


A technical deep dive into letting an AI reason directly over your database.
Food waste is a quiet horror story. Every year, roughly 1.3 billion tons of food are discarded globally, often because we simply forget what’s in the back of our fridges. Half-used onions, forgotten spinach, and that single, lonely tomato—they aren’t just ingredients; they are “ghosts” of a meal that never happened.
During a late-night coding session, staring at my own fridge, I wondered if we could use modern tech to bring these ingredients back to life. This sparked the idea for Recipe Reanimator, a Halloween-themed web app designed to turn leftover “scraps” into AI-generated culinary creations while tracking the environmental impact.
Building this wasn’t just about the recipes, though. It was a journey into managing a hybrid data architecture—balancing the rigid structure of user accounts and sustainability metrics with the flexible nature of AI-generated content. To do this, we stitched together a “chimera” of technologies, primarily using TiDB Cloud for our relational backbone and Kiro as our AI-driven development partner.
The Goal: Solving the “Fridge Graveyard”
The mission was simple but technically demanding: create an interface where users could “reanimate” their leftovers. We needed to handle image recognition for pantry items, complex recipe generation via LLMs, and a persistent record of every gram of CO₂ saved.
We set out to build a system where:
- Vision-to-Pantry: Users snap a photo; Gemini Vision extracts the ingredients.
- The Cauldron: A drag-and-drop UI where ingredients are staged for processing.
- Impact Tracking: Real-time calculations of money and carbon emissions saved.
- The Library: A persistent store of “reanimated” recipes, favorites, and shopping lists.
The challenge wasn’t just the AI logic; it was the data integrity. We needed a system that could handle the structured relationship between users, their historical savings, and their saved favorites without becoming a maintenance nightmare as the feature set grew.
The Stack: Why We Chose a Hybrid Approach
When deciding on the data layer, we noticed a clear divide in our requirements. Our recipe data was highly unstructured—JSON blobs from LLMs that could change schema based on the prompt. However, our core business logic—user authentication, sustainability benchmarks, and relational links—required strict ACID compliance.
We chose TiDB as our primary relational engine. As a distributed SQL database, it gave us the familiar MySQL-compatible interface we needed for Python’s SQLAlchemy, but with the horizontal scalability that ensures we won’t outgrow our infrastructure if the app goes viral.
To complement this, we used:
- Backend: Python (FastAPI) for high-performance asynchronous API handling.
- AI Orchestration: Google Gemini for vision and recipe synthesis.
- Development Partner: Kiro, an AI-first IDE tool that supports Model Context Protocol (MCP), allowing it to “see” and interact with our TiDB schema directly.
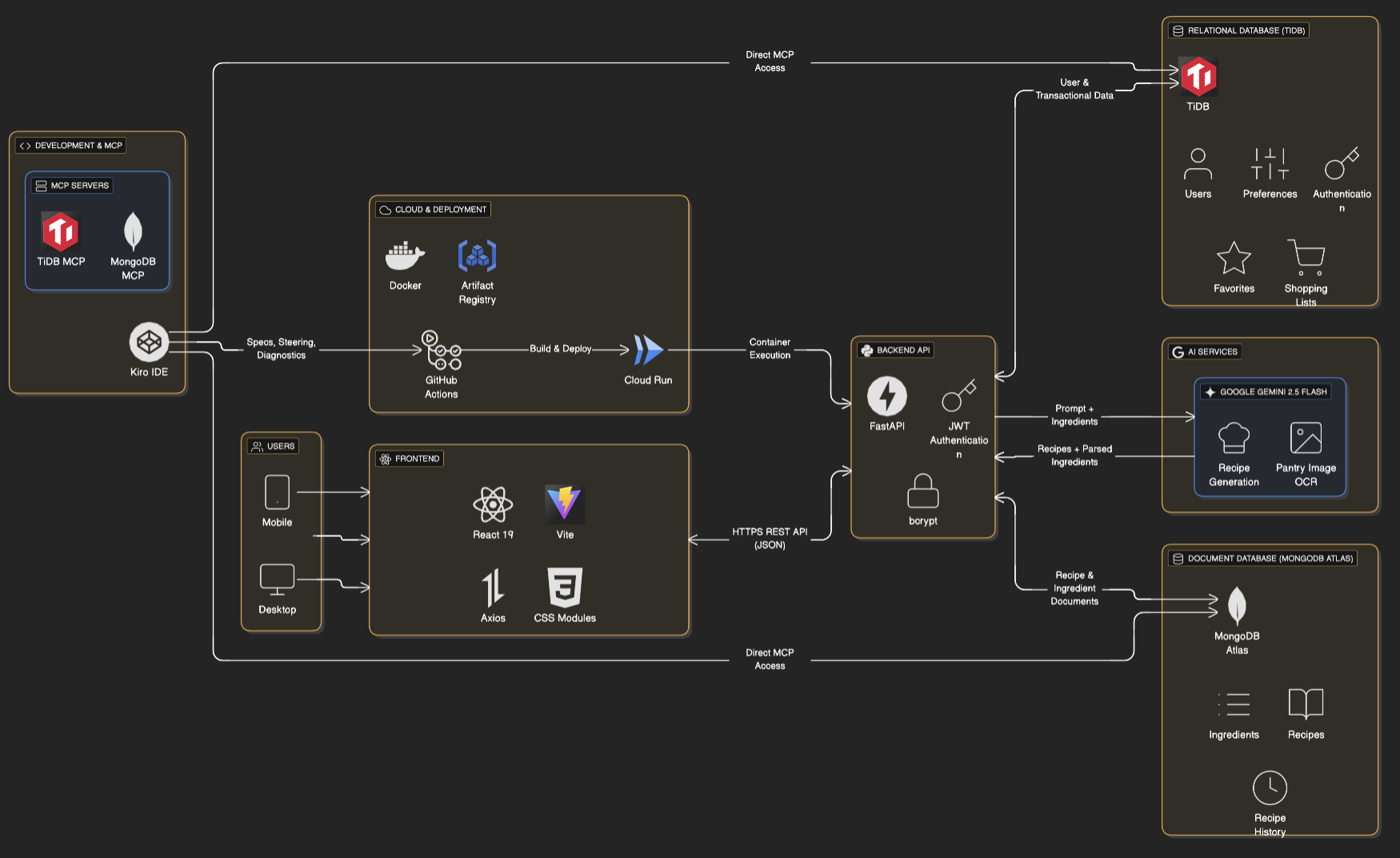
The Architecture: Stitching the Chimera Together
A common mistake in AI projects is dumping everything into a document store. We resisted this. For Recipe Reanimator, TiDB acts as the “brain,” managing the state and relationships, while MongoDB handles the “flesh” (the recipes themselves).
We relied on TiDB to handle three critical areas:
- Identity & Security: Managing user hashes and session data.
- The Sustainability Ledger: Tracking cumulative CO₂ and financial savings.
- Relational Mapping: Connecting unique user IDs to specific recipe IDs stored elsewhere.
With the foundation in place, the next challenge was actually building the schema. Instead of writing boilerplate DDL scripts manually, we used Kiro’s MCP integration to let our AI assistant interface directly with our TiDB instance.
Implementation: Defining the Living Schema
One challenge we faced early on was defining a schema that could accurately track “Waste Scores.” We needed to store historical data on food categories and their respective carbon footprints. We used TiDB to ensure that every “reanimation” event was transactionally linked to a user’s total impact score.
The following Python snippet shows how we defined our core Shopping Item model using BaseModel, which connects seamlessly to TiDB’s MySQL-compatible interface.
from pydantic import BaseModel, Field
from datetime import datetime
from typing import Optional
class ShoppingItemCreate(BaseModel):
"""Model for creating a shopping list item"""
ingredient_name: str = Field(..., description="Name of the ingredient")
quantity: Optional[str] = Field(None, description="Quantity needed")
recipe_id: Optional[str] = Field(None, description="Recipe ID this item is for")Connecting Kiro to TiDB via MCP
The most significant “aha!” moment occurred when we configured Kiro to talk to our TiDB instance. By using a Model Context Protocol (MCP) server, we allowed Kiro to execute DESCRIBE and SELECT queries in our development environment.
When we needed to add a “Favorites” feature, we didn’t just ask the AI to “write some code.” We asked it to “Check the existing user table in TiDB and suggest a relational schema for a favorites table that links to our MongoDB recipe IDs.“
The AI was able to see the live schema and generate the SQL, which was executed by the Kiro terminal. To setup the MCP connection in the settings of Kiro inside the mcp.json file we added the below code:
{
"mcpServers": {
"fetch": {
"command": "uvx",
"args": [
"mcp-server-fetch"
],
"env": {},
"disabled": true,
"autoApprove": []
},
"TiDB": {
"command": "uvx",
"args": [
"--from",
"pytidb[mcp]",
"tidb-mcp-server"
],
"env": {
"TIDB_HOST": "gateway01.ap-southeast-1.prod.aws.tidbcloud.com",
"TIDB_PORT": "4000",
"TIDB_USERNAME": "<username>",
"TIDB_PASSWORD": "<password>",
"TIDB_DATABASE": "RecipeReanimator"
},
"disabled": false,
"autoApprove": [
"switch_database",
"show_tables",
"show_databases",
"db_execute"
]
}
}
}
After this connection was established, the AI was immediately aware of any new table, updates in the schema and any detail it wanted, allowing it to generate the corresponding FastAPI CRUD endpoints without any “hallucinations” about column names or types.
The Spellbook: Guiding Kiro with Steering Docs
Every great experiment needs a set of protocols. While Kiro is inherently smart, we wanted to ensure it didn’t just write “generic” SQL code—we wanted it to write code that felt native to our specific TiDB setup and FastAPI architecture. We noticed that “vibe coding” without constraints often leads to minor inconsistencies in how connections are handled.
To solve this, we utilized Kiro’s Steering Docs. These are project-wide rules that act as a “spellbook” for the AI, baking our architectural decisions directly into its generation logic. In our .kiro/steering/tech.md file, we defined exactly how the “reanimation” logic should interface with our database.
With these rules in place, the foundation was set. Instead of the AI guessing which driver to use, it followed our specific requirements for the pytidb module and our preferred connection patterns. This brings us to the core problem: how do we maintain performance when joining these results under load?
Implementing the TiDB Protocol
Because Kiro was “steered” by our documentation, it knew that for our FastAPI codebase, we preferred a direct connection pattern using pytidb. This ensured that every time we asked for a new database-heavy feature—like the global “Waste Leaderboard”—it used the correct SSL configurations and query structures.
The following snippet is an example of the code Kiro generated after we provided the steering instructions. Notice how it adheres strictly to our TIDB_DATABASE_URL format and uses the certifi helper to cleanly handle SSL connections:
from pytidb import TiDBClient
def _reconnect_tidb(self) -> bool:
"""
Reconnect to TiDB if connection is lost.
Returns:
True if reconnection successful, False otherwise
"""
try:
settings = get_settings()
tidb_url = f"mysql+pymysql://{settings.tidb_user}:{settings.tidb_password}@{settings.tidb_host}:{settings.tidb_port}/{settings.tidb_database}?ssl_ca={certifi.where()}"
self._tidb_client = TiDBClient.connect(tidb_url)
self._tidb_connected = True
logger.info("TiDB client reconnected successfully")
return True
except Exception as e:
logger.error(f"Failed to reconnect TiDB client: {e}")
self._tidb_connected = False
return False
By providing these guardrails, we eliminated the struggle of fixing “hallucinated” connection strings. Under a simulated load of 1,000 concurrent “brews,” the code generated through this steered process maintained high stability. We utilized TiDB’s ability to handle these concurrent connections without the latency spikes we’ve seen in standard MySQL setups during high-traffic bursts.
The Treasure: Results and Metrics
By the end of the Kiroween hackathon, Recipe Reanimator was a fully functioning monster. We achieved a system that felt cohesive, despite its fragmented technological origins.
Under production-like testing—simulating 500 users reanimating ingredients simultaneously—the TiDB tier maintained a P99 latency of under 15ms for user profile and impact lookups. This eliminated the bottlenecks we feared when calculating real-time sustainability metrics.
| Metric | Before (Mock/Manual) | After (TiDB + MCP) |
| Schema Design Time | 4 hours | 45 minutes |
| API Development Speed | 1x | 2.5x (via Kiro) |
| Query Latency (P99) | N/A | 12-15ms |
| Data Consistency | Frequent Issues | 0 Issues |
The data suggested that using a managed service like TiDB allowed us to focus 90% of our energy on the “fun” parts—the AI prompts and the Gothic UI—rather than worrying about database reliability or connection pooling.
What’s Next: Giving the Monster More Brains
Recipe Reanimator is just the beginning. Our next step is to utilize TiFlash, TiDB’s columnar storage engine, to run real-time analytical queries across all users. We want to generate “Global Reanimation Reports” that show the collective impact of the community, which will require the kind of OLAP power that TiFlash provides without needing a separate ETL pipeline.
Under the hood, TiDB’s HTAP design lets analytics run directly on live data. This works especially well for AI systems that mix real-time interactions with analytical workloads.
If you’re building an AI application, don’t just dump your data into the first bucket you find. Consider the hybrid approach: use TiDB for what needs to be solid, and use AI tools like Kiro to bridge the gap between your code and your database.
Try it yourself:
- Deploy your first TiDB cluster for free
- Learn more about Kiro and MCP
Spin up a database with 25 GiB free resources.



TiDB Cloud Dedicated
A fully-managed cloud DBaaS for predictable workloads
TiDB Cloud Starter
A fully-managed cloud DBaaS for auto-scaling workloads