
Introduction




TiDB vs Amazon Aurora: At-a-Glance Comparison
| Criteria | TiDB | Amazon Aurora |
| Primary use | Distributed SQL / NewSQL for scale-out OLTP; MySQL-compatible; optional HTAP via TiFlash | Managed relational engine on AWS (Aurora MySQL / Aurora PostgreSQL) |
| SQL / protocol compatibility | MySQL protocol + common syntax | Aurora MySQL is MySQL-compatible at the protocol/query layer; Aurora PostgreSQL is PostgreSQL |
| Consistency & transactions | Strong consistency with ACID transactions across a distributed cluster | Strong consistency with ACID transactions; behavior depends on engine choice + topology; validate failover and read consistency expectations |
| Scaling model | Horizontal scaling database: scale compute out by adding TiDB nodes; scale storage/throughput by adding TiKV nodes; designed to avoid manual sharding | Single-writer model with read replicas; reads scale out, writes primarily scale vertically on the writer instance |
| HTAP / analytics | TiFlash columnar replicas enable analytical queries on fresher operational data (HTAP) with workload isolation options | Analytics typically offloaded to separate systems to avoid impacting OLTP |
| Multi-region / locality | Supports multi-region database topologies; define patterns (single-region HA, multi-region reads) and be explicit about latency/cross-region consensus tradeoffs | Multi-region designs depend on AWS deployment choices; tradeoffs apply around latency, failover behaviors, and cost |
| Operations & reliability | Self-managed (VMs/Kubernetes) or managed via TiDB Cloud; HA via Raft-based replication (TiKV); supports online schema change (online DDL) and rolling operations patterns | Managed operations on AWS; validate maintenance and change management behavior |
| Kubernetes / platform fit |
Cloud-native option with Kubernetes database operator (TiDB Operator) + GitOps-friendly workflows; also available as TiDB Cloud | AWS-managed service; Kubernetes integration is typically “connect from K8s,” not “managed by K8s operator” |
| Ecosystem & integrations | MySQL drivers/ORMs; CDC via TiCDC; observability via TiDB Cloud built-in monitoring / self-managed integrations | Broad ecosystem; ops patterns vary by distro/vendor tooling |
| Implementation / migration | “MySQL-compatible” reduces rewrite scope vs non-MySQL systems | Broad AWS ecosystem + engine tooling |
| Pricing (high-level) | Self-managed: infra + ops (software $0 OSS). TiDB Cloud: published tiers on PingCAP pricing pages | Aurora cost drivers include instances, storage/I/O, backups, and egress; exact cost depends on usage and topology |
| AWS-native feature depth | Runs well on AWS, but is not an AWS service. Integrations depend on your deployment model (self-managed vs TiDB Cloud) | Deep AWS-native service integration patterns |
| Serverless / elastic options | Managed offerings may include elastic/serverless-style options (varies by tier/region) | Optional serverless offerings exist for Aurora |
| Global read architecture | Supports multi-region topologies, but you must design for latency and cross-region tradeoffs | Optional global database patterns exist; still requires explicit design for latency/failover tradeoffs |
| Portability / lock-in | Can run across clouds and Kubernetes | AWS-only service |
| Vector / AI retrieval workloads | Can support vector-style retrieval patterns depending on TiDB/TiDB Cloud capabilities and design choices | Often implemented via Aurora PostgreSQL extensions or adjacent AWS services (engine-dependent) |
| Best fit “default” | Platform teams standardizing on scale-out MySQL and portability | AWS-first teams optimizing for managed convenience when instance+replica scaling fits |
Table 1. Side-by-side of compatibility, scaling, consistency, HTAP, operations, and pricing drivers
Overview: What TiDB Is (Distributed SQL / NewSQL) vs What Aurora Is
At a high level, this comparison comes down to architecture and operating model:
- TiDB is built as a scale-out, MySQL-compatible distributed SQL system you can run anywhere.
- Amazon Aurora is a managed relational database service whose behavior is shaped by AWS and the specific Amazon Aurora engine you choose.
TiDB in Brief: MySQL-Compatible Distributed SQL with TiKV + Optional TiFlash HTAP
TiDB is a MySQL compatible distributed database built as a distributed SQL database (NewSQL). It separates the SQL/compute layer (TiDB) from distributed transactional storage (TiKV) so you can scale out by adding nodes instead of redesigning around shards. TiKV automatically splits and Raft-replicates data across storage nodes, avoiding manual sharding and single-writer bottlenecks. When you need an HTAP database path, TiFlash columnar replicas can serve analytical queries on the same underlying operational data.
Amazon Aurora in Brief: Managed Relational Engine on AWS (Aurora MySQL/Aurora PostgreSQL)
Amazon Aurora is a managed relational engine on AWS offered in Aurora MySQL and Aurora PostgreSQL flavors. It is often chosen to reduce operational overhead on AWS and to improve availability patterns compared to self-managed databases, with architecture and scaling characteristics that are shaped by the AWS service model and the specific engine you run.
Key Differences (What Changes Your Decision)
Two deal breakers often separate “Amazon Aurora is good enough” from “we need a different architecture”: How each system scales under sustained growth, and whether you can add real-time analytics without building and maintaining more data pipelines.
Common Misconceptions (and What Actually Matters)
- Misconception 1: “This is just a performance shootout.” What matters more is tail latency, failover behavior, and day-two operations under your real concurrency and schema-change patterns.
- Misconception 2: “Aurora is always cheaper because it’s managed.” Managed can reduce labor, but cost is driven by instance sizing, replicas, I/O behavior, backups, and cross-AZ/region traffic. Model cost under realistic load.
- Misconception 3: “MySQL-compatible means zero migration risk.” Compatibility is about your SQL surface area, drivers/ORM behavior, edge-case transactions, and query plans. You still need a focused POC.
- Misconception 4: “Distributed SQL automatically fixes hotspots.” Distribution helps scale, but hotspots still exist. You must test skewed access patterns and contention-heavy transactions.
- Misconception 5: “Multi-region is just a checkbox feature.” Multi-region always involves tradeoffs. You must choose explicit patterns and measure latency, consistency expectations, and failover RTO/RPO.
Scaling Model: Horizontal Scaling Database vs Instance-Based Scaling
If your bottleneck is sustained growth in write throughput, concurrency, or dataset size, the biggest difference is the scaling model. TiDB is designed as a horizontal scaling database that scales by adding TiDB/TiKV nodes, while Aurora scaling decisions are framed around instance sizing, replica strategies, and service constraints. If you want the clearest framing of the underlying tradeoff, see: Horizontal scaling vs vertical scaling for databases.
Where Amazon Aurora still wins: When you are all-in on AWS and want the simplest managed path for workloads that fit comfortably within a single-writer model with read replicas, without introducing distributed cluster operations.
HTAP Path: Operational + Analytics via TiFlash (without ETL)
If your team is splitting OLTP and analytics into separate systems to protect production performance, TiDB offers an HTAP path by replicating data into TiFlash for columnar analytics, so dashboards and aggregates can run closer to real time without ETL pipelines for every use case. For a deeper decision lens, see: HTAP databases: real-time analytics on operational data.
Where Amazon Aurora still wins: When your analytics are already well-served by AWS-native analytics services and you prefer a clean separation between OLTP (Amazon Aurora) and analytics (warehouse/lake) rather than running mixed workloads on the same database.
Multi-Tenant Architecture Controls: Placement + Resource Isolation
For SaaS platforms, database architecture is often about reducing “noisy neighbor” risk. TiDB supports patterns that help teams control data placement and isolate workloads across tenants, which is often harder to do cleanly when your scaling lever is primarily instance sizing and replica topology.
Where Amazon Aurora still wins: When your tenancy model is simple (few large tenants or low variance) and you can meet isolation requirements with straightforward database-per-tenant, schema-per-tenant, or AWS account-level isolation patterns without needing finer-grained placement controls.
Zero-Downtime Operations: Online Schema Change (Online DDL) + Upgrades
Production teams care about change management as much as raw performance. TiDB is built for rolling operations patterns and supports online schema change / online DDL so you can evolve schemas without routinely scheduling downtime windows. For a practical foundation on online DDL tradeoffs, see: Online schema change with MySQL online DDL (zero downtime).
Where Amazon Aurora still wins: When managed maintenance is your priority and your schema evolution is relatively infrequent or can tolerate controlled change windows, so you optimize for operational convenience over maximum flexibility in real-world workflows.
Architecture: How TiDB (TiDB Server + TiKV + PD + TiFlash) Differs from Aurora
The quickest way to understand the difference between TiDB and Amazon Aurora is to compare their building blocks: TiDB is a distributed system that separates SQL compute, transactional storage, and analytics into distinct components, while Aurora is a managed AWS engine delivered through a single-writer service model with read replicas.
TiDB Architecture Basics (Compute + Storage Separation; TiKV Row Store)
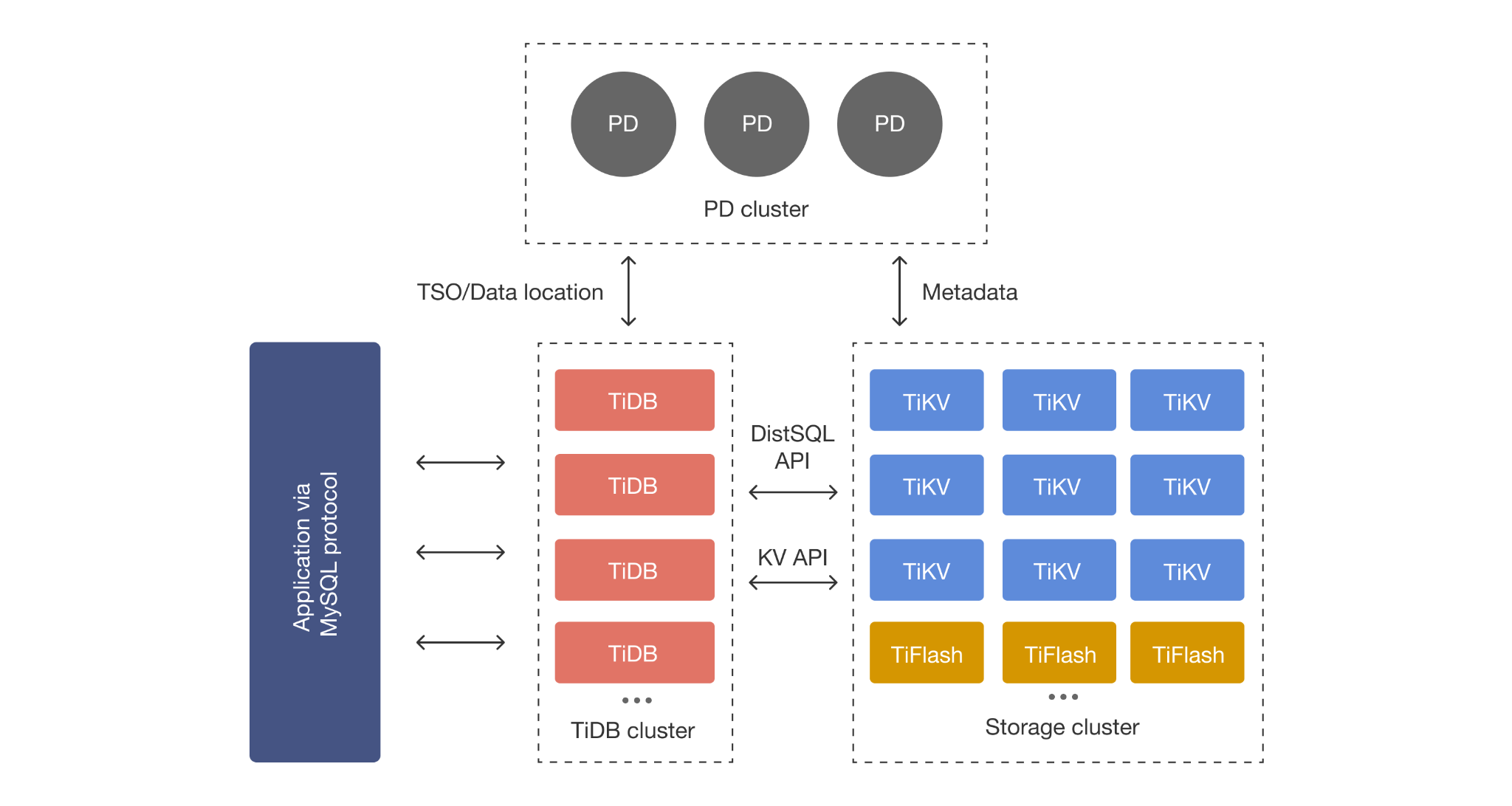
TiDB separates compute and storage so you can scale them independently. The TiDB layer is stateless SQL compute, while TiKV is the distributed transactional (row-oriented) storage layer. TiKV automatically splits data into Raft-replicated Regions, and PD manages region scheduling and placement across nodes. Placement/metadata coordination is handled by PD, which also provides the cluster’s Timestamp Oracle (TSO), enabling the system to rebalance and recover while maintaining strong consistency goals.
TiFlash for HTAP Analytics (Columnar Replicas)
TiFlash stores columnar replicas for faster analytical scans and aggregations, enabling HTAP patterns when you need operational queries and analytical queries on the same dataset while controlling workload interference.
Amazon Aurora Architecture Overview (Managed, Instance/Cluster Model on AWS)
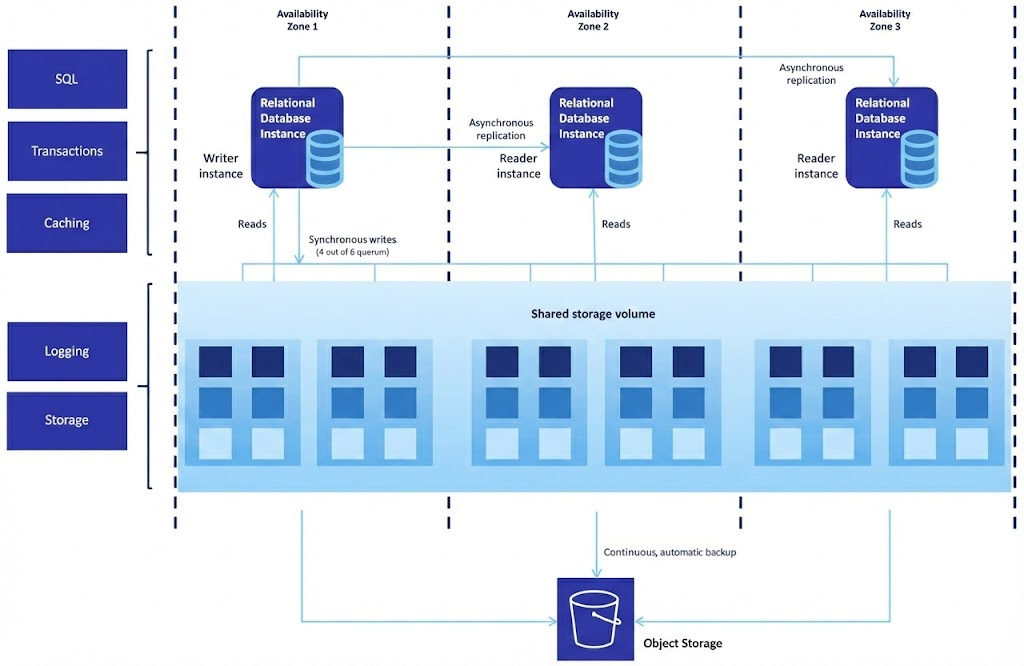
Amazon Aurora is delivered as a managed AWS service with a single-writer model with read replicas. In practice, your performance, failover behavior, and cost profile depend heavily on the engine choice (Aurora MySQL vs Aurora PostgreSQL), the instance class, replica topology, and how your workload behaves under concurrency and storage/I/O patterns.
MySQL Compatibility: App Changes, Drivers, and Limitations
To keep migration risk low, you need to be explicit about what “compatible” means in your environment. That starts with validating TiDB’s MySQL surface area while also clarifying which Amazon Aurora engine (MySQL vs PostgreSQL) you’re actually standardizing on.
TiDB MySQL Compatibility (What’s Compatible vs What Requires Testing)
TiDB is designed to be MySQL-compatible at the protocol level and supports common MySQL syntax and drivers/ORMs. In an evaluation, the practical work is identifying the “edge case” surface area: SQL features you depend on, transaction patterns under contention, and any MySQL-specific behavior that needs validation.
Amazon Aurora MySQL vs Amazon Aurora PostgreSQL: What You’re Actually Running
Amazon Aurora is not one engine. Amazon Aurora MySQL optimizes for a MySQL-compatible experience, while Amazon Aurora PostgreSQL is PostgreSQL. If your comparison is “TiDB vs Amazon Aurora,” define which Aurora engine you are actually standardizing on, because compatibility, migration work, and performance characteristics vary.
Consistency & Transactions: Strong Consistency at Scale
Prove the guarantees your application depends on by running failure drills: Kill a node/instance mid-transaction, simulate network partitions in test, and measure correctness + retry behavior.
What “Strong Consistency” Means in Practice (App Semantics, Failure Cases)
Strong consistency is not a marketing term. It is an application guarantee you validate under failure conditions and during topology events. In distributed systems, the real evaluation questions are: What your app assumes about reads/writes during failures, what happens during failover, and how latency changes when coordination spans failure domains.
If you want the grounded framework behind these tradeoffs, read: Understanding CAP theorem for distributed systems trade-offs.
Scaling & Performance: Concurrency, Complex Queries, and Hotspots
To compare TiDB and Amazon Aurora fairly, focus on how each behaves under real production stress—high concurrency, skewed access patterns, complex queries, and hotspots—because that’s where scaling models and practical limits show up.
Read + Write Scaling Without Manual Sharding
TiDB is designed to scale out without forcing application-level sharding as the default escape hatch. You scale compute by adding TiDB nodes and scale storage/throughput by adding TiKV nodes, while keeping one logical SQL database.
Predictable Latency Under High Concurrency
As concurrency rises, many teams optimize for stability (p95/p99) rather than peak throughput. The practical benchmark is “does the system stay predictable under contention, hotspots, and mixed query shapes?” Your POC should explicitly test contention-heavy transactions, skewed access patterns, and write bursts.
Amazon Aurora Scaling Limits to Watch (and When They Matter)
Amazon Aurora is a strongly managed default on AWS. However, real systems can run into practical limits driven by instance sizing choices, topology constraints, workload interference, and cost behaviors tied to storage/I/O and cross-AZ/region traffic. These are the Amazon Aurora limitations that only become visible at scale or under specific workload patterns, so the point is not to assume a limitation. It is to identify which constraints show up in your workload and whether they are acceptable.
HTAP Analytics: Real-Time Operational Intelligence with TiFlash
If your team is feeling the pain of ETL lag or analytics competing with production traffic, then TiFlash is the right lever for real-time insight on operational data without destabilizing OLTP.
When TiFlash Helps (Fresh Dashboards, Aggregates, Mixed Workloads)
TiFlash helps when you need analytics on operational data with minimal lag: Real-time dashboards, near-real-time aggregates, investigative queries during incidents, or product analytics that should not require ETL to a separate system for every question. The decision test is whether the workload mix can be isolated so OLTP remains stable while analytical scans run on columnar replicas.
For examples and decision boundaries, check out HTAP databases: real-time analytics on operational data.
Multi-Region & High Availability: Designing a Multi-Region Database
Before you design for “multi-region,” it helps to define the exact availability and locality outcome you want. The right topology (and the tradeoffs you inherit) depends on whether you are optimizing for failover, read proximity, or deployment flexibility across clouds.
Common Topologies (Single-Region HA, Multi-Region Reads, Locality Tradeoffs)
Multi-region design is always a latency and coordination trade space. A realistic evaluation names the topology you actually need: Single-region HA across AZs, multi-region reads with locality, or more advanced patterns. Be explicit about cross-region consensus realities and what you expect during network partitions, failover, and degraded states. TiDB replicates Regions via Raft; multi-region increases coordination latency.
Hybrid & Multi-Cloud Deployment: AWS, Azure, GCP, Kubernetes
Amazon Aurora is AWS-native. TiDB can run self-managed in AWS, Azure, or GCP, including Kubernetes environments, or you can use TiDB Cloud for a managed experience. If your platform strategy includes hybrid deployments or Kubernetes-first operations, treat this as a first-class decision dimension.
Operations: Kubernetes, Upgrades, and Online Schema Change (Online DDL)
Now it’s time to focus on the day-two reality: How easily your team can automate lifecycle operations, ship safe upgrades, and evolve schemas in production without turning every change into a maintenance event.
Kubernetes Database Operator: How TiDB Fits Kubernetes-First Teams
If your platform standardizes on Kubernetes, the operational question is lifecycle automation. TiDB supports Kubernetes-first workflows via the TiDB Operator: repeatable deployments, upgrades, scaling, backups, and GitOps-friendly management patterns.
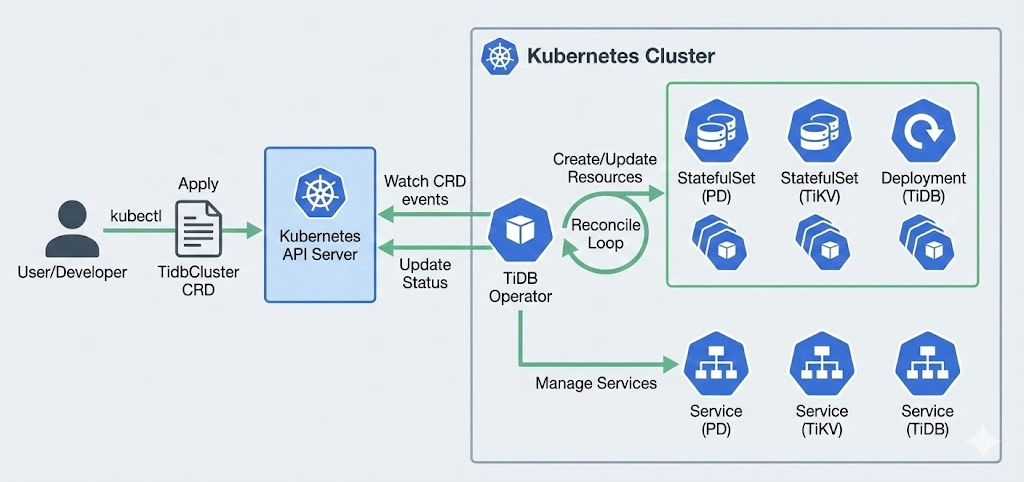
Online Schema Change: Online DDL for Live Production changes
Schema evolution is where downtime sneaks in. TiDB supports online schema change patterns (online DDL) so platform teams can change schemas while the system stays live, reducing maintenance windows and lowering the risk of “big-bang” migrations.
For the MySQL online DDL baseline and tradeoffs, see: online schema change with MySQL online DDL (zero downtime).
Multi-Tenant SaaS: Isolation, Noisy Neighbors, and Resource Control
If you run a SaaS platform, the database decision is often less about peak benchmarks and more about whether you can keep tenant performance predictable as usage patterns diverge and “noisy neighbor” incidents appear.
Tenant Isolation Patterns (Placement + Resource Isolation)
Multi-tenant database architecture is rarely “one size fits all.” The practical goal is minimizing noisy-neighbor interference while keeping operational complexity under control. TiDB supports patterns that help teams isolate tenants by placement rules and resource controls, especially for SaaS workloads with uneven tenant sizes and spiky traffic.
Proof Point: From a Reliability Engineer

“With TiDB, we can effectively isolate workloads to prevent noisy neighbors from impacting performance.”
Zander Hill
Experienced Data Reliability Engineer