TiDB vs CockroachDB (2026) Comparison Guide for Platform Teams

Jump to a Section
Updated March 4, 2026 | Author: Brian Foster (Content Director) | Reviewed by: Ben Sherrill (Senior Solutions Engineer)
TiDB is a MySQL-compatible distributed SQL database built on TiKV with an HTAP database path via TiFlash, designed to scale out without manual sharding while preserving MySQL compatibility. CockroachDB is a distributed SQL database with strong Postgres ecosystem alignment and a multi-region-first positioning, typically evaluated by teams standardizing on Postgres-compatible tooling.
Verdict: For platform teams outgrowing single-node SQL, both offer distributed SQL with ACID transactions. Choose TiDB if you are MySQL-first and need scale-out writes and storage without application-owned sharding, with an optional HTAP path via TiKV + TiFlash. Choose CockroachDB if you are Postgres-first and your priority is multi-region locality. Validate SQL/feature differences and tail latency in a POC.
Choose TiDB if…
- MySQL compatibility is non-negotiable and you want to preserve existing drivers, ORMs, and operational workflows with minimal rewrites.
- You need scale-out writes and storage without application-owned sharding, so growth is handled by adding nodes instead of building shard routing and resharding into your application.
- You want an HTAP path (TiKV + TiFlash) to run analytics on fresh OLTP data and reduce ETL lag.
Choose CockroachDB if…
- You require PostgreSQL wire protocol compatibility and your entire ecosystem is Postgres-first.
- You specifically need SERIALIZABLE isolation semantics.
- You want single-cluster multi-region locality or are targeting 99.999 availability within a single cluster and are willing to accept the coordination and latency tradeoffs that come with that architecture.
Run a POC that explicitly tests…
- Contention-heavy transactions, hotspot behavior, failure scenarios, and p95/p99 latency in your target topology.
Key Takeaways (TiDB vs CockroachDB):
- Compatibility: Choose TiDB for MySQL protocol + common syntax; choose CockroachDB if your ecosystem is Postgres-first (drivers/ORMs/tooling).
- Scale-out without app sharding: Choose TiDB if you want to scale writes and storage without introducing shard routing in the application.
- Analytics / HTAP: Choose TiDB if you want an HTAP path using TiFlash to reduce ETL lag and dual-system complexity for operational analytics.
- Multi-region: Choose CockroachDB if multi-region locality is a core requirement, and you accept the latency and cost tradeoffs of cross-region coordination.
- Evaluation rule: In both cases, treat topology as part of the product requirement and run a POC that measures correctness and tail latency under contention, hotspots, and failure drills.
TiDB vs CockroachDB: Side-by-Side Comparison
| Criteria | TiDB | CockroachDB |
|---|---|---|
| Primary use | Distributed SQL / NewSQL for scale-out OLTP; MySQL-compatible; optional HTAP via TiFlash on TiKV | Distributed SQL with Postgres ecosystem alignment; commonly used for scale-out OLTP and geo-distributed patterns |
| SQL / protocol compatibility | MySQL protocol + common MySQL syntax; validate edge cases in a POC | Postgres wire-compatibility focus; validate SQL dialect/feature differences in a POC |
| Consistency & distributed transactions | ACID transactions with strong consistency; supports distributed transactions (validate isolation semantics for your workload) | ACID transactions in a distributed system; confirm isolation/serialization expectations, retries, and contention behavior for your workload |
| Scaling model | Horizontal scaling SQL database: add nodes; separate compute (TiDB) from storage (TiKV/TiFlash); distribution handled by the cluster | Horizontal scale-out design; distribution and rebalancing handled by the system (validate operational knobs and workload behavior) |
| HTAP database capability | TiFlash columnar replicas for mixed OLTP + OLAP on fresher operational data | Analytics often handled via external OLAP patterns; some teams use materialized views / downstream systems depending on needs |
| Multi-region database patterns | Multi-region patterns exist; tradeoffs depend on locality goals and cross-region consensus latency | Multi-region patterns are a core evaluation dimension; tradeoffs depend on locality configuration and write-path constraints |
| Operations & reliability | Self-managed (VMs/Kubernetes) or managed via TiDB Cloud; HA behavior depends on topology and runbooks | Self-managed and managed offerings exist; evaluate upgrades, backups, and operational ergonomics for your org |
| Implementation / migration surface area | MySQL compatibility reduces rewrite scope for MySQL apps; still validate SQL/feature edge cases | Postgres ecosystem fit can reduce friction for Postgres apps; still validate SQL/feature edge cases |
| Pricing model & cost drivers | Cost drivers vary by topology; model equivalent availability and region assumptions | Cost drivers vary by topology; model equivalent availability and region assumptions |
What This Guide Covers
- Overview
- Key Differences
- Architecture
- MySQL Compatibility
- Consistency & Transactions
- Scaling & Performance
- HTAP / Analytics
- Multi-Region
- Operations & Reliability
- Ecosystem & Integrations
- Implementation / Migration
- Pricing
- Pros & Cons
- Who Should Choose Which?
- FAQs
TiDB vs CockroachDB Overview: 2-Minute Summary
Before diving into architecture and benchmarks, it helps to define each database in plain language and clarify when this comparison actually matters for platform teams.
TiDB in Brief
TiDB is a Distributed SQL / NewSQL database from PingCAP that preserves MySQL compatibility while scaling out writes and storage. Under the hood, TiKV provides distributed transactional storage and TiFlash can add an HTAP database path for analytical queries on fresh operational data.
CockroachDB in Brief
CockroachDB is a distributed SQL database that aligns strongly with the Postgres ecosystem (via Postgres wire-compatibility) and is often evaluated for resilience and geo-distributed patterns. In practice, teams validate SQL compatibility, transaction behavior under contention, and operational ergonomics for their specific workload and topology.
When This Comparison Matters
This comparison becomes high-stakes when you are outgrowing single-node SQL, you have real multi-region requirements, you need ACID transactions and distributed transactions at scale, and you want to avoid the operational burden of manual sharding.
Key Differences: TiDB vs CockroachDB - What Buyers Should Know First
These are the buyer-level decision drivers that most often determine the “right fit” before you get into deep tuning, because they shape migration scope, operational overhead, and the tradeoffs you will live with at scale.
MySQL Compatibility vs Postgres Wire-Compatibility Tradeoffs
If your application and tooling are MySQL-native, TiDB’s MySQL protocol compatibility can reduce rewrite scope and shorten a POC. If your org standardizes on Postgres drivers/ORMs and Postgres-centric SQL features, CockroachDB’s Postgres wire-compatibility may reduce integration friction, but you still validate dialect and feature edge cases either way.
HTAP Path: TiFlash vs External Analytics Patterns
If you want operational analytics on fresh data without standing up and syncing a separate OLAP system for every use case, TiDB’s TiFlash-based HTAP path can be a decisive simplifier. If your analytics stack is already well-defined (warehouse/lake) and you prefer strict separation, CockroachDB is often paired with external analytics patterns rather than an in-database HTAP replica.
Scaling Approach: Partitioning vs ‘No Manual Sharding’ Operational Reality
Both systems aim to scale horizontally, but you should evaluate what you actually manage day to day: hotspot handling, rebalancing behavior, and whether scaling forces application-owned sharding logic. The operational reality is what matters more than the marketing phrase.
Distributed Transactions & Consistency Model Differences
Both databases provide ACID transactions, but the “feel” in production can differ depending on transaction coordination, retries under contention, and failure-mode behavior. The buyer takeaway is simple: you test correctness and latency under the exact failure domains you plan to run.
Multi-Region Database Design: Locality, Latency, and Write-Path Constraints
Multi-region is never free. Cross-region consensus and locality goals will shape latency, cost, and what “writes everywhere” realistically means. Treat topology as a first-class part of the evaluation, not an afterthought.
Operational Model: Self-Managed vs Managed Service Expectations
If your team wants to minimize operational labor, the managed-service path (and its limits) matters as much as database internals. Compare what “managed” actually includes: upgrades, backups, observability, and support boundaries.
Architecture Deep Dive
Architecture is the reason the tradeoffs show up in the first place, so this section focuses on the core mental models that explain scaling behavior, failure recovery, and mixed-workload performance.
TiDB Architecture: Compute + Storage Separation
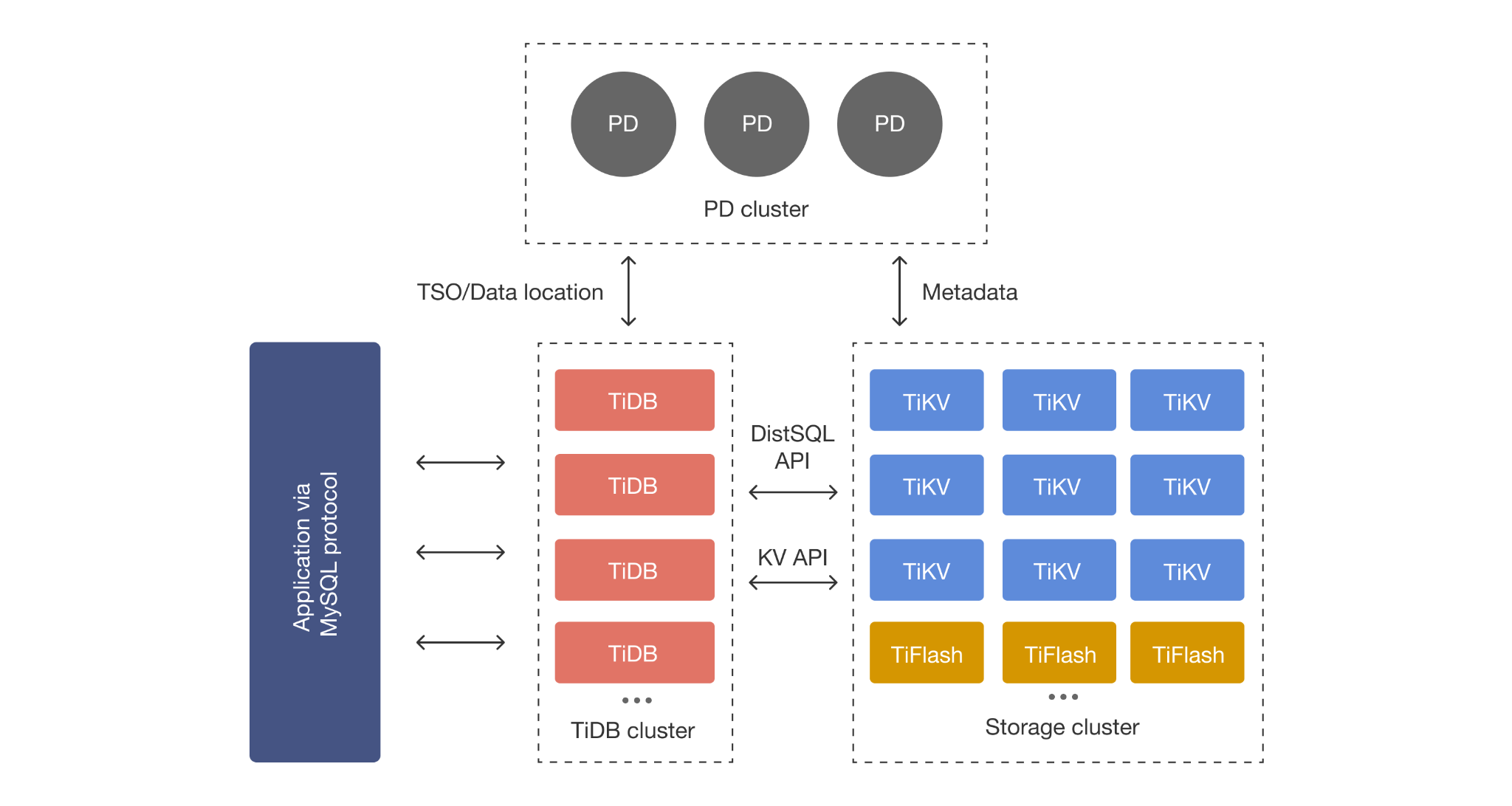
TiDB separates SQL compute from storage. The SQL layer scales by adding stateless nodes, while TiKV scales storage and transactional throughput independently. When you need HTAP, TiFlash adds columnar replicas so analytical scans can run without turning your OLTP path into your analytics engine.
CockroachDB Architectur
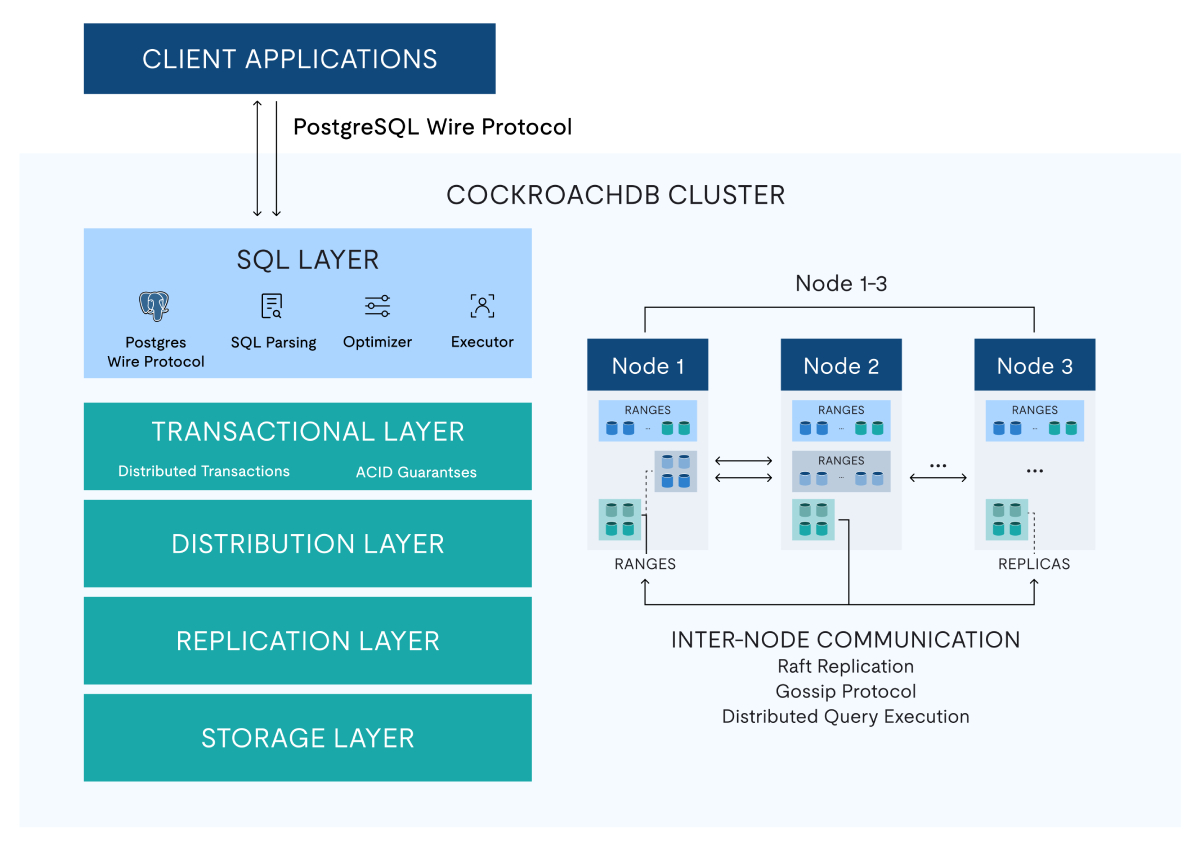
CockroachDB uses a distributed SQL architecture designed to keep data replicated and available across nodes. For a POC evaluation, the practical architecture questions are how data is distributed, how rebalancing behaves under skew, and how consistency and transaction coordination impact latency in your target topology.
Elasticity: Decoupled Components vs Co-Located Nodes
One of the most practical architectural differences is elasticity. TiDB’s separation of compute and storage lets teams scale SQL compute and storage/throughput more independently. In node-centric architectures where compute and storage are more tightly coupled, scaling decisions can require adding capacity that includes both, which can lead to overprovisioning if your bottleneck is mostly one dimension.
Timestamp Ordering: PD-based TSO vs Hybrid Logical Clocks (HLC)
Timestamp architecture matters when you evaluate contention behavior and commit latency. TiDB uses PD-based TSO to generate globally ordered timestamps quickly for transaction ordering. CockroachDB uses a Hybrid Logical Clock (HLC) approach that blends physical and logical time across nodes. The key buyer takeaway is not “which is better in theory,” but how each approach behaves in your topology, especially when you introduce multiple regions and tolerate clock uncertainty and coordination.
Storage Engine: RocksDB (TiKV) vs Pebble (CockroachDB)
Storage engine choices influence write amplification, compaction behavior, and tail latency under sustained load. TiDB’s TiKV is built on RocksDB, a mature LSM-tree storage engine widely used for high write throughput workloads. CockroachDB uses Pebble, an LSM engine designed specifically for CockroachDB’s architecture. This is not a “winner” bullet, but it is useful context when you are interpreting compaction-related latency spikes and long-running throughput tests.
What Architecture Means for Real Workloads
The under-the-hood design shows up as real-world behavior: hotspot sensitivity, cross-node transaction overhead, recovery behavior during failures, and the operational complexity of keeping latency stable as the cluster grows.
Compatibility: MySQL Compatibility vs Postgres Ecosystem
Compatibility is where migration risk lives, so this section makes compatibility concrete for app teams: drivers, ORMs, SQL dialect, and the “not always 100% drop-in” reality that a good POC should surface early.
TiDB: MySQL Compatible Distributed Database
TiDB is built to preserve the MySQL developer experience for the common path: SQL syntax, drivers, and tooling. What you validate in practice are MySQL-specific features you rely on, edge-case semantics, and performance behavior under your concurrency and data distribution.
CockroachDB: Postgres Compatibility
CockroachDB is commonly evaluated by Postgres-oriented teams because of Postgres wire-compatibility. A realistic POC still tests SQL feature compatibility (especially around complex queries and schema features) and confirms driver/ORM behavior under load and retries.
Practical Migration Checklist
A POC checklist that catches most surprises looks like this:
- Schema and index patterns (including large tables and hot keys).
- SQL features your app depends on (constraints, generated columns, specific functions).
- ORM behavior and connection pooling assumptions.
- Operational workflows (backups, restores, upgrades, incident drills).
Consistency, Isolation, and ACID Transactions: Distributed Transactions Explained
Platform teams want confidence around what ACID guarantees mean in a distributed system, what changes under contention, and what to explicitly test before production traffic moves.
Isolation Levels at a Glance (TiDB vs CockroachDB)
Because isolation semantics directly affect application correctness (especially under contention and retries), it’s worth clarifying the isolation levels each system supports before you interpret benchmark results or migration effort.
- TiDB supports:
* READ COMMITTED
* REPEATABLE READ (implemented as Snapshot Isolation)
- CockroachDB supports:
* SERIALIZABLE (default)
* READ COMMITTED
- Not supported today (both):
* READ UNCOMMITTED
If your application depends on a specific isolation guarantee (for example, strict SERIALIZABLE behavior or MySQL-style REPEATABLE READ expectations), validate it early in the POC using your real transaction patterns and contention scenarios.
Transaction Modes Under Contention (Optimistic vs Pessimistic)
Isolation level is only part of the story under contention. When you evaluate concurrency behavior, it also helps to know that both TiDB and CockroachDB support optimistic and pessimistic transaction modes, which gives teams levers to tune how the database behaves when many transactions compete for the same rows.
Optimistic approaches can perform well when conflicts are rare, while pessimistic approaches can reduce wasted work when conflicts are frequent. The right choice depends on your workload’s conflict rate, transaction length, and tail-latency goals, so it’s worth testing both modes during the POC on your most contention-heavy paths.
TiDB ACID Transactions at Scale - Distributed Transactions Basics
TiDB supports ACID transactions in a distributed cluster, which means transaction coordination can span nodes and failure domains. The practical evaluation focus is correctness under failures, latency under contention, and the retry/timeout behavior your application will experience. Learn more: ACID transactions in a distributed SQL database (TiDB).
CockroachDB Transaction Model Overview
CockroachDB provides ACID transactions as well, and teams typically evaluate the transaction model by testing contention-heavy patterns, long transactions, and how the system behaves during node or region disruptions. The point is not to assume a difference, but to measure what your application actually experiences.
What to Test in a POC
A reliable POC test plan includes:
- Correctness checks under cross-node failures and leader changes.
- Retries, timeouts, and idempotency assumptions in the app layer.
- Hotspot behavior (skewed keys, bursty writes).
- Long transactions and backfills (lock time, tail latency).
Scaling & Performance: Horizontal Scaling Without the Headaches
This section is about how scaling really feels in production: What happens when you add nodes, how hotspots and rebalancing affect latency, and when “database sharding” or “database partitioning” shows up as an operational responsibility.
TiDB Scale-Out Model: Horizontal Scaling SQL Database
TiDB scales out by adding stateless SQL compute and scaling storage/throughput via TiKV. The useful question for buyers is whether scaling is mostly a capacity action (add nodes) or an application redesign action (introduce shard routing and resharding).
CockroachDB Scale-Out Model
CockroachDB also scales horizontally, and the practical evaluation focuses on rebalancing behavior, hotspot handling, and how performance changes as data distribution shifts. Treat this as a measurement exercise with your workload, not a theoretical debate.
Schema Object Scale: Tables, Indexes, and Tenancy Footprint
At scale, “how many objects does the cluster need to manage?” becomes a real constraint, especially in multi-tenant designs with many tables and indexes. Make schema footprint part of your evaluation by testing not just a single large table, but the real number of tables, indexes, and schema objects your platform will carry, plus the operational workflows that create/alter them over time.
Hot Lookup Tables: Cached Tables vs General Block Cache
For read-heavy workloads, small lookup tables often sit on the critical path. TiDB supports cached tables patterns for small, frequently accessed tables to reduce read latency and avoid repeated storage lookups. CockroachDB relies on its general block cache behavior rather than an explicit “cache this whole table” control, so the right question is whether your lookup-heavy paths stay stable under production concurrency and churn.
Resource Management: Workload Isolation Controls vs Admission Control
Contention is not only a data problem. It is also a resource scheduling problem under saturation. TiDB provides resource control mechanisms that let teams define workload isolation policies (e.g.,, separating critical OLTP from background jobs). CockroachDB uses admission control to protect cluster stability under overload. Both approaches can help, but they are different levers, so validate which model better matches your operational goals and tenant isolation requirements.
Sharding vs Partitioning: What You Manage vs What the DB Manages
Database sharding is when the application or ops layer owns data distribution (routing, resharding, cross-shard query patterns). Database partitioning is a way to segment data to improve manageability or pruning, but it does not automatically remove distributed-systems coordination costs. If you want a crisp explainer on when sharding becomes a trap, read: Database sharding explained (and when to avoid it).
Benchmarking Guidance: How to Compare Fairly
To avoid “benchmark theater,” compare both databases using:
- Your real schema, indexes, and query mix
- Production-like concurrency and connection behavior
- Tail latency (p95/p99), not just average latency
- Failure-mode tests (node loss, region disruption, network blips)
- Cost modeling tied to replicas, regions, and egress
Mini Benchmark Rubric
Compare both databases on your schema and query mix, using production-like concurrency and topology, then validate tail latency and failure behavior (not just averages).
A. Inputs (define these before you run anything):
- Workload shape: Read/write ratio, peak QPS, burst profile, background jobs (backfills, ETL, reporting).
- Data shape: Total size, growth rate, hot keys or skew, largest tables, index footprint.
- Topology: Regions/zones, replication factor, expected failover domain (node, AZ, region).
- Client behavior: Connection pool settings, retry/timeout policy, idempotency assumptions.
B. What to measure (capture as a scorecard per scenario):
- Latency: p50/p95/p99 by query class (critical read paths, critical write paths, background jobs).
- Throughput & errors: Sustained throughput at SLO, error rate, retry rate, timeouts, deadlocks/serialization retries (as observed by the app).
- Hotspots & contention: Worst hot-key behavior, queueing, lock time, tail latency under contention-heavy transactions.
- Operational events: Tail latency during (1) scaling/rebalancing, (2) online schema change, (3) backup/restore drill.
- Failure drills: Node loss, AZ loss, “network blip,” leader/lease transfers; confirm SLOs still hold.
C. Scenarios to run (minimum viable, but honest):
- Steady-state load at expected peak concurrency.
- Hot-key burst (skewed writes + read-after-write).
- Large-table online DDL during traffic.
- Controlled failure drill during load (node/AZ).
D. Common traps (how “benchmark theater” happens):
- Measuring averages only and ignoring p95/p99.
- Using a dataset too small to surface hotspots, rebalancing behavior, or compaction effects.
- Mismatching topology (regions/replicas) so cost and latency are not comparable.
- Ignoring app-layer retries/timeouts (the database “looks fine” until production traffic).
- Not including operational workflows (DDL, upgrades, restore drills) in the test plan.
HTAP / Analytics: Real-Time OLTP + OLAP on Fresh Data
HTAP is not a buzzword for buyers. It is a practical question about whether you can run analytical queries on fresh operational data without duplicating datasets into more systems and pipelines.
TiDB HTAP with TiFlash
TiDB supports an HTAP path by using TiFlash columnar replicas alongside TiKV. The buyer-level benefit is reducing ETL lag for operational intelligence use cases where “freshness” matters and duplicating data increases cost and attack surface. Learn more: HTAP database fundamentals and TiDB HTAP use cases.
CockroachDB Analytics Approaches
CockroachDB teams often use a mix of approaches depending on workload: selective in-database techniques (for example, materialized views where appropriate) and external OLAP systems when analytical concurrency or scan-heavy workloads should be isolated from OLTP.
Common HTAP Use Cases to Compare
Use cases that make HTAP worth evaluating include:
- Fraud/risk signals that depend on the newest transactions.
- Operational intelligence dashboards during incidents.
- Real-time reporting where ETL lag changes decisions.
Multi-Region Database Reality Check: Latency, Locality, and Tradeoffs
Multi-region database design is always a set of tradeoffs. The goal is to name the topology you actually need (single-region HA, multi-region reads, or multi-region writes) and then test the latency and consensus implications honestly.
Common Multi-Region Topologies and Which Teams Need Them
Most teams fall into one of these patterns:
- Single-region HA: tolerate a region-wide outage via DR, but optimize for low latency.
- Multi-region reads: keep reads closer to users, accept write-path constraints.
- Multi-region writes: require global write availability, accept higher coordination latency and cost.
TiDB Multi-Region Patterns
TiDB can be deployed with multi-region goals, but you should describe (and test) supported patterns conservatively: how replicas are placed, how reads are routed, and what happens to latency when coordination spans regions. The most important outcome is aligning topology to your user locality and failure assumptions.
CockroachDB Multi-Region Patterns
CockroachDB is often evaluated for multi-region use cases, and the key buyer questions are similar: how you configure locality, how writes coordinate across regions, and what tail latency looks like during failover and degraded states. Validate with your own traffic distribution and SLA targets.
Decision Rule: When “Multi-Region” Becomes a Requirement vs a Nice-to-Have
If “multi-region” is primarily about resilience, single-region HA plus tested DR may be enough. If “multi-region” is about user latency and regulatory locality, treat it as a core product requirement and evaluate the write path and cost tradeoffs early.
Operations & Reliability: Upgrades, Backups, and Online Schema Change
Ops friction is a BOFU deal-breaker, so this section focuses on the work you will repeatedly do in production: online schema change, upgrades, backups/PITR, and day-2 observability.
Zero-Downtime Schema Changes: Online DDL
Schema change is where downtime sneaks in. Your evaluation should include online schema change behavior under load, how long it takes on large tables, and what operational guardrails exist. If you want a baseline framing for online DDL (sometimes written as “online dll”), see: Online DDL / online schema change with zero downtime.
Upgrades and Maintenance Windows - What to Expect
“Managed” does not automatically mean “no downtime.” Compare upgrade workflows, rollback strategy, and what your team is responsible for in the worst-case scenario (failed upgrade, partial outage, or degraded performance).
Backup/Restore, PITR, and Disaster Recovery Considerations
Even if you rarely restore, restore speed and procedure clarity determine RPO/RTO when incidents happen. Make backup verification (restore drills) part of the POC, not a post-launch checkbox.
Observability and Day-2 Operations Checklist
A production-ready checklist includes metrics and alert coverage for tail latency, hotspots, replication/raft health, node saturation, and error rates, plus runbooks your on-call team can execute under pressure.
Ecosystem & Integrations: Kubernetes, Data Movement, Tooling
Beyond core database features, day-to-day success depends on how well the system fits your platform: deployment patterns, CDC/data movement, and tooling that your developers and operators already rely on.
Deployment Patterns
Compare self-managed expectations (operational labor, runbooks, SRE maturity) to managed service boundaries (what the provider does vs what you own). If Kubernetes is your standard platform, explicitly evaluate how the database lifecycle fits GitOps workflows.
Data Movement & CDC
Most real architectures need streaming, pipelines, and downstream consumers. Validate CDC ergonomics, connector maturity, and how you handle schema evolution in pipelines.
Developer Tooling and Operational Tooling Expectations
Focus on what your teams actually use: migration tooling, schema management workflows, observability integration, and incident response ergonomics.
Implementation / Migration Plan: How to De-Risk the Move
A safe evaluation does not stop at “it works on a demo dataset.” This section outlines a practical rollout plan that surfaces compatibility risk, correctness issues, and failure-mode behavior before production traffic shifts.
Step 1 — Compatibility Assessment: Schema + Queries
Inventory schema features and identify your top query paths. Confirm the SQL/driver surface area that must be compatible for your app to behave the same.
Step 2 — Data Migration and Validation Strategy
Plan validation beyond row counts: checksums, application read-path correctness, and reconciliation strategies for edge cases.
Step 3 — Cutover Approach: Dual-Write vs Planned Cutover
Choose a cutover method that matches your risk tolerance. Dual-write reduces downtime but increases correctness complexity, so treat it as an engineering project, not a checkbox.
Step 4 — Performance + Failure Testing Runbook
Test tail latency under load, then run controlled failure drills. Your goal is to prove that SLOs are still met when nodes or zones fail.
Step 5 — Production Readiness Checklist
Lock in SLOs, alerts, on-call runbooks, and capacity planning assumptions before declaring success.
Pricing & Cost Drivers: What Actually Moves the Bill
The cost comparison that matters is not list price. It is which cost levers your workload will trigger at scale: compute, storage, replicas, backups, egress, regions, and support.
TiDB: Self-Managed vs TiDB Cloud Pricing Model
Self-managed TCO is primarily infrastructure plus operational labor, while TiDB Cloud shifts more cost into a managed-service model. If your team wants the fastest path to a production-grade trial, start here: Try TiDB Cloud (managed distributed SQL).
CockroachDB: Pricing Model Overview
Evaluate how pricing maps to your topology (regions, replicas) and your workload shape (steady-state vs bursty). Avoid comparing prices without aligning on equivalent availability and multi-region assumptions.
Cost Driver Checklist
A practical checklist includes:
- Compute footprint at steady state and peak.
- Storage growth rate and replica factor.
- Backup retention and restore testing frequency.
- Network egress and cross-region traffic.
- Support model and on-call expectations.
Pros & Cons
This section summarizes tradeoffs without spin, so you can sanity-check whether the “fit” aligns with your team’s priorities and constraints.
TiDB — Pros
- MySQL compatibility for many common app stacks.
- Scale-out model with TiKV storage and optional TiFlash HTAP path.
- Clear HTAP database story for operational analytics on fresh data.
TiDB — Cons / Tradeoffs
- Distributed transactions introduce coordination latency tradeoffs that must be tested.
- Compatibility edge cases exist; a focused POC is required.
- Operating model differs between self-managed and managed service.
CockroachDB — Pros
- Postgres ecosystem alignment (wire-compatibility focus) for many Postgres-oriented orgs.
- Multi-region is often a first-class evaluation dimension.
- Distributed SQL design oriented toward resilience and availability patterns.
CockroachDB — Cons / Tradeoffs
- SQL dialect/feature differences from “standard Postgres” must be tested in a POC.
- Distributed coordination can impact tail latency under certain contention patterns.
- Operational ergonomics vary by deployment model and topology.
Who Should Choose Which?
| Situation | Choose TiDB if… | Choose CockroachDB if… |
|---|---|---|
| Best-fit by compatibility needs | Your application ecosystem is MySQL-first and you want to preserve MySQL protocol compatibility | Your ecosystem is Postgres-first and you want Postgres wire-compatibility alignment |
| Best-fit by workload | You want OLTP scale-out plus an HTAP path (TiFlash) for fresher operational analytics | You want scale-out OLTP with analytics handled via external OLAP patterns or selective in-database techniques |
| Best-fit by operating model | You want self-managed flexibility or TiDB Cloud managed operations | You prefer the managed-service path in your ecosystem and your team aligns to that operating model |
| Best-fit by multi-region priorities | Multi-region is important, but you will choose a topology aligned to locality and latency constraints | Multi-region is a core product requirement and you are optimizing heavily around locality-driven designs |
Frequently Asked Questions
TiDB is MySQL-compatible at the protocol level and supports common MySQL syntax and drivers, but it is not guaranteed to be 100% identical for every MySQL feature or edge case. The safest approach is a focused POC on your top queries, schema features, and operational workflows. If your app relies heavily on MySQL-specific features, validate those early.
Bottom Line
If your priority is MySQL compatibility, elastic scale without manual sharding, and an HTAP database path via TiFlash on TiKV, TiDB is often the more practical choice to validate first. If your organization is deeply Postgres-first and multi-region is your primary design driver, CockroachDB can be a strong option, but you should still confirm compatibility and operational simplicity in a POC.
Next steps:
- Try TiDB Cloud (managed distributed SQL).
- Talk to a TiDB expert to review your workload, topology, and POC plan.