

Key Takeaways
- Unlike traditional systems that copy raw storage files, TiDB anchors backups to a single, globally consistent timestamp.
- By using a cluster-wide boundary, TiDB avoids “fractured” backups where different nodes reflect conflicting transactional states.
- Committed data is recorded, enabling precise Point-in-Time Recovery (PITR).
- Because consistency is enforced during the backup, restore operations require no manual reconciliation, lock cleanup, or partial transaction repairs.
- TiDB’s backup model is transaction-centric rather than node-centric, leveraging its native distributed ACID foundations to simplify data protection.
Distributed database backups are not just about coordinating the copying of files from multiple machines. It is capturing a single, consistent point in time across a system that is actively processing transactions.
In TiDB, data is distributed across many nodes. Transactions use MVCC with a two-phase commit protocol. Transactions may touch multiple partitions at once. At any given moment, some transactions are committed, some are in progress, and some have partially written state.
The core challenge for backups is simple: How do you capture one logically consistent view of the entire cluster while it is still running?
The Risk of Inconsistent Distributed Database Backups
To understand why TiDB approaches backups this way, it is worth understanding the risks of backing up data in an inconsistent state. If you back up storage files independently on each node, you risk capturing a fractured view of the system. Different parts of the database cluster may reflect different transactional states:
- One partition includes a committed transaction while another does not.
- Some changes are written but not fully committed.
- Partial updates appear without their coordinating transaction state.
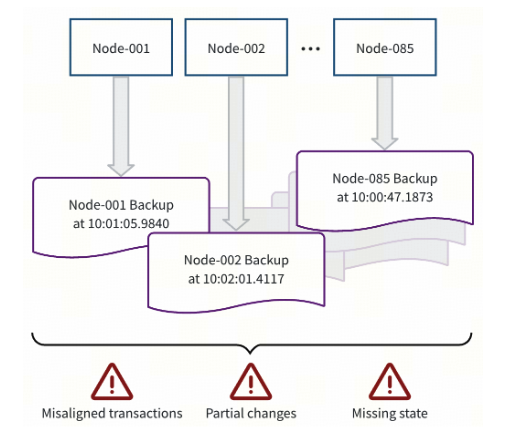
When backups contain partial transactions, restore operations have to include additional corrective actions. The system must detect and repair inconsistencies before it can safely resume serving traffic. That reconciliation work increases recovery time and operational risk, especially during already stressful outage scenarios.
In distributed systems, restore complexity often matters more than backup speed.
Full Backup: Anchored to a Global Transaction Boundary
TiDB’s Backup and Restore Tool (BR) approaches backups differently. Rather than copying raw storage artifacts, TiDB anchors each full backup to a single, globally consistent timestamp. That timestamp represents a real transactional boundary across the entire cluster.
The backup process reads data exactly as it was visible at that moment:
- In-flight transactions are excluded.
- Only fully committed changes are included.
- Every partition reflects the same logical point in time.
The result is not an approximation. It is a cluster-wide, transactionally consistent snapshot.
When that snapshot is restored, the data is already internally coherent. There is no need for lock cleanup, partial transaction repair, or cross-node reconciliation.
Log Backup: Preserving Consistency Over Time
Full snapshots capture the state of the cluster periodically. Meanwhile, to deliver on aggressive RPOs, TiDB’s log backup captures changes on an ongoing basis.
The challenge here is ensuring that changes are recorded only once they are fully and safely committed across the distributed system.
TiDB maintains a continuously advancing global boundary that represents the latest point in time at which all earlier transactions are guaranteed to be complete (Resolved Timestamp). Only changes before that boundary are eligible to be recorded in log backups.
This ensures that:
- Partial transactions are never captured.
- Point-in-time recovery reflects a real transactional state.
- Recovery boundaries are clearly defined and measurable.
The system also tracks log backup progress (checkpoints) across the entire keyspace, providing a clear recovery point objective and eliminating ambiguity about how far recovery can safely proceed.
Consistency is enforced continuously, not just during full snapshots.
Distributed Database Backups: Architectural Philosophy and Design
Backup behavior is not independent from database architecture. It reflects the system’s underlying consistency model.
Some distributed systems are built around eventual consistency. In those designs, nodes may be backed up independently as decoupled snapshots. Consistency across the cluster is often an approximation, restored later through background repair and reconciliation that hopefully brings the system back into a stable state.
Other systems scale by sharding data across independent MySQL instances. Backups occur per shard, and achieving a ‘Global Snapshot’ depends on external operational coordination rather than a single native transactional boundary.
TiDB takes a different approach. It provides distributed ACID transactions with a cluster-wide notion of time. Because transactions already share a globally ordered timestamp model (TSO), backups can anchor to that same foundation. This ensures that every backup represents a strictly consistent point-in-time state of the entire cluster, regardless of how many nodes or regions the data spans.
The result is a backup model that is transaction-centric rather than node-centric or shard-centric. Consistency is resolved at backup time rather than deferred to the restore operations, or post restore reconciliation.
That architectural choice shapes the recovery experience.
Restore Workflows and Deterministic Recovery
Consistency must be preserved not just during backup, but also during restore.
TiDB’s restore process is aware of database schema and transactional boundaries. Data is restored in alignment with table definitions and metadata, rather than as raw key ranges.
This allows:
- Clean recreation of tables before data ingestion.
- Correct mapping of identifiers when restoring into new clusters.
- Targeted, table-level recovery in multi-tenant environments.
More importantly, restore becomes deterministic rather than requiring subsequent corrective actions. There are no partial transactions to reconcile and no ambiguous state to interpret once data is loaded.
Delivering on an aggressive Recovery Time Objective is not just about how quickly data can be transferred. It is about minimizing the amount of cleanup required afterward to return the system to an operational state.
By enforcing transactional consistency at backup time and preserving that integrity through restore workflows, TiDB ensures that recovery remains predictable when it matters most.
Ready to experience deterministic recovery? Explore our documentation to start your journey with TiDB.
Experience modern data infrastructure firsthand.



TiDB Cloud Dedicated
A fully-managed cloud DBaaS for predictable workloads
TiDB Cloud Starter
A fully-managed cloud DBaaS for auto-scaling workloads