

For database products, point-in-time recovery (PITR) is a crucial capability. It allows users to restore their databases to specific points in time to protect against accidental damage or user errors. For example, if data is accidentally deleted or damaged, PITR can restore the database to its state before that time, thereby avoiding the loss of important data.
In this article, we’ll explore how PITR works with TiDB, an advanced, open-source, distributed SQL database. We’ll also discuss how we optimized PITR to maximize its stability and performance.
An architectural overview of TiDB’s PITR
TiDB has three components:
- TiDB is the SQL query layer.
- TiKV is the distributed storage engine.
- Placement Driver (PD) is the brain of TiDB that manages metadata.
TiDB generates distributed logs for every data change, including the transaction ID, timestamp, and details of each change. When PITR is enabled, TiDB periodically saves these logs to external storage such as AWS S3, Azure Blob, or Network File System (NFS). If data is lost or damaged, users can use the Backup and Restore (BR) tool to restore a previous backup of the database and apply the saved data changes up to the time the problem occurred.

Figure 1. TiDB’s PITR architecture.
When a user initiates log backup, the BR tool registers a backup task with PD. At the same time, a TiDB node is selected as the coordinator for log backup, which periodically interacts with PD to calculate the timestamps of global backup checkpoints. Meanwhile, each distributed storage node periodically reports its backup task status to PD and sends data change logs to the designated external storage.
When a user enters a PITR recovery command, the BR tool reads the metadata of the backup and notifies all TiKV nodes to start the recovery process. The restore worker on each TiKV node then reads the change logs before the specified point in time and applies them to the cluster. This way, you get the TiDB cluster of the specified point in time.
Log backup and restore cycle
Let’s now take a closer look into how log backup and restore work for TiDB’s PITR.
Log backup
Here’s the main interaction flow of the log backup process:

Figure 2. Log backup in TiDB.
- BR receives the backup command
br log start. It parses the start time and storage location of the backup task and registers the log backup task with PD. - The log backup observer on each TiKV node listens to the log backup tasks created or updated in PD, and backs up the changed data logs on the node within the backup time range.
- TiKV nodes back up KV change logs and report local backup progress to TiDB. The observer service in each TiKV node continues to back up the KV change log and generates backup metadata information using the global-checkpoint-ts obtained from PD. In the meantime, it periodically uploads log backup data and metadata to the storage.
- TiDB nodes calculate and persist global backup progress. The TiDB coordinator node polls all TiKV nodes to obtain the backup progress of each Region, calculates the overall log backup progress based on the progress of each node and reports it to PD.
Log restoration
The log restoration process is shown in the diagram below:
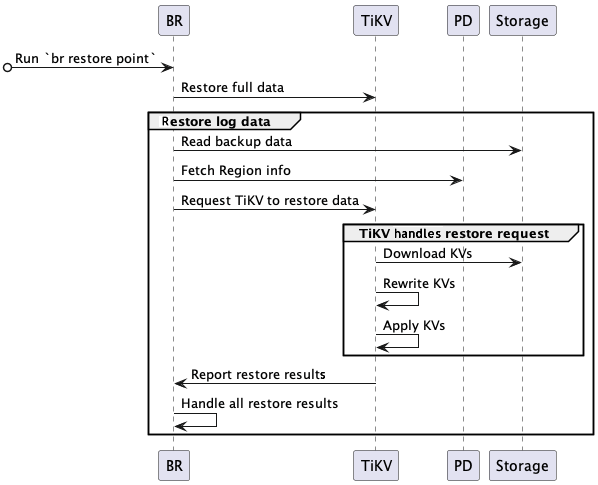
Figure 3. Log restoration in TiDB.
- When the user initiates a `br restore <timespot>` command, the BR tool validates the backup addresses, restore time, and database objects.
- BR restores the full data and reads the existing log backup data. After computing the required log backup data, BR accesses PD to obtain Region and KV range information, creates a restore log request, and sends it to the corresponding TiKV node.
- The TiKV node starts a restore worker, downloads the corresponding backup data from the backup medium, and applies the required changes to the corresponding Region.
- When the restore is complete, TiKV returns the results to BR.
How PITR is optimized for TiDB
Backing up and restoring logs is quite complex. Since PITR’s first release in TiDB, we have continuously optimized it to improve its stability and performance. For example, in the initial version, log backup generated a large number of small files. This caused many usage and experience issues for users. In the latest version, backup files are aggregated into multiple files of at least 128 MB, solving this issue.
For large-scale TiDB clusters, full backups often take a long time. Interrupted backups that could not be resumed could be very frustrating to users. TiDB 6.5 now supports resumable backups with optimized performance. Currently, PITR can back up a single TiKV cluster at a rate of 100 MB/s, and the performance regression of log backup for the source cluster is limited within 5%. These optimizations greatly improve the user experience and the success rate of large-scale cluster backups.
Since backup and recovery are usually the last line of defense for data security, PITR’s RPO and RTO metrics are also of great concern to many users. We have made many optimizations to improve PITR’s stability, including:
- Optimized the communication mechanism between BR, PD, and TiKV. This ensures that PITR can maintain an RPO of less than five minutes in most failure scenarios of TiDB and TiKV rolling restart scenarios.
- Optimized the recovery performance to achieve a performance of 30 GB/h in the application log stage, which greatly reduces the RTO time.
For more backup and recovery performance indicators, see TiDB Backup and Recovery Overview.
Summary and future plans
PITR is an essential feature for database products to protect against data losses. With PITR, TiDB users can recover their data up to a specific point in time, minimizing the amount of data lost and reducing downtime.
In the future, we will further optimize PITR’s recovery performance for large-scale clusters. This will improve the stability and performance of this feature. We will also support backup and recovery through SQL statements, which creates a stable, reliable, and high-performance backup and recovery solution for TiDB.
To experience PITR in TiDB, you can get started with TiDB 6.5 LTS or request a demo from our technical experts. You can also join our community on Slack and the TiDB Forum to share your thoughts and feedback.

Experience modern data infrastructure firsthand.



TiDB Cloud Dedicated
A fully-managed cloud DBaaS for predictable workloads
TiDB Cloud Starter
A fully-managed cloud DBaaS for auto-scaling workloads