
Elevate modern apps with TiDB.
When it comes to money laundering, many people believe it only happens in movies and TV shows. However, it can occur in our daily lives through various channels like art deals, cross-border investments, gambling, and securities trading. Anti-money laundering (AML) refers to the measures taken to prevent the concealment of the origins of illegally obtained money.
Banks are increasingly moving their services online, and becoming more digital and intelligent. With stricter regulations, financial institutions face significant challenges in their AML efforts. These include verifying customer identities, keeping detailed transaction records, monitoring and reporting suspicious activities promptly, and conducting regular risk assessments. Some specific challenges include:
A top global bank’s original AML business system that was built on multiple data technology stacks and heterogeneous databases, faces issues such as high development and maintenance costs, inadequate mixed OLTP and OLAP processing capabilities, lack of large-scale elastic storage and high availability, and poor data timeliness. To address these problems, the bank reconstructed a global AML system based on the domestic HTAP distributed database TiDB. This system innovatively integrates stream computing with batch processing, supports high-concurrency data access and online interactive multi-dimensional queries, achieves the integration of multiple technology stacks, and ensures business continuity.
The Real-time Anti-Money Laundering (AML) System primarily focuses on real-time monitoring of customer-initiated transactions. It receives transaction requests from upstream online systems through interfaces, registers them, and performs real-time rule set matching (such as cumulative transaction amounts and counts involving customer-submitted transactions and historical transactions). If a match occurs, case information is generated, and the processing result is returned to the caller in real-time. This system is classified as a critical business system (with 5 data replicas) and includes a disaster recovery cluster setup. The Real-time AML Business includes both online and batch operations, and from a business perspective, it includes modules such as customer due diligence and transaction due diligence.
Customer Due Diligence involves data tables including a customer information table with 600 million entries, a customer rating history table with tens of billions of entries (6 years of historical data), and a case table (with 1 billion entries). There are approximately 700,000 daytime transactions, involving insertion or updating of the customer information table based on customer dimensions. The batch-to-online mode is processed as an online interface, with potentially high instantaneous concurrency, primarily involving operations based on customer ID dimensions. This includes insert and update operations on the customer information table, as well as using the case table as a driving table for joining with multiple other tables. The batch calculation functionality computes result sets based on transaction records, the merged customer information table, and other tables through associations. It involves multiple calculation dimensions, potentially expanding the result set, with the expectation of completion within the same day.
Transaction Due Diligence involves data tables primarily including transaction tables, case tables, interception information tables, and behavior-type message tables (with data scales in the hundreds of millions, with behavior-type tables having even larger data volumes). Business functions include providing tellers with write and update operations for the interception information table; offering flexible data queries to tellers, involving multi-table joins, including paginated queries in form format, and primarily light AP-type aggregate queries.
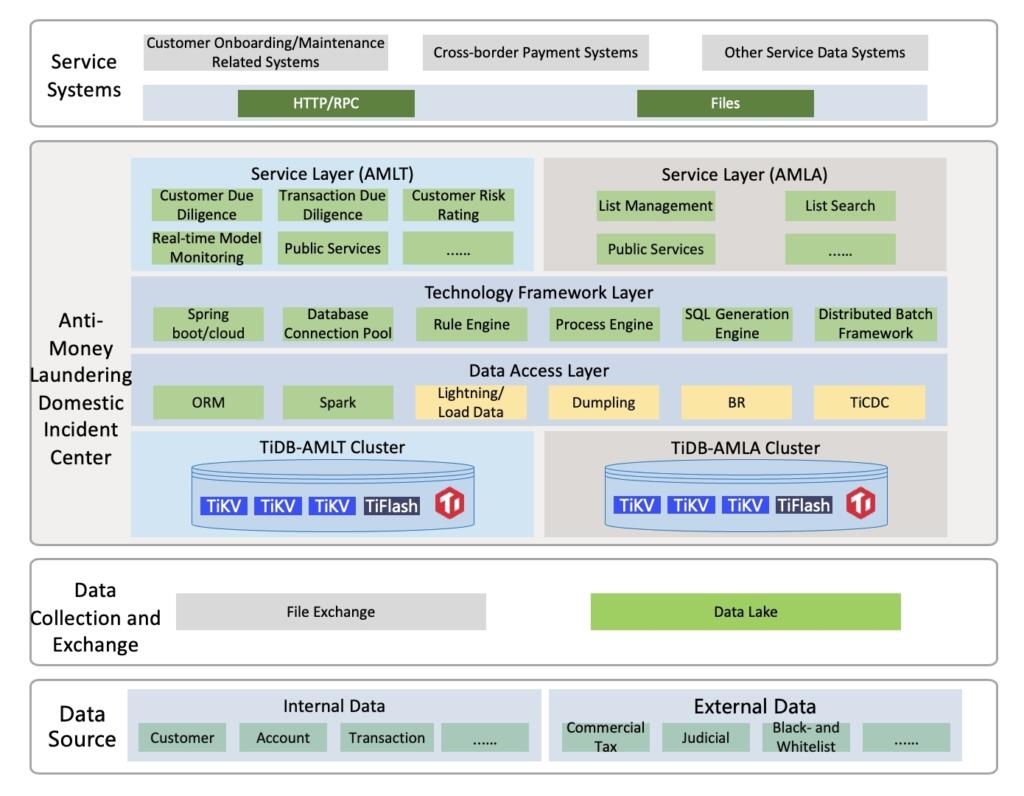
As shown in the figure above, the domestic real-time anti-money laundering component is vertically divided into online transactions and batch analysis parts according to business domains. Each part corresponds to an independent TiDB distributed database cluster. Each cluster includes two storage engines–TiKV for row storage and TiFlash for column storage.
The bank deploys the TiDB main cluster across data centers in City A, with a disaster recovery cluster in City B. The main cluster adopts a 3+2 deployment mode across two data centers in the same city.
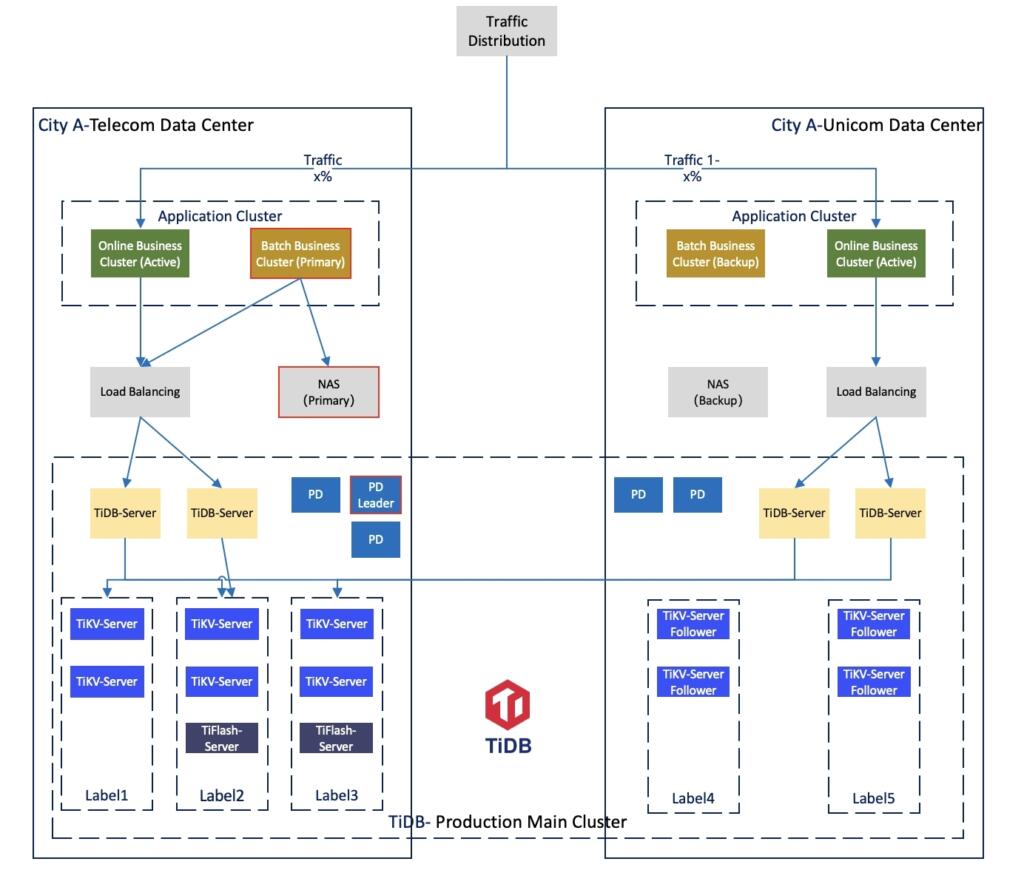
The new generation anti-money laundering business system interfaces with nearly a hundred upstream and downstream systems across the bank, storing hundreds of terabytes of data. While supporting daily incremental data of hundreds of millions of transactions and tens of millions of T+0 real-time queries, it achieves ultra-long span queries and a more complete and accurate panoramic view of transactions. This significantly enhances the comprehensive data service capabilities and customer experience in the mobile internet era, providing round-the-clock, diverse, and highly time-efficient services.
Key benefits include:
In summary, the new AML system, powered by TiDB, significantly improves the bank’s ability to detect and prevent money laundering, ensuring compliance with regulations and enhancing operational efficiency.

Elevate modern apps with TiDB.