

Key Takeaways
- A context platform is a single operational data layer that unifies vector search, structured queries, and real-time analytics in one system.
- AI apps fail in production because of the data layer, not the model.
- The stitched stack of vector DB, relational DB, and cache breaks at production scale.
- Three requirements: a unified SQL interface, real-time freshness, and elastic scale.
- Mature AI teams are converging on this architecture as the production default.
The stories sound the same in every engineering review. A team ships a working AI prototype in a week. The demo is impressive. Leadership greenlights production. Six months later, the app is still not in production.
The failure rarely traces back to the model. The team did not pick the wrong LLM. They did not get the prompt wrong. They did not even get the retrieval wrong, exactly.
What they got wrong was the data layer.
And a pattern is emerging, across customers we talk to and across teams writing publicly about their architectures, for what comes next. The term that keeps surfacing is context platform. It is worth understanding what it means, because it is quietly becoming the way mature AI teams talk about their data infrastructure.
AI Application Data Layer: The Real Bottleneck is Context, Not the Model
AI applications in production have a common shape. An agent reasons over a long conversation history. A RAG pipeline combines vector embeddings with structured metadata from a transactional system. A multi-agent workflow shares state across tasks that run in parallel. A personalization system joins real-time user behavior against historical patterns.
Every one of those patterns has the same underlying requirement: A scalable, reliable way to store and retrieve context. Not just embeddings, structured rows, or session state. All of it, together, at the speed the application needs it.
The model is a commodity at this point. The prompt is a configuration detail. Context engineering, as Anthropic describes it, is the discipline of curating what an agent sees at inference time. The hard part, the part that decides whether your application works at production scale, is the layer underneath that serves context to the model in the right shape at the right time.
That layer is what a context platform is.
The teams building agents at scale describe the same problem from the application side. Manus has written about the relentless context iteration that defines a production agent: Thousands of state updates per task, cache hit rates that decide latency and cost, action spaces that grow until the agent gets confused. Their challenges are the application-layer mirror of the infrastructure question. The data layer is where those challenges become tractable or unmanageable.
Why the Stitched Stack Breaks in an AI Application Data Layer
The default pattern most teams reach for when they start building is to pick a specialist tool for each data type. A vector database for embeddings. A relational database for structured state. A cache for session memory. Maybe a search engine for full-text. Maybe a graph database if the use case has relationships.
On paper this looks reasonable. Each tool is the best at its specific job. You can swap components independently. The architecture diagram fits on a slide.
However, in production, it falls apart for a specific set of reasons:
- Data duplication. The same entity lives in three or four systems: A row in the relational database, embeddings in the vector store, a cached copy in Redis, an entry in the search index. Keeping them in sync is a full-time job.
- Sync lag. Pipelines move data between systems on schedules that do not match the speed of AI workloads. By the time a new transaction reaches the vector store, the agent has already responded with stale context.
- Query fragmentation. A single AI request often needs vector similarity, a structured filter, and a real-time aggregation. In a stitched stack, that is three round trips, three failure modes, and business logic that should live in SQL sprawling into application code.
- Operational compounding. Every new data type adds another system to provision, patch, secure, monitor, scale, and pay for. Teams that started with two databases find themselves running seven.
Teams hit these problems in roughly the same order, and usually in the same quarter they are trying to move from beta to general availability. The stitched stack is what got them to the demo. It is also what is now blocking the launch.
AI Application Data Layer: What a Context Platform Actually is
A context platform is a single operational data layer that handles the work the stitched stack was trying to do, without the seams between systems.
In practice, it has three defining requirements.
- A unified query interface. An AI application should be able to retrieve a combination of vector similarity results, structured rows, and real-time aggregations with a single query, in a single language, against a single system. For most teams this means SQL, because SQL is the standard, agents can generate it, and humans can review it. It also already handles joins, filters, and aggregations in ways that bespoke vector-database query languages do not.
- Real-time freshness. The data the agent reasons over has to reflect what just happened, not what happened in the last ETL window. This means transactional writes and analytical reads have to coexist in the same system, on the same data, without the lag that comes from moving data between engines. Context that is an hour old is not context. It is a stale snapshot pretending to be context.
- Elastic scale that matches agent burstiness. Agent workloads are not steady-state. They spike unpredictably with viral moments, workflow runs, and scheduled jobs. The data layer has to absorb those spikes without over-provisioning during quiet periods. This is why serverless consumption models and scale-to-zero economics are showing up in every serious AI data infrastructure conversation.
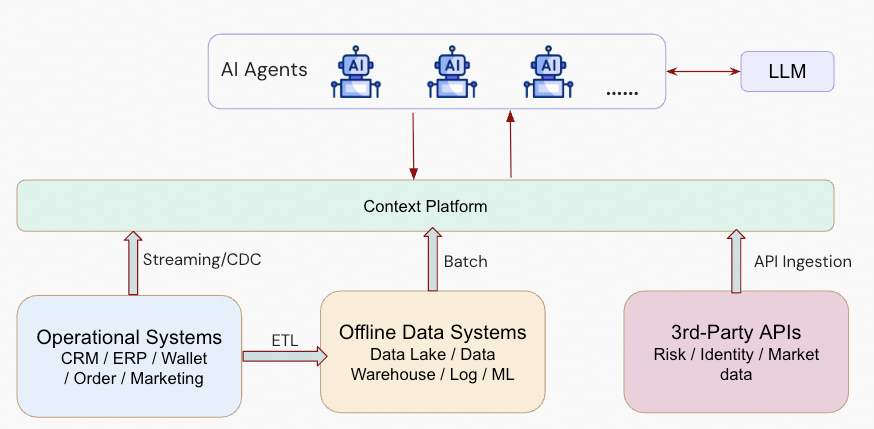
A context platform sits between source systems and AI agents, ingesting operational, analytical, and external data through multiple paths and serving it back as the unified context layer agents reason over.
Put those three requirements together and you have the spec for a context platform. A database that speaks SQL, handles vectors natively, keeps transactional and analytical workloads fresh against each other, and scales compute elastically underneath.
The Context Platform Pattern in Practice
Consider a RAG application with persistent agent memory. The user has been chatting with the agent for weeks. Each turn needs to retrieve relevant history, combine it with fresh reference documents, and respond in under a second.
On a stitched stack, that single request touches four systems. A vector database handles the document retrieval. A relational database stores the conversation log. A cache serves recent session state. A separate service reconciles them and passes the assembled context to the model. Every one of those hops is a place things can go wrong, and every one of them adds latency the application has to absorb.
On a context platform, the same request is a single SQL query. Retrieve the top-k relevant document chunks using a vector similarity function. Join against the conversation history by user ID and time range. Filter to the last 24 hours of session state. Return the combined context in one round trip.
Each agent gets its own private context, isolated from other agents but served by a shared multi-tenant platform underneath. This pattern handles per-user memory, session state, and per-task working context without forcing separate databases per agent.
The logic that used to live across four systems collapses into the database. The latency drops. The failure modes shrink. The ops burden falls. And the application code gets simpler, not more complex, as the AI features grow in sophistication.
This is the shift. It is not a new database feature. It is a rethinking of where the work should live.
Why a Context Platform is Becoming the Default in an AI Application Data Layer
The stitched-stack pattern made sense when vector search was new, when teams were prototyping, and when each data type was being pioneered by a different specialist startup. That moment is passing.
Mature SQL databases now have native vector search. They also have full-text search, JSON types, columnar engines for analytics, consumption pricing, and elastic compute. The argument for running five systems when one can handle the workload is getting harder to make with every release cycle.
Meanwhile, the teams running AI applications at scale are converging on a simpler architecture. One system. One query language. One operational footprint. Context that lives where the application needs it, in the shape it needs it, at the freshness it needs it.
The context platform is what that architecture is called when it matures.
What Comes Next
If you are designing the data layer for a production AI application right now, the question to ask is not “which vector database is fastest.” It is “what does my context look like a year from now, and is my architecture going to survive that?”
Because the applications that win this era are not going to be the ones with the best retrieval latency on day one. They are going to be the ones that can evolve their context patterns without rebuilding their stack every quarter.
That kind of evolution only happens on a unified foundation.
Want to dive deeper into context platforms? Li Shen walks through the context platform pattern in his latest webinar, Building a Context Platform AI Applications Actually Need. Watch the on-demand recording.
FAQs
How is a context platform different from a vector database?
A vector database handles one data type: Embeddings. A context platform handles vectors alongside structured rows, full-text, and real-time analytics in a single system, queryable through one interface. Vector databases are a component. A context platform is the architecture that replaces the need to stitch multiple components together.
Do I need to rip out my existing stack to adopt a context platform?
No. Most teams adopt a context platform incrementally, usually starting with a single new AI workload that has not yet been built on the legacy stack. The unified pattern proves itself on the new use case, then existing workloads migrate over time as the operational savings become visible.
Can a context platform handle both transactional and analytical workloads?
Yes, and this is one of the defining requirements. AI applications need to read fresh transactional data and run analytical aggregations against the same dataset, often in the same query. A context platform handles both without forcing data movement between separate OLTP and OLAP systems.
Does TiDB qualify as a context platform?
TiDB meets the three defining requirements: A unified SQL interface that handles vector search, structured queries, and analytics in one system; real-time freshness through a converged transactional and analytical engine; and elastic scale through TiDB Cloud’s serverless consumption model. Companies like Manus and Dify run AI and operational workloads on TiDB at production scale.
What size team or workload justifies moving to a context platform?
The economics tip in favor of unification earlier than most teams expect. If your AI application already needs more than two specialist systems to serve context, the operational overhead is likely costing more than the migration. Teams running a single demo prototype can stay on a stitched stack longer, but anything moving toward production pricing, SLAs, or multi-tenant deployment should evaluate the unified pattern.
Experience modern data infrastructure firsthand.



TiDB Cloud Dedicated
A fully-managed cloud DBaaS for predictable workloads
TiDB Cloud Starter
A fully-managed cloud DBaaS for auto-scaling workloads