Elevate modern apps with TiDB.
Key Results
- 10x improvement in queries per second (QPS) under peak load.
- P95 latency sustained under 10 ms in simulated peak-load testing
- 100% online DDL with zero service disruption.
- Scaled beyond 300M-row MySQL limits with no manual sharding required.
Company Overview
Plaud is the a leading AI Note-taking brand by sales volume. More than 2 million users across 170 countries rely on Plaud to capture speech, convert it to text through AI-powered transcription, and retrieve that content through a mobile experience built for instant, accurate recall.
Every core user action runs through Plaud’s data layer: Registration, login, device pairing via Bluetooth, recording, transcription, template customization, and membership management. For a product whose entire value proposition is remembering what was said, the database is the product.
Growth arrived fast. Cumulative device shipments exceeded 700,000 units by 2024. By July 2025, that number surpassed one million across 170 countries. The architecture that served Plaud well at launch was hitting its limits at scale.
The Challenge: When the Architecture Argues with the Product
Plaud’s data architecture was designed for launch-stage simplicity, not global-scale AI workloads. Three interconnected problems emerged as the user base grew: A split-brain data model, a schema frozen in place, and a write-throughput ceiling that constrained the product itself.
A Split-Brain Architecture: Metadata in MySQL, Content in S3
Plaud’s original architecture separated data into two stores that were never designed to work together. Structured metadata (user accounts, authentication tokens, device pairings, membership tiers, order history, workflow configurations, and task logs) lived in MySQL. The actual product output, transcribed text from every recording session, lived in Amazon S3.
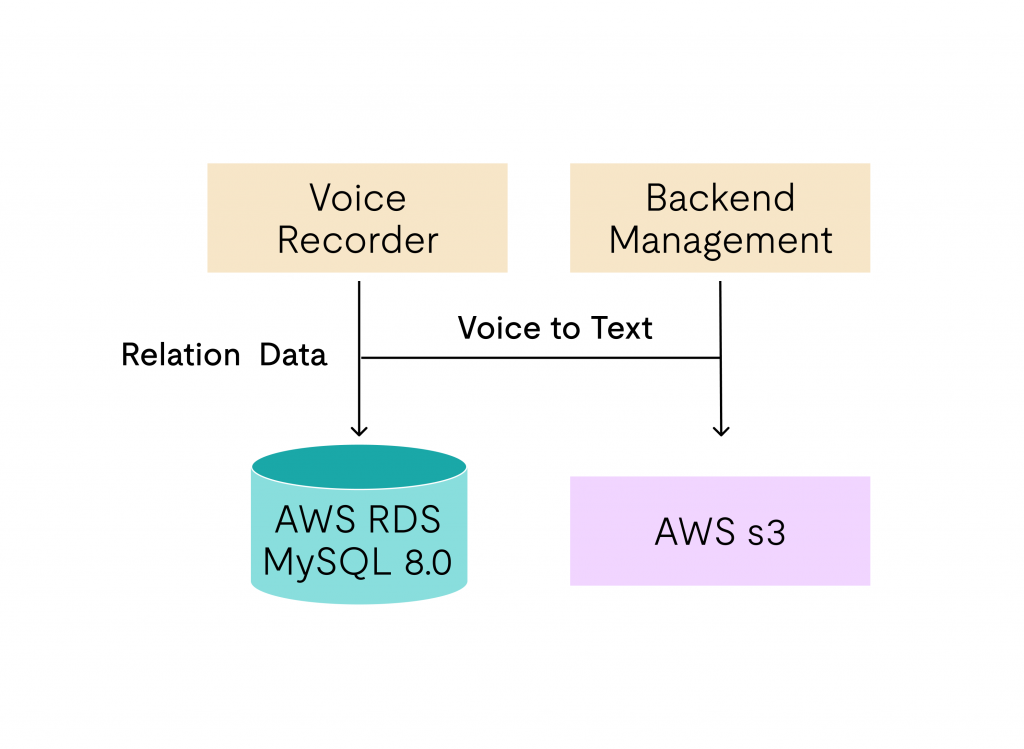
Fig. 1: Original data architecture
Voice-to-text transcripts are not small. Individual records can reach approximately 5 MB. Retrieving a 5 MB object from S3 on every user request is not a database query. It is a network fetch with object-storage overhead. Under normal load, retrieval was acceptable. Under high concurrency, S3 became the bottleneck, introducing long-tail latency that AI hardware users, who expect instant recall, experience as product failure.
The latency problem had a consistency partner. Every transcript edit required a coordinated write to MySQL and a write to S3: Two systems with no shared transaction guarantee. A partial failure left user data in an inconsistent state that the application layer had to detect and recover from. The approach was manageable at small scale but fragile in ways that compound as the user base grows.
300 Million Rows and a Schema-Change Moratorium
Plaud’s core tables had crossed 300 million rows. At that scale, MySQL DDL operations behave differently: Index creation locks tables, schema modifications interrupt online workloads, and in a 24/7 environment there is no safe maintenance window.
The result was a growing queue of schema changes, including new device capabilities, new transcription workflow types, and new compliance fields, all waiting behind the risk of taking the service offline to run them. MySQL’s DDL limitations were not just an operational inconvenience. They were slowing down the product roadmap.
The Write-Throughput Ceiling
MySQL’s primary-replica architecture bounds writes to a single primary node. As concurrent transcription requests multiplied, write throughput became the ceiling for how fast the product could respond. Replica lag introduced a secondary consistency problem: A user editing a just-transcribed recording might read stale data from a replica that had not yet caught up. That gap required another layer of application-level workarounds.
The Solution: TiDB Cloud as the Core Data Platform
Plaud migrated core business datasets to TiDB Cloud, including user information, authentication data, device configurations, membership and order records, voice-to-text task data, tags, workflow definitions, task execution logs, and operation logs.
The architecture that emerged is meaningfully simpler than what it replaced.
Before: MySQL for structured metadata + Amazon S3 for transcript blobs + application-layer coordination between the two, with associated consistency risks and S3 retrieval latency.
After: TiDB Cloud became Plaud’s core data platform, addressing limitations in the original MySQL architecture such as primary-replica lag, DDL locking risk, and scaling bottlenecks caused by growing request volume and data size.
The updated architecture gives Plaud a distributed SQL foundation for critical operational workloads, while the teams continue to evaluate additional data scenarios as part of the future roadmap.
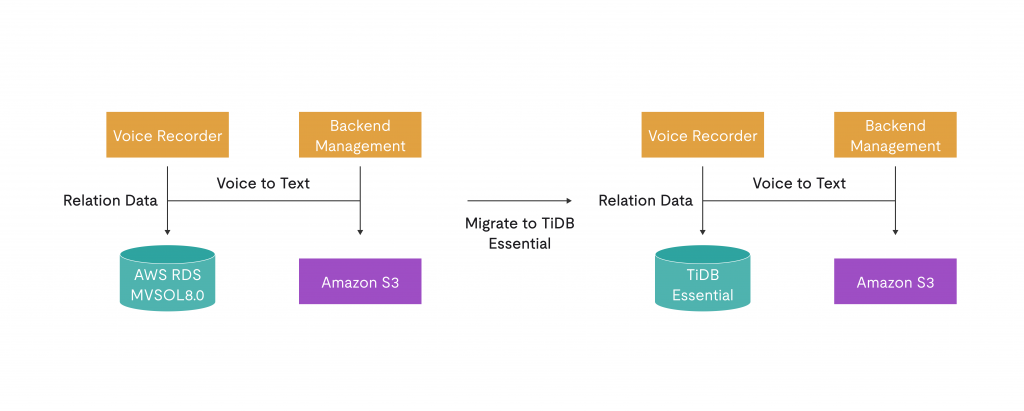
Fig. 2: New data architecture.
13 Clusters: Architecture for a Global AI Hardware Product
Plaud operates 13 TiDB Cloud clusters in production, segmented by business function and geographic region. Data-residency regulations in different jurisdictions drove the regional split. TiDB Cloud’s deployment model supports this without forcing Plaud to manage 13 entirely different database systems. The clusters share operational patterns, tooling, and monitoring infrastructure while maintaining independent data boundaries.
Online DDL in Production, All Day
The schema freeze is over. TiDB’s online DDL capability allows Plaud to run schema changes on live traffic without interrupting reads or writes. New device capabilities, new workflow types, and new compliance fields ship on the product’s timeline, not the database’s maintenance schedule. For a hardware company pushing new firmware and features continuously, that is a material change in engineering velocity.
Stress-Tested and Validated: 10x QPS, P95 Under 10 ms
Before cutting over, Plaud’s engineering team validated the new architecture under simulated peak load. Stress testing confirmed a 10x improvement in QPS compared to the previous MySQL setup, with P95 latency sustained below 10 milliseconds. These numbers represent Plaud’s expected peak traffic for the foreseeable future. The architecture has room to grow without requiring a rethink.
Results
Latency. Stress testing showed that the updated architecture can sustain P95 latency below 10 ms under simulated peak load, giving Plaud a more responsive foundation for critical business workloads.
Throughput. Stress testing validated a 10x QPS improvement under peak conditions, with P95 latency held under 10 ms. The architecture is sized for Plaud’s next order-of-magnitude growth without manual sharding or architectural rework.
Consistency. By moving core business datasets into TiDB Cloud, Plaud reduced the application-level complexity associated with the previous MySQL architecture and gained a stronger transactional foundation for critical operational data.
Schema agility. 100% of DDL operations now run online. The schema-change queue that had accumulated due to DDL risk in MySQL has been cleared. Plaud’s engineers ship database-touching features on product timelines, not maintenance windows.
Operational scale. As of March 2026, Plaud runs 13 TiDB Cloud clusters in production across business and regional segments, deployed ahead of the original target timeline.
TiDB solved the scalability and schema change risks we had with MySQL. It delivers elastic scaling throughout the entire process without any disruption and that gives us the foundation to keep growing.
– Yang Xiaobo, Development Engineer, Plaud
What’s Next
Plaud’s user base continues to grow. With more than one million devices shipped and a global user community across 170 countries, data volumes in each cluster will keep increasing.
The team is also positioned to explore TiDB’s analytical capabilities as Plaud’s AI workflows mature. As transcription data accumulates at scale, the ability to run analytical queries directly against operational data, without a separate data-warehouse pipeline, becomes increasingly valuable for product insights, quality monitoring, and personalization features.
Outgrowing your current database architecture? See what TiDB Cloud can do for your infrastructure. Get started for free.