
Why Chaos Mesh?
In the world of distributed computing, faults can happen to your clusters unpredictably any time, anywhere. Traditionally we have unit tests and integration tests that guarantee a system is production ready, but these cover just the tip of the iceberg as clusters scale, complexities amount, and data volumes increase by PB levels. To better identify system vulnerabilities and improve resilience, Netflix invented Chaos Monkey and injects various types of faults into the infrastructure and business systems. This is how Chaos Engineering was originated.
At PingCAP, we are facing the same problem while building TiDB, an open source distributed NewSQL database. To be fault tolerant, or resilient holds especially true to us, because the most important asset for any database users, the data itself, is at stake. To ensure resilience, we started practicing Chaos Engineering internally in our testing framework from a very early stage. However, as TiDB grew, so did the testing requirements. We realized that we needed a universal chaos testing platform, not just for TiDB, but also for other distributed systems.
Therefore, we present to you Chaos Mesh, a cloud-native Chaos Engineering platform that orchestrates chaos experiments on Kubernetes environments. It’s an open source project available at https://github.com/chaos-mesh.
In the following sections, I will share with you what Chaos Mesh is, how we design and implement it, and finally I will show you how you can use it in your environment.
What can Chaos Mesh do?
Chaos Mesh is a versatile Chaos Engineering platform that features all-around fault injection methods for complex systems on Kubernetes, covering faults in Pod, network, file system, and even the kernel.
Here is an example of how we use Chaos Mesh to locate a TiDB system bug. In this example, we simulate Pod downtime with our distributed storage engine (TiKV) and observe changes in queries per second (QPS). Regularly, if one TiKV node is down, the QPS may experience a transient jitter before it returns to the level before the failure. This is how we guarantee high availability.

As you can see from the dashboard:
- During the first two downtimes, the QPS returns to normal after about 1 minute.
- After the third downtime, however, the QPS takes much longer to recover—about 9 minutes. Such a long downtime is unexpected, and it would definitely impact online services.
After some diagnosis, we found the TiDB cluster version under test (V3.0.1) had some tricky issues when handling TiKV downtimes. We resolved these issues in later versions.
But Chaos Mesh can do a lot more than just simulate downtime. It also includes these fault injection methods:
- pod-kill: Simulates Kubernetes Pods being killed
- pod-failure: Simulates Kubernetes Pods being continuously unavailable
- network-delay: Simulates network delay
- network-loss: Simulates network packet loss
- network-duplication: Simulates network packet duplication
- network-corrupt: Simulates network packet corruption
- network-partition: Simulates network partition
- I/O delay: Simulates file system I/O delay
- I/O errno: Simulates file system I/O errors
Design principles
We designed Chaos Mesh to be easy to use, scalable, and designed for Kubernetes.
Easy to use
To be easy to use, Chaos Mesh must:
- Require no special dependencies, so that it can be deployed directly on Kubernetes clusters, including Minikube.
- Require no modification to the deployment logic of the system under test (SUT), so that chaos experiments can be performed in a production environment.
- Easily orchestrate fault injection behaviors in chaos experiments, and easily view experiment status and results. You should also be able to quickly rollback injected failures.
- Hide underlying implementation details so that users can focus on orchestrating the chaos experiments.
Scalable
Chaos Mesh should be scalable, so that we can “plug” new requirements into it conveniently without reinventing the wheel. Specifically, Chaos Mesh must:
- Leverage existing implementations so that fault injection methods can be easily scaled.
- Easily integrate with other testing frameworks.
Designed for Kubernetes
In the container world, Kubernetes is the absolute leader. Its growth rate of adoption is far beyond everybody’s expectations, and it has won the war of containerized orchestration. In essence, Kubernetes is an operating system for the cloud.
TiDB is a cloud-native distributed database. Our internal automated testing platform was built on Kubernetes from the beginning. We had hundreds of TiDB clusters running on Kubernetes every day for various experiments, including extensive chaos testing to simulate all kinds of failures or issues in a production environment. To support these chaos experiments, the combination of chaos and Kubernetes became a natural choice and principle for our implementation.
CustomResourceDefinitions design
Chaos Mesh uses CustomResourceDefinitions (CRD) to define chaos objects. In the Kubernetes realm, CRD is a mature solution for implementing custom resources, with abundant implementation cases and toolsets available. Using CRD makes Chaos Mesh naturally integrate with the Kubernetes ecosystem.
Instead of defining all types of fault injections in a unified CRD object, we allow flexible and separate CRD objects for different types of fault injection. If we add a fault injection method that conforms to an existing CRD object, we scale directly based on this object; if it is a completely new method, we create a new CRD object for it. With this design, chaos object definitions and the logic implementation are extracted from the top level, which makes the code structure clearer. This approach also reduces the degree of coupling and the probability of errors. In addition, Kubernetes’ controller-runtime is a great wrapper for implementing controllers. This saves us a lot of time because we don’t have to repeatedly implement the same set of controllers for each CRD project.
Chaos Mesh implements the PodChaos, NetworkChaos, and IOChaos objects. The names clearly identify the corresponding fault injection types.
For example, Pod crashing is a very common problem in a Kubernetes environment. Many native resource objects automatically handle such errors with typical actions such as creating a new Pod. But can our application really deal with such errors? What if the Pod won’t start?
With well-defined actions such as pod-kill, PodChaos can help us pinpoint these kinds of issues more effectively. The PodChaos object uses the following code:
spec:
action: pod-kill
mode: one
selector:
namespaces:
- tidb-cluster-demo
labelSelectors:
"app.kubernetes.io/component": "tikv"
scheduler:
cron: "@every 2m"
This code does the following:
- The
actionattribute defines the specific error type to be injected. In this case,pod-killkills Pods randomly. - The
selectorattribute limits the scope of chaos experiment to a specific scope. In this case, the scope is TiKV Pods for the TiDB cluster with thetidb-cluster-demonamespace. - The
schedulerattribute defines the interval for each chaos fault action.
For more details on CRD objects such as NetworkChaos and IOChaos, see the Chaos-mesh documentation.
How does Chaos Mesh work?
With the CRD design settled, let’s look at the big picture on how Chaos Mesh works. The following major components are involved:
- controller-managerActs as the platform’s “brain.” It manages the life cycle of CRD objects and schedules chaos experiments. It has object controllers for scheduling CRD object instances, and the admission-webhooks controller dynamically injects sidecar containers into Pods.
- chaos-daemonRuns as a privileged daemonset that can operate network devices on the node and Cgroup.
- sidecarRuns as a special type of container that is dynamically injected into the target Pod by the admission-webhooks. For example, the
chaosfssidecar container runs a fuse-daemon to hijack the I/O operation of the application container.

Chaos Mesh workflow
Here is how these components streamline a chaos experiment:
- Using a YAML file or Kubernetes client, the user creates or updates chaos objects to the Kubernetes API server.
- Chaos Mesh uses the API server to watch the chaos objects and manages the lifecycle of chaos experiments through creating, updating, or deleting events. In this process, controller-manager, chaos-daemon, and sidecar containers work together to inject errors.
- When admission-webhooks receives a Pod creation request, the Pod object to be created is dynamically updated; for example, it is injected into the sidecar container and the Pod.
Running chaos
The above sections introduce how we design Chaos Mesh and how it works. Now let’s get down to business and show you how to use Chaos Mesh. Note that the chaos testing time may vary depending on the complexity of the application to be tested and the test scheduling rules defined in the CRD.
Preparing the environment
Chaos Mesh runs on Kubernetes v1.12 or later. Helm, a Kubernetes package management tool, deploys and manages Chaos Mesh. Before you run Chaos Mesh, make sure that Helm is properly installed in the Kubernetes cluster. To set up the environment, do the following:
- Make sure you have a Kubernetes cluster. If you do, skip to step 2; otherwise, start one locally using the script provided by Chaos Mesh:
// install kind
curl -Lo ./kind https://github.com/kubernetes-sigs/kind/releases/download/v0.6.1/kind-$(uname)-amd64
chmod +x ./kind
mv ./kind /some-dir-in-your-PATH/kind
// get script
git clone https://github.com/chaos-mesh/chaos-mesh
cd chaos-mesh
// start cluster
hack/kind-cluster-build.shNote: Starting Kubernetes clusters locally affects network-related fault injections.
- If the Kubernetes cluster is ready, use Helm and Kubectl to deploy Chaos Mesh:
git clone https://github.com/chaos-mesh/chaos-mesh.git
cd chaos-mesh
// create CRD resource
kubectl apply -f manifests/
// install chaos-mesh
helm install helm/chaos-mesh --name=chaos-mesh --namespace=chaos-testingWait until all components are installed, and check the installation status using:
// check chaos-mesh status
kubectl get pods --namespace chaos-testing -l app.kubernetes.io/instance=chaos-meshIf the installation is successful, you can see all pods up and running. Now, time to play.
You can run Chaos Mesh using a YAML definition or a Kubernetes API.
Running chaos using a YAML file
You can define your own chaos experiments through the YAML file method, which provides a fast, convenient way to conduct chaos experiments after you deploy the application. To run chaos using a YAML file, follow the steps below:
Note: For illustration purposes, we use TiDB as our system under test. You can use a target system of your choice, and modify the YAML file accordingly.
- Deploy a TiDB cluster named
chaos-demo-1. You can use TiDB Operator to deploy TiDB. - Create the YAML file named
kill-tikv.yamland add the following content:apiVersion: pingcap.com/v1alpha1
kind: PodChaos
metadata:
name: pod-kill-chaos-demo
namespace: chaos-testing
spec:
action: pod-kill
mode: one
selector:
namespaces:
- chaos-demo-1
labelSelectors:
"app.kubernetes.io/component": "tikv"
scheduler:
cron: "@every 1m" - Save the file.
- To start chaos,
kubectl apply -f kill-tikv.yaml.
The following chaos experiment simulates the TiKV Pods being frequently killed in the chaos-demo-1 cluster:
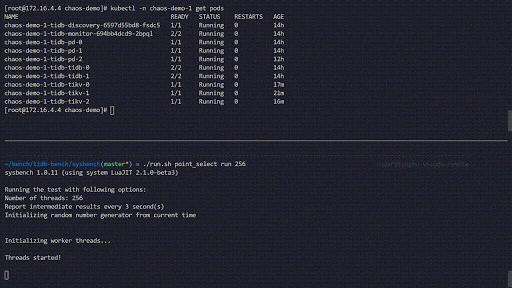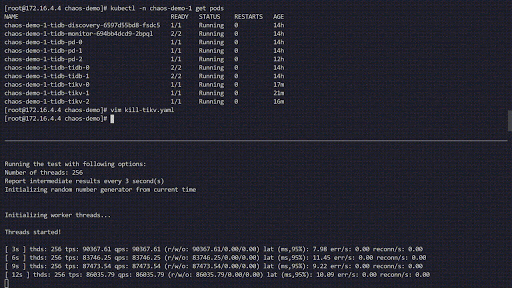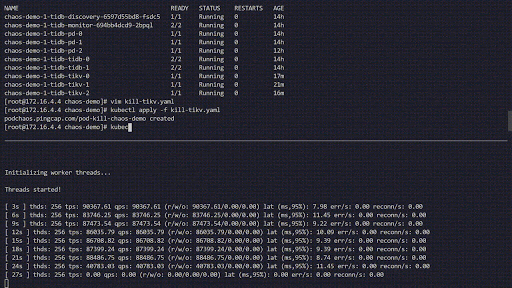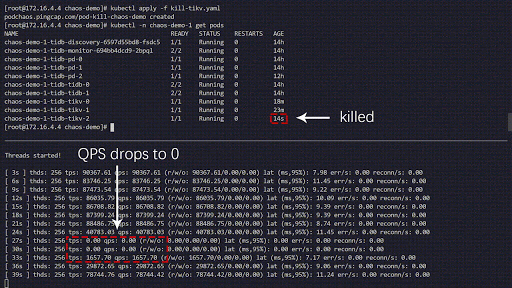
Chaos experiment running
We use a sysbench program to monitor the real-time QPS changes in the TiDB cluster. When errors are injected into the cluster, the QPS show a drastic jitter, which means a specific TiKV Pod has been deleted, and Kubernetes then re-creates a new TiKV Pod.
For more YAML file examples, see https://github.com/chaos-mesh/chaos-mesh/tree/master/examples.
Running chaos using the Kubernetes API
Chaos Mesh uses CRD to define chaos objects, so you can manipulate CRD objects directly through the Kubernetes API. This way, it is very convenient to apply Chaos Mesh to your own applications with customized test scenarios and automated chaos experiments.
In the test-infra project, we simulate potential errors in etcd clusters on Kubernetes, including nodes restarting, network failure, and file system failure.
The following is a Chaos Mesh sample script using the Kubernetes API:
import (
"context"
"github.com/pingcap/chaos-mesh/api/v1alpha1"
"sigs.k8s.io/controller-runtime/pkg/client"
)
func main() {
...
delay := &chaosv1alpha1.NetworkChaos{
Spec: chaosv1alpha1.NetworkChaosSpec{...},
}
k8sClient := client.New(conf, client.Options{ Scheme: scheme.Scheme })
k8sClient.Create(context.TODO(), delay)
k8sClient.Delete(context.TODO(), delay)
}
What does the future hold?
In this article, we introduced you to Chaos Mesh, our open source cloud-native Chaos Engineering platform. There are still many pieces in progress, with more details to unveil regarding the design, use cases, and development. Stay tuned.
Open sourcing is just a starting point. In addition to the infrastructure-level chaos experiments introduced in previous sections, we are in the process of supporting a wider range of fault types of finer granularity, such as:
- Injecting errors at the system call and kernel levels with the assistance of eBPF and other tools
- Injecting specific error types into the application function and statement levels by integrating failpoint, which will cover scenarios that are otherwise impossible with conventional injection methods
Moving forward, we will continuously improve the Chaos Mesh Dashboard, so that users can easily see if and how their online businesses are impacted by fault injections. In addition, our roadmap includes an easy-to-use fault orchestration interface. We’re planning other cool features, such as Chaos Mesh Verifier and Chaos Mesh Cloud.
If any of these sound interesting to you, join us in building a world class Chaos Engineering platform. May our applications dance in chaos on Kubernetes!
If you find a bug or think something is missing, feel free to file an issue, open a PR, or join us on the #sig-chaos-mesh channel in the TiDB Community slack workspace.
GitHub: https://github.com/chaos-mesh
Experience modern data infrastructure firsthand.



TiDB Cloud Dedicated
A fully-managed cloud DBaaS for predictable workloads
TiDB Cloud Starter
A fully-managed cloud DBaaS for auto-scaling workloads