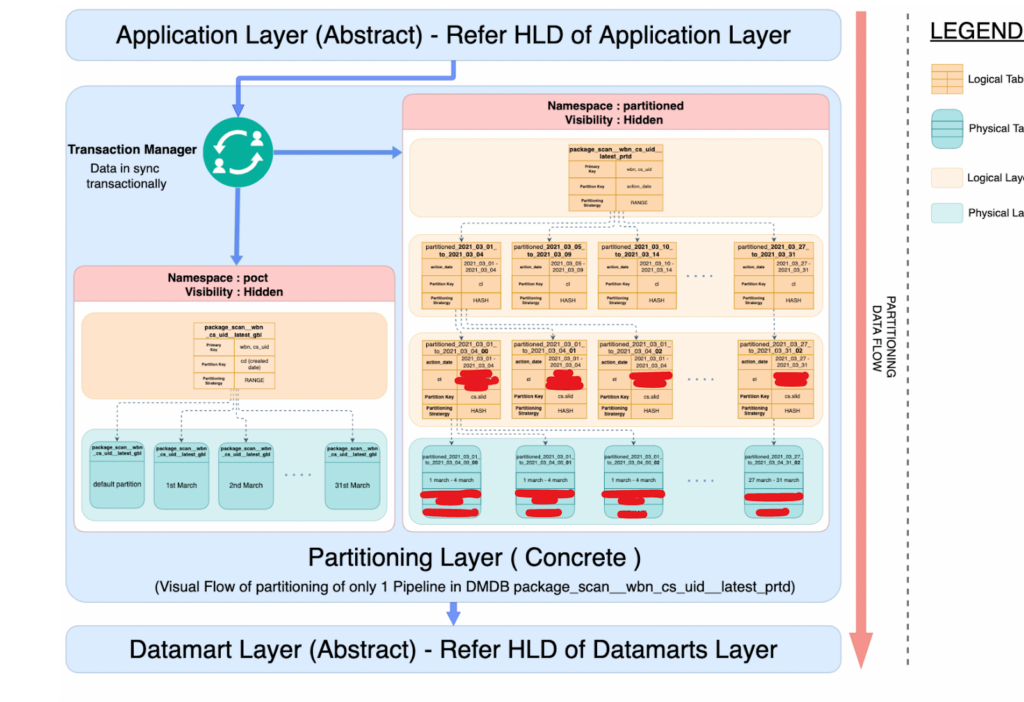
Figure 1: Multi-layered data marts architecture
Delhivery’s existing Amazon Aurora setup often encountered critical limitations that hindered growth and operational efficiency, including:
- Throughput Bottlenecks: Amazon Aurora struggled to handle write workloads exceeding 3,000 messages per second. This became a significant bottleneck as the volume of real-time data ingestion increased, directly impacting the speed and reliability of operational insights.
- Storage Bloating and Inefficiency: Amazon Aurora’s architecture led to excessive data bloating. Each update generated dead tuples—previous versions of records that consumed additional storage without being automatically reclaimed. For approximately 5 TBs of data, Amazon Aurora’s storage usage ballooned to over 30 TBs, leading to inefficient storage utilization and escalating costs.
- Manual Maintenance Overhead: PostgreSQL’s automatic cleanup processes, such as Auto Vacuum, could not keep pace with the rate of dead tuple generation. This necessitated frequent manual interventions. Managing over 70 pipelines with write QPS exceeding 5,000 messages/second became increasingly time-consuming and operationally complex.
- Soaring Costs: To accommodate growing read and write workloads, Delhivery had to deploy the highest available Amazon Aurora nodes (24XLarge). However, this solution resulted in exorbitant costs, with monthly expenditures reaching $100,000 for a three-node Amazon Aurora cluster.
- Limited Scalability for Real-Time Analytics: Amazon Aurora’s architecture was not optimized for transactional and analytical processing , a capability Delhivery required to support real-time operational dashboards and decision-making. This stopped them from getting timely insights from the data.
These challenges underscored the need for a more scalable, cost-efficient, and real-time analytics-friendly solution to meet Delhivery’s data mart requirements.
The Solution: Addressing Scalability and Efficiency with Distributed SQL
After thoroughly evaluating alternatives, including Google Spanner and YugabyteDB, Delhivery found the perfect fit in TiDB, a distributed SQL database designed for transactional and analytical processing. The decision to migrate was driven by TiDB’s ability to meet its operational demands and address the challenges with its previous setup. Here’s why TiDB stood out:
- Horizontal Scaling: TiDB’s architecture allows for seamless scaling, enabling Delhivery to easily handle high write QPS demands (10k+ transactions per second).
- Real-Time Transactional and Analytical Processing: TiDB allows Delhivery to generate real-time insights without separate OLAP and OLTP systems.
- Strong Consistency and High Availability: By utilizing the Multi-Raft protocol and storing data in multiple replicas, TiDB ensures strong consistency and resilience against hardware failures.
- Cost Efficiency: With TiDB’s storage optimization and transparent scaling capabilities, Delhivery could eliminate the high costs associated with Amazon Aurora’s IOPS scaling.
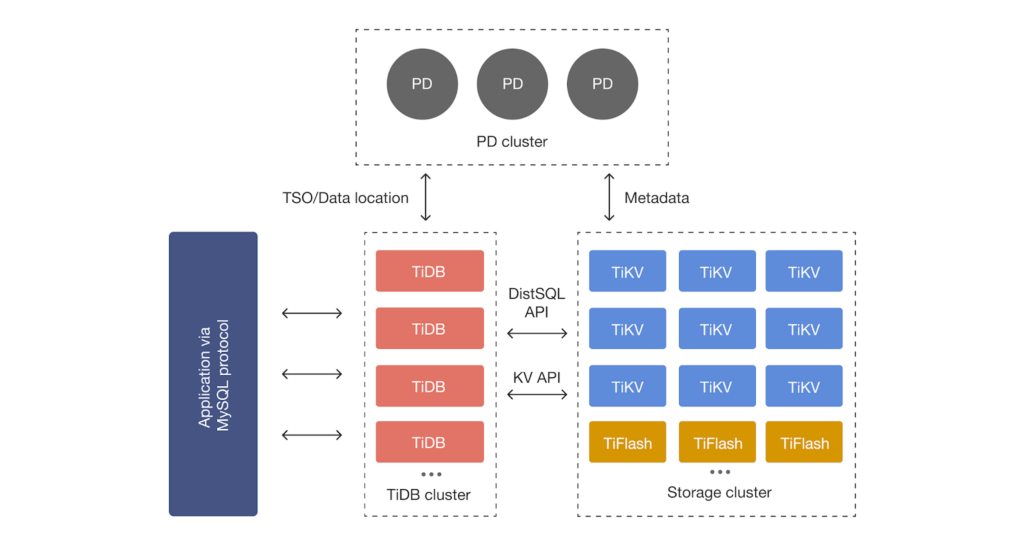
Figure 2: TiDB Architecture
To support their demanding workload, Delhivery deployed TiDB across three availability zones. The infrastructure includes:
- TiDB Server Nodes: The SQL layer that processes queries, balances workloads, and routes requests to the correct storage location.
- TiKV: A distributed storage engine ensuring strong consistency and horizontal scalability through the Multi-Raft protocol.
- TiFlash: A columnar store that enables real-time analytical processing on the same data without affecting transactional performance.
- Placement Driver (PD): The cluster manager that maintains metadata, coordinates data distribution, and ensures optimal resource usage.
Additionally, the following optimizations were implemented to maximize performance:
- Index Optimization: Parameters were tuned to streamline index creation, improving query efficiency.
- Partition Pruning: Filtering conditions were optimized to eliminate irrelevant query partitions, enhancing execution speed.
- Custom Analyze Settings: Adjustments ensured that auto-analyzers performed optimally, even with high data ingestion volumes.
The TiDB team fine-tuned these configurations, ensuring the deployment matched Delhivery’s unique requirements and operational scale. By adopting TiDB, Delhivery achieved a streamlined, future-ready data architecture capable of addressing current and anticipated demands.
The Results: How TiDB Redefined Delhivery’s Operations
Delhivery’s migration to TiDB brought significant improvements, including:
- Enhanced Query Performance: Over 400 queries were benchmarked, achieving SLA compliance with a 15-20% performance gain for P95 queries.
- Efficient Storage Management: TiDB’s architecture resolved bloating issues, dramatically reducing storage overhead while maintaining performance.
- Substantial Cost Reductions: Transitioning to TiDB eliminated the need for over-provisioning infrastructure, cutting database costs substantially compared to Amazon Aurora’s $100,000 monthly bill.
- Streamlined Data Migration: TiDB Lightning enabled the rapid migration of TBs of historical data within just 2-3 hours, minimizing downtime.
- Robust Support: Close collaboration with the TiDB team ensured successful tuning of the production cluster, optimizing it for Delhivery’s high-throughput workloads.
By adopting a distributed SQL architecture, Delhivery achieved substantial improvements in query performance, cost savings, and system reliability. These advancements have strengthened the company’s ability to process massive data volumes, deliver real-time insights, and maintain a top position in India’s fast-paced logistics industry.
