How Do Integrations, Analytics, and AI Workloads Compare?
Both TiDB and PostgreSQL serve as foundations for modern application stacks, but they approach ecosystem breadth and analytical capability from different positions. PostgreSQL leads with the deepest extension ecosystem in open source databases, an advantage that can be decisive when a workload depends on specialized functionality. TiDB provides value when teams want fewer moving parts across transactional, analytical, and AI workloads by consolidating capabilities that would otherwise require separate systems.
PostgreSQL Extensions and Ecosystem Depth
PostgreSQL's extension ecosystem is its defining strength. PostGIS provides industry-leading geospatial capabilities. pgvector enables vector similarity search for AI and RAG workloads. TimescaleDB optimizes time-series data. pg_trgm provides trigram-based text matching. Citus adds horizontal distribution.
The sheer breadth of extensions means PostgreSQL can be adapted to an extraordinary range of use cases. If your workload depends on a specific PostgreSQL extension, this is a strong reason to stay in the PostgreSQL ecosystem.
TiDB for Real-Time Analytics and Modern Data Workloads
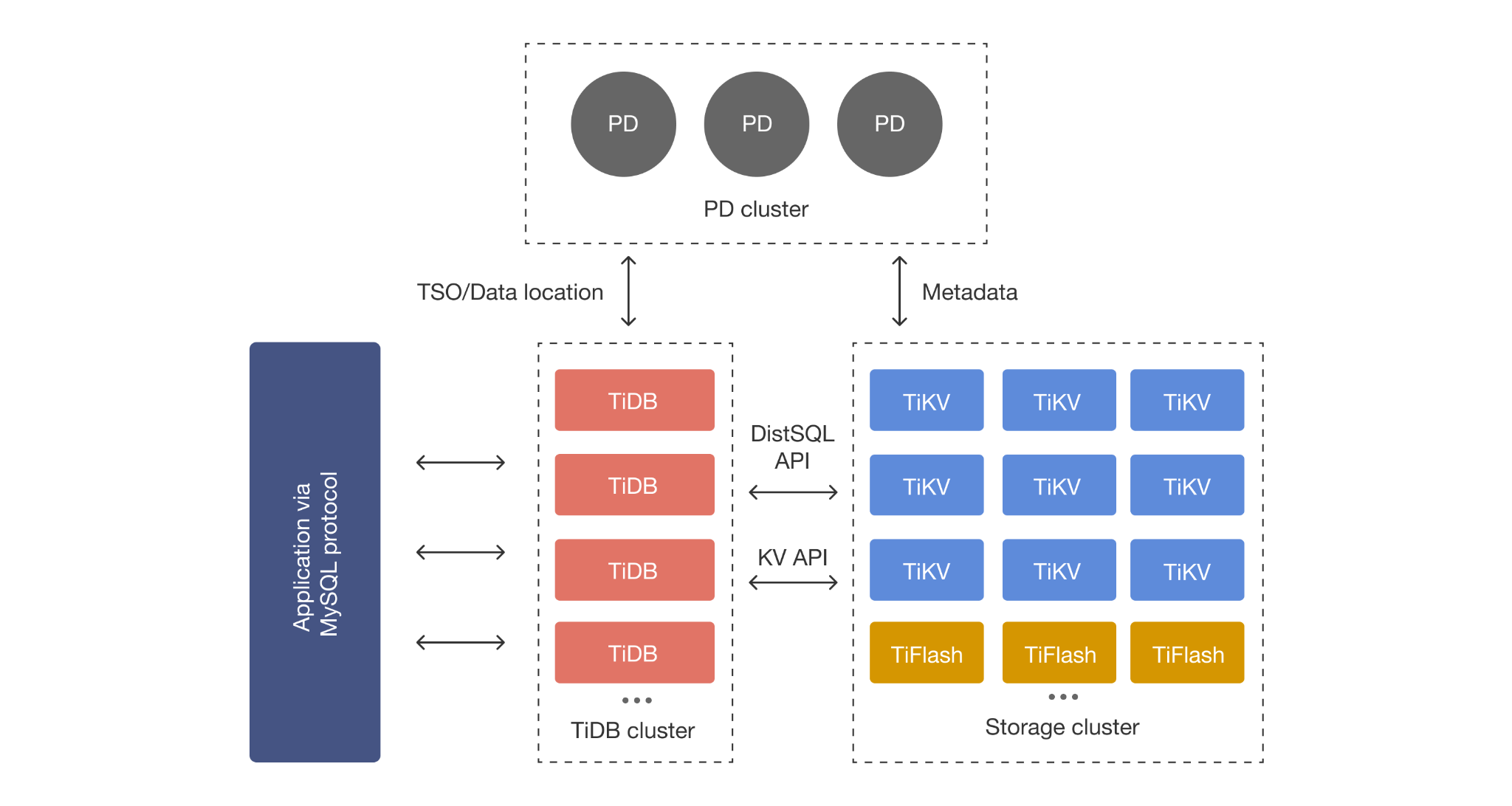
TiDB reduces architectural complexity for teams that need OLTP and analytics in one system. Instead of PostgreSQL + Citus for scale + a separate OLAP warehouse + ETL pipelines connecting them, TiDB provides transactional storage (TiKV) and columnar analytics (TiFlash) in a single cluster.
TiDB also supports vector data types and vector indexes for AI and RAG workloads, enabling similarity search directly within the distributed SQL database. For a detailed comparison of vector capabilities, see: pgvector vs TiDB Vector Storage
The tradeoff: TiDB's extension ecosystem is narrower than PostgreSQL's. If your workload requires PostGIS, TimescaleDB, or dozens of niche PostgreSQL extensions, TiDB is not a drop-in replacement. If your priority is reducing architectural complexity for scale-out OLTP + analytics, TiDB simplifies the stack.
What Do Deployment, Governance, Support, and Pricing Model Look Like?
How a database is deployed, managed, and priced affects total cost of ownership as much as raw performance. Both TiDB and PostgreSQL offer open source self-managed and commercial managed service options, but the operational tradeoffs differ significantly.
Managed Service vs Self-Managed Tradeoffs
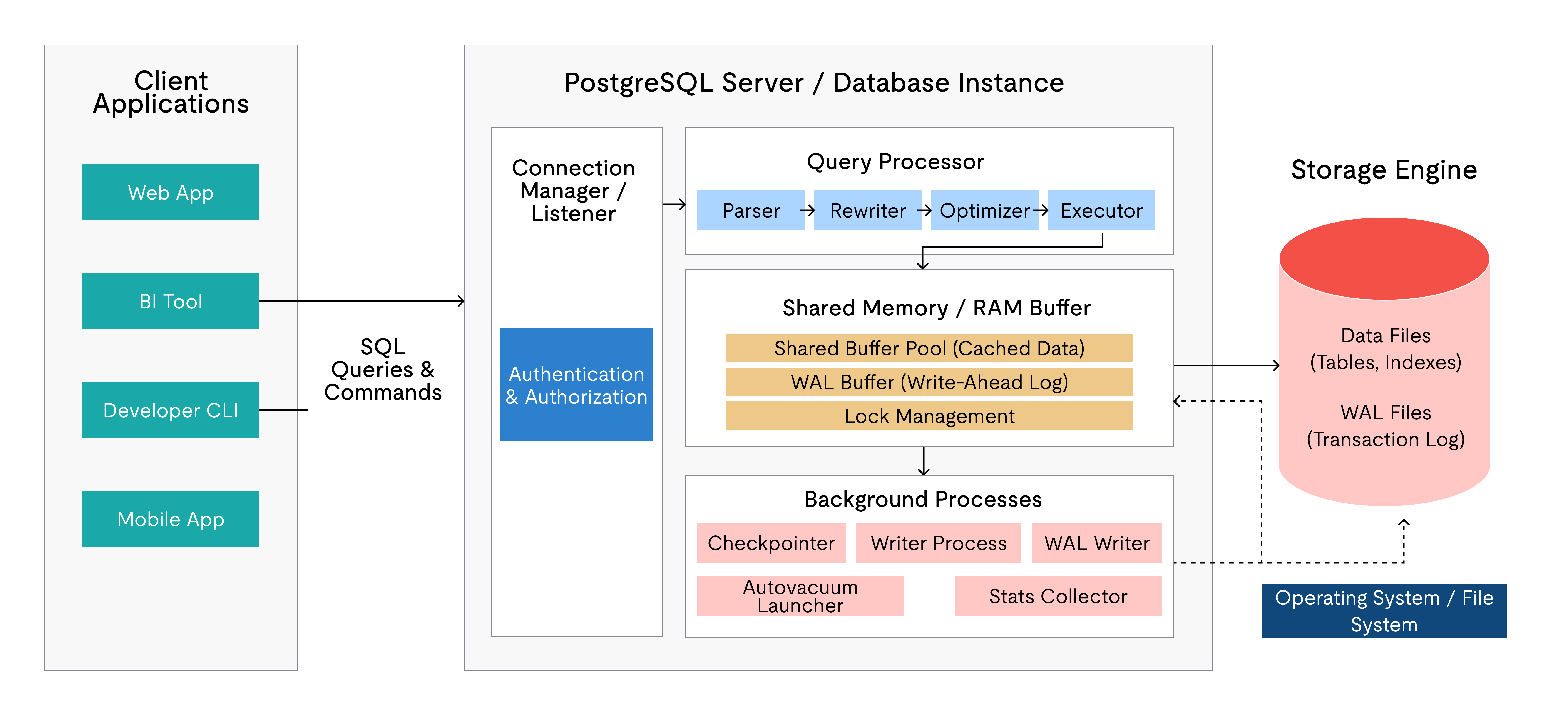
PostgreSQL has more managed-service options than any other open-source database. Amazon RDS, Aurora PostgreSQL, Azure Database for PostgreSQL, Google Cloud SQL, Supabase, Neon, and Crunchy Bridge are just the most prominent. This breadth gives PostgreSQL teams many paths for offloading operational overhead. However, most managed PostgreSQL services inherit the single-node architecture — they do not natively provide distributed writes or HTAP analytics.
TiDB is available as TiDB Cloud on AWS, GCP, Azure, and Alibaba Cloud, with Dedicated, Essential, and Starter (free) tiers. TiDB Cloud manages the full distributed stack (TiDB + TiKV + PD + TiFlash) including monitoring, backup, and scaling automation.
For self-managed deployments on Kubernetes, TiDB Operator provides purpose-built lifecycle automation: rolling upgrades with automatic rollback, horizontal scaling via Custom Resource modifications, automated backup to S3-compatible storage, and native Prometheus/Grafana integration. PostgreSQL on Kubernetes typically involves assembling Patroni or CloudNativePG for HA, plus separate operators or Helm charts for backup, monitoring, and connection pooling. TiDB Operator consolidates these concerns into a single operator, reducing the Kubernetes configuration surface area for platform teams.
For a managed-service comparison, see: TiDB Cloud Starter vs Amazon RDS
How to Compare Pricing Without Oversimplifying Cost
Both databases are free to self-manage. TiDB is Apache 2.0; PostgreSQL uses the PostgreSQL License. Neither charges license fees.
Total cost of ownership is what actually differs. For PostgreSQL at scale, factor in operating HA tooling (Patroni cluster), sharding infrastructure (Citus), connection pooling (PgBouncer), and a separate analytics system. Each adds infrastructure cost and engineering hours.
For TiDB, factor in the multi-component cluster (TiDB + TiKV + PD + optional TiFlash) and its infrastructure footprint. TiDB Cloud simplifies this into free, usage-based, and provisioned pricing tiers with managed operations included.
The right way to compare cost is to model it against your projected workload growth over two to three years, not just today's steady state. A PostgreSQL deployment that is cheaper today may become more expensive than TiDB once you add the tooling required to scale it.
Support and Governance Considerations for Enterprise Teams
PostgreSQL is governed by the PostgreSQL Global Development Group, a well-established open-source community with no single corporate owner. Commercial support is available from EDB, Crunchy Data, Percona, and managed cloud providers.
TiDB is developed by PingCAP with commercial support available directly and through TiDB Cloud. TiKV, TiDB's storage engine, has graduated from the CNCF, which provides an additional governance signal for enterprises evaluating open-source risk.
For enterprise teams: evaluate support SLAs, security audit availability, and compliance certifications from the specific vendor or managed service you plan to use.
Who Should Choose TiDB and Who Should Choose PostgreSQL?
The right choice depends on workload characteristics, growth trajectory, team expertise, and operational priorities. Neither database is universally superior.
Choose TiDB If…
- You need horizontal write scaling without implementing application-level sharding or adopting Citus.
- You need built-in high availability with automatic Raft-based failover, without assembling Patroni + etcd + load balancer stacks.
- You need real-time analytics on operational data without building and maintaining ETL pipelines to a separate data warehouse.
- You're a MySQL shop and want distributed SQL that speaks your existing protocol and works with your existing drivers and ORMs.
- You're running a SaaS platform with multi-tenant workloads that are outgrowing single-node PostgreSQL or MySQL and you want fewer operational moving parts at scale.
Choose PostgreSQL If…
- Your workload fits comfortably on a single well-provisioned server and you do not anticipate needing distributed writes or multi-terabyte growth.
- You depend on specific PostgreSQL extensions like PostGIS, pgvector (with tight PG integration), TimescaleDB, or other specialized extensions.
- Your team's expertise is deeply PostgreSQL-native and the operational cost of learning a distributed SQL system outweighs the scaling benefits for your current workload.
- You're optimizing for single-query latency on local data where the overhead of distributed coordination is not justified by your concurrency or data volume.
- You already have a working PostgreSQL HA and analytics stack (Patroni + Citus + warehouse) and the operational investment is stable and sustainable at your current scale.
How TiDB Helps Teams Outgrow PostgreSQL Limits
Many teams start with PostgreSQL and run it successfully for years. TiDB becomes relevant when workloads reach a point where single-node scaling, manual sharding, or the operational burden of HA tooling and separate analytics systems creates more friction than the application can tolerate.
When TiDB Becomes the Better Next Step
The inflection point typically arrives when one or more of these pressures emerge:
- Write throughput exceeds what vertical scaling can handle cost-effectively.
- The HA toolchain (Patroni, repmgr, etcd) becomes a significant operational burden to maintain and test.
- Analytics queries compete with production OLTP traffic and you're building ETL pipelines to offload them.
- Multi-tenant data growth makes sharding decisions increasingly complex and error-prone.
TiDB addresses all four of these pressures in a single system. It consolidates scale-out OLTP, built-in HA, and real-time analytics without requiring you to assemble and maintain separate tools for each capability.
The migration tradeoff is real: TiDB speaks MySQL, not PostgreSQL, so moving from PostgreSQL requires query adaptation and driver changes. For teams already operating MySQL workloads or willing to invest in the transition, TiDB replaces multiple PostgreSQL add-on systems with integrated capabilities that are maintained and tested as a single product.
Start Your Evaluation
If your PostgreSQL deployment is approaching the limits of single-node scaling, if your HA stack is consuming increasing operational bandwidth, or if your analytics architecture is growing more complex to maintain, TiDB is worth evaluating with your actual workload.
Get started with a free TiDB Cloud Starter cluster and benchmark against your current PostgreSQL performance baselines. Teams that want guidance on topology planning or migration sequencing can also request an architecture review from TiDB experts.
TiDB vs PostgreSQL FAQs
Is TiDB PostgreSQL Compatible?
No. TiDB is MySQL-compatible, not PostgreSQL-compatible. Migrating from PostgreSQL to TiDB requires adapting queries to MySQL syntax and updating drivers and ORMs.
Is TiDB Faster Than PostgreSQL?
It depends on the workload. PostgreSQL often has lower single-query latency on local data because there is no distributed coordination overhead. As concurrency and data volume grow, TiDB maintains more stable p95/p99 latency by spreading load across nodes. For analytical queries, TiDB's TiFlash columnar engine is significantly faster than row-oriented PostgreSQL scans.
Can PostgreSQL Scale Horizontally?
Not natively for writes. PostgreSQL scales reads via streaming replication and can distribute writes using Citus, but Citus introduces constraints around co-located joins, cross-shard transactions, and coordinator management. TiDB handles horizontal scaling natively — automatic sharding, rebalancing, and distributed transactions — without extensions or application changes.
When Should You Move from PostgreSQL to TiDB?
Consider the move when write throughput requires increasingly expensive vertical scaling, your HA toolchain (Patroni, repmgr) is consuming significant operational capacity, or analytics workloads are impacting OLTP performance. TiDB consolidates scale-out writes, built-in HA, and HTAP analytics into a single system.
Which Database Is Better for Analytics and AI Workloads?
For analytics, TiDB's TiFlash provides real-time columnar analytics on live transactional data without ETL. PostgreSQL handles moderate analytics on a single node but heavy workloads need a separate OLAP system. For AI/vector workloads, PostgreSQL's pgvector is more mature today; TiDB supports vector types and indexes but with a narrower ecosystem. Choose based on whether operational analytics at scale or extension depth matters more.