



Schema changes at scale can be a nightmare for SaaS applications. Slow index creation, long-running schema modifications, and scalability limits can disrupt operations, making real-time database evolution nearly impossible. TiDB has been tackling these challenges head-on, continuously pushing the boundaries of distributed SQL and DDL execution.
Last year, we boosted index creation speed by 10x, enabling large-scale schema changes with minimal disruption. Now, TiDB leads the distributed SQL market in scalability, supporting up to 1 million tables—a milestone unmatched by other vendors. This makes TiDB the only truly scalable option for modern SaaS applications, where multi-tenancy and high throughput demand database architectures that can keep up.
To keep our DDL framework ahead of industry demands, we spent six months reengineering its execution process, focusing on speed, stability, and scalability. These advancements have further solidified TiDB as the go-to solution for businesses managing millions of tables.
In this post, we’ll explore:
- The key challenges faced in large-scale schema management.
- The innovative solutions we implemented to enhance DDL performance.
- How TiDB now outperforms traditional databases like MySQL and Aurora in high-scale environments.
If you work with large-scale SaaS, distributed SQL, or database performance tuning, this deep dive is for you.
Why SaaS Databases Face Unique Challenges
Modern SaaS platforms are multi-tenant, meaning each customer (tenant) operates within an isolated database structure. This can result in millions of tables, making scalability a major concern.
SaaS databases must support:
- High Scalability: Traditional single-node databases struggle to scale when handling millions of tables.
- Seamless Schema Evolution: Frequent updates to schemas should not disrupt active users.
- Operational Throughput: Thousands of schema modifications (DDL operations) need to execute without delays.
- Stability Under Concurrency: The database must maintain consistent performance under high workloads.
TiDB addresses these requirements with online DDL execution, allowing schema changes to be applied incrementally with zero downtime. Key components ensure consistency across the cluster:
- PD (Placement Driver): Orchestrates schema changes and ensures coordination.
- ETCD: Maintains consistent schema metadata across nodes.
- Metadata Locking (MDL): Prevents conflicting modifications during updates.
Together, these mechanisms allow TiDB to evolve schemas at scale without service interruptions.
Engineering Approach and Best Practices: How We Optimized TiDB’s DDL Performance
As TiDB adoption expanded into deployments with millions of tables, we encountered new performance bottlenecks. Our optimization effort followed three principles:
- Customer-Driven Focus – Prioritize fixes that matter most in production.
- Incremental Delivery – Roll out improvements in deployable steps.
- Minimal Disruption – Ensure compatibility and stability throughout.
Optimization Roadmap and Milestones
As TiDB adoption scaled into deployments with millions of tables, we encountered new performance and stability challenges. We addressed them systematically:
- TiDB 7.5 – Identified scalability bottlenecks beyond 500,000 tables, where performance began to degrade compared to MySQL 8.0.32, which could create one million tables in approximately two hours.
- TiDB 7.6 – Isolated table creation as a primary performance bottleneck and initiated targeted optimizations to improve DDL execution paths.
- TiDB 8.1 – Achieved a 118x improvement in table creation speed, reducing the time required to create one million tables to approximately four hours.
- TiDB 8.3 – Further optimizations reduced table creation time to 1.5 to 2 hours, making TiDB competitive with MySQL.
- TiDB 8.4 & 8.5 – Refactored the DDL execution code for improved maintainability and scalability.
- Future Goal – Develop a fully distributed native DDL execution framework with parallelized execution, intelligent resource scheduling, and automated workload balancing.
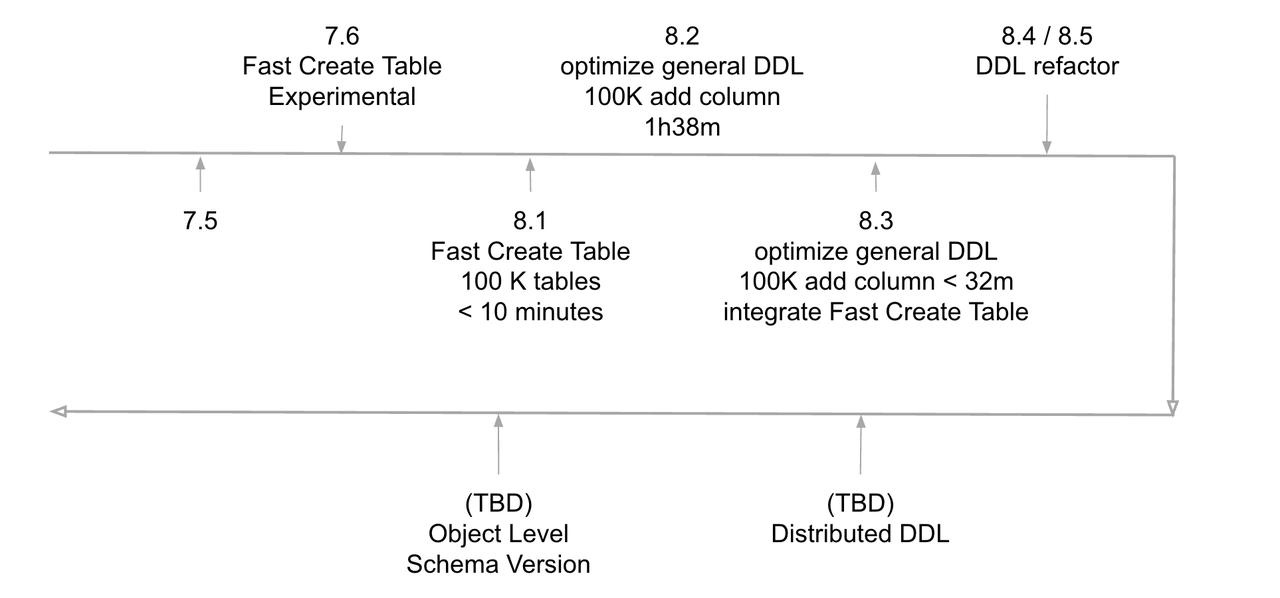
Figure 1: Optimization Roadmap and Milestones.
The following data set shows the optimized effect when we reached version 8.1.
| Table Num | TiDB 7.5 | TiDB 7.6 | TiDB 8.0 | MySQL 8.1.0 | Perf Enhancment Ratio |
| 100k | 3h30m | 26m | 9m39s | 5m30s | 21.76 |
| 300k | 59h20m | estimate > 6 hours | 30m38s | <14m | 118 |
Key Optimization Areas
We addressed multiple bottlenecks that impacted schema change performance:
- Scheduling & Concurrency – Increased scheduling granularity, allowing entire DDL tasks to run as units. Expanded worker pools to enable parallel execution of independent jobs.
- Metadata Optimization – Introduced metadata caching and removed fallback TiKV lookups, cutting redundant I/O during schema validation.
- Parallelization & Batching – Distributed table creation across nodes and merged jobs into batch transactions, significantly reducing execution overhead.
- Direct Execution – Allowed DDL statements to run directly on initiating nodes, eliminating central queue bottlenecks.
- Targeted Notifications – Replaced broadcast notifications with directional updates to reduce redundant processing.
- Global Uniqueness Checks – Leveraged indexed metadata structures to verify table name uniqueness efficiently under high concurrency.
Breakthrough Implementations
Among these changes, three drove the most impact:
- Local Execution of DDL Tasks – Removed queue latency by executing on the initiating node.
- Indexed Metadata for Global Uniqueness – Eliminated costly full scans for name validation.
- Batch Execution – Improved efficiency by grouping multiple table creation jobs into a single transaction.
Why These Enhancements Matter
These optimizations ensure that TiDB can:
- Scale seamlessly to millions of tables.
- Execute schema changes with lower latency and higher throughput.
- Compete directly with MySQL and Aurora on raw speed, while offering distributed scalability they cannot match.
By refining our DDL engine, we’ve built a future-ready foundation for distributed schema management at SaaS scale.
In-Depth Look at TiDB’s Optimization Journey
After TiDB 8.1 significantly improved table creation performance, customers quickly recognized the benefits. However, challenges remained, particularly with general DDL execution across large-scale deployments. To address these, we expanded our optimization efforts in TiDB 8.2 and beyond, focusing on improving throughput, stability, and overall execution efficiency.
Identifying Performance Bottlenecks
A detailed analysis of TiDB’s DDL execution process revealed multiple bottlenecks, particularly in large-scale multi-tenant scenarios with millions of tables. These issues stemmed from the rapid iteration of previous implementations and the need for a more scalable execution model.
The key bottlenecks included:
- Inefficiencies in DDL Task Scheduling – DDL tasks were processed sequentially with unnecessary scheduling overhead.
- Slow Database/Table Existence Checks – Schema validation relied on slower, fallback mechanisms in some cases.
- Underutilization of Computing Resources – TiDB nodes were not fully leveraged for concurrent execution.
- Inefficient Broadcasting Mechanisms – Schema changes were propagated across nodes in a way that introduced unnecessary delays.
By systematically addressing these pain points, we transformed TiDB’s DDL execution into a highly efficient, distributed process.
Optimization of DDL Task Scheduling
TiDB’s original scheduling strategy processed fine-state machine steps for each DDL statement, leading to excessive scheduling overhead.
- Adjusting Scheduling Granularity: Instead of processing fine-state steps, entire DDL tasks are now handled as a unit, reducing overhead and improving efficiency.
- Enhancing Concurrency: Independent DDL tasks now execute in parallel, maximizing system resource utilization and reducing overall execution time.
- Expanding Execution Resources: The worker pool for general DDL tasks was increased, allowing multiple tasks to run simultaneously and significantly improving throughput.
- Simplifying Scheduling Logic: Optimized algorithms reduce scheduling complexity, improving overall efficiency.
These changes resulted in a significant increase in DDL task scheduling efficiency while reducing resource consumption.
Optimizing Database/Table Existence Checks
Efficiently verifying whether a table exists is crucial for TiDB’s DDL execution performance. Currently, TiDB uses two methods to check table existence: querying an in-memory schema cache and, when necessary, falling back to a TiKV lookup. While the cache check is generally sufficient, under high-concurrency workloads, the fallback to TiKV introduces unnecessary delays.
To optimize performance, we have removed the direct TiKV lookup, relying exclusively on the schema cache for existence checks. The reasoning behind this decision is:
- Reliable Schema Cache Synchronization: The schema cache on the DDL owner node is consistently updated, ensuring correctness.
- Job Dependency Calculations: Before execution, dependencies between DDL jobs are analyzed, preventing simultaneous creation of the same table.
- Sequential Job Execution: TiDB processes DDL jobs in order, ensuring schema updates propagate correctly before subsequent jobs execute.
- Schema Reloading for DDL Owners: When a node becomes the DDL owner, it reloads schema metadata to stay synchronized with TiKV.
By exclusively relying on the schema cache, we have significantly reduced unnecessary queries to TiKV, improving execution speed and efficiency, particularly in large-scale deployments.
The following function illustrates the optimized table existence check logic:
func checkTableNotExists(d *ddlCtx, t *meta.Meta, schemaID int64, tableName string) error {
// Try to use memory schema info to check first.
currVer, err := t.GetSchemaVersion()
if err != nil {
return err
}
is := d.infoCache.GetLatest()
if is.SchemaMetaVersion() == currVer {
return checkTableNotExistsFromInfoSchema(is, schemaID, tableName)
}
return checkTableNotExistsFromStore(t, schemaID, tableName)
}We use a single task to execute worker-run generic DDL jobs serially, so in most cases, the existence check passes through the first branch, utilizing the schema cache. However, when concurrent jobs run, a node’s schema version may lag behind TiKV, forcing a fallback to the second branch, which slows execution as the number of tables increases.
Relying Solely On the Schema Cache
To improve performance, we propose eliminating the second branch and relying solely on the schema cache. This change is based on the following key observations:
- Schema Cache Reliability: The cache on the owner node is properly synchronized, ensuring that existence checks use the most up-to-date information.
- Precomputed Job Dependencies: Before execution, dependencies are analyzed to prevent concurrent table creation for the same schema objects.
- Consistency in Execution Order: Jobs execute in the order of job IDs, ensuring that updates are processed sequentially and avoiding redundant checks.
- Schema Synchronization for Ownership Transfers: When a node assumes the DDL owner role, it reloads schema metadata to guarantee alignment with TiKV.
By relying exclusively on the schema cache, we eliminate unnecessary TiKV lookups, reducing execution latency and improving system throughput. This enhancement ensures that DDL operations scale effectively with increasing workloads while maintaining consistency and correctness.
This optimization significantly improves DDL execution efficiency and system stability. Additional measures include:
- Index Optimization: Future Data Dictionary projects will introduce indexes for table/schema names to speed up lookups.
- Fault Tolerance Mechanisms: While schema cache validation is generally reliable, extra safeguards can handle extreme synchronization issues.
Improving Utilization of Computing Resources
TiDB’s schema synchronization mechanism initially relied on timed polling, where the system repeatedly checked for schema updates at fixed intervals. This approach introduced inefficiencies—frequent schema changes or slow schema loading led to excessive invalid checks, slowing down the system.
To resolve this, we adopted ETCD’s Watch mechanism. Instead of periodic polling, TiDB now listens for real-time changes in ETCD. When a schema version changes, ETCD notifies TiDB immediately, allowing for on-demand synchronization. This enhancement:
- Eliminates unnecessary polling, reducing system overhead.
- Improves response time, ensuring faster propagation of schema changes.
- Enhances resource efficiency, allowing TiDB to focus computing power on execution rather than repeated checks.
Replacing the Broadcast Mechanism for DDL Completion
Previously, TiDB relied on broadcast notifications to signal DDL completion. This approach introduced inefficiencies, as multiple submission threads would attempt to process the same notification, leading to unnecessary processing delays.
In the optimized implementation, we have replaced this with directional notifications, ensuring that only the thread responsible for a given DDL job receives the completion event. This change:
- Prevents redundant processing, reducing overall execution overhead.
- Speeds up DDL completion, allowing submission threads to finish execution promptly.
- Enhances throughput, improving TiDB’s ability to handle high-volume schema changes.
Refactoring the DDL Framework for Future Scalability
The existing DDL framework had accumulated technical debt over time, making it less adaptable to evolving business needs. To future-proof TiDB, we initiated a comprehensive refactoring of the DDL framework.
Challenges with the Previous Framework
Several issues necessitated this overhaul:
- Aging Design: The framework’s original design limited flexibility and scalability.
- Poor Code Maintainability: Years of fixes and local optimizations had led to high coupling, redundant logic, and difficult-to-read code.
- Insufficient Testing: Lack of comprehensive unit and integration tests increased the risk of regressions.
- Slow Iteration Speed: The complex code structure made modifications time-consuming and error-prone.
Refactoring Goals
The refactoring aimed to:
- Improve Code Quality: Adopting a modular, loosely coupled structure to enhance readability and maintainability.
- Enhance Testing Coverage: Implementing unit, integration, and E2E tests to ensure stability and reduce defect rates.
- Optimize Architecture: Moving towards modern architectural patterns such as microservices or domain-driven design for improved scalability and fault tolerance.
Refactoring Strategy
We adopted an incremental refactoring approach, minimizing risk while ensuring continuous improvements:
- Small, Incremental Changes: Breaking refactoring tasks into smaller steps, validating each change before proceeding.
- Continuous Integration: Using automated builds and tests to detect issues early.
- Code Reviews: Enforcing strict reviews to maintain quality and knowledge sharing.
Expected Results
The refactoring is expected to deliver:
- Greater Stability: Improved code quality reduces bugs and enhances system reliability.
- Higher Development Efficiency: A cleaner codebase speeds up modifications and debugging.
- Better Scalability: The new architecture is designed to support future expansion and feature additions.
Potential Risks and Mitigation
Refactoring introduces challenges, but careful planning mitigates risks:
- Risk: Introducing new bugs
- Solution: Implementing small, incremental changes with thorough testing.
- Risk: Slowing down feature development
- Solution: Coordinating refactoring with business requirements to ensure minimal disruption.
Key Takeaways from the Optimization Journey
Through this multi-phase optimization initiative, we successfully:
- Increased DDL execution throughput by optimizing scheduling and concurrency.
- Eliminated unnecessary schema validation bottlenecks, reducing execution time.
- Improved cluster-wide synchronization, enhancing performance under high workloads.
- Refactored the framework for future scalability, ensuring TiDB remains adaptable to emerging business needs.
By continuously refining TiDB’s DDL execution, we’re laying the groundwork for the next generation of distributed schema management.
Measuring the Impact of TiDB DDL Optimizations
After implementing these optimizations in TiDB 8.2 and 8.3, we conducted extensive benchmarking to measure their impact. The results confirm significant improvements in DDL execution throughput, scalability, and stability, making TiDB an even more powerful choice for high-scale deployments.
TiDB 8.2: General DDL Performance Gains
Comparing the DDL task execution QPS (Queries Per Second) between TiDB 8.1 and 8.2 highlights substantial performance enhancements. In TiDB 8.1, the average QPS was approximately 7, whereas in TiDB 8.2, it increased to 38, with a peak QPS of 80—a 5x improvement.
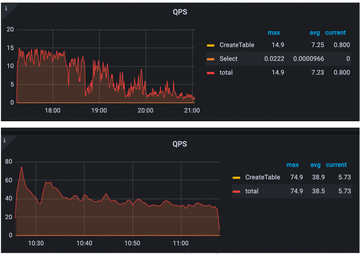
Figure 2: QPS in TiDB 8.1 and TiDB 8.2.
This data confirms that TiDB 8.2 introduced significant execution efficiency optimizations, leading to much faster DDL performance.
TiDB 8.3: Pushing Performance Even Further
Further refinements in TiDB 8.3 yielded even more substantial improvements. Compared to TiDB 8.2, the maximum QPS in TiDB 8.3 reached approximately 200, with an average QPS of 180. Performance also became more stable, demonstrating continued progress in DDL execution optimization.
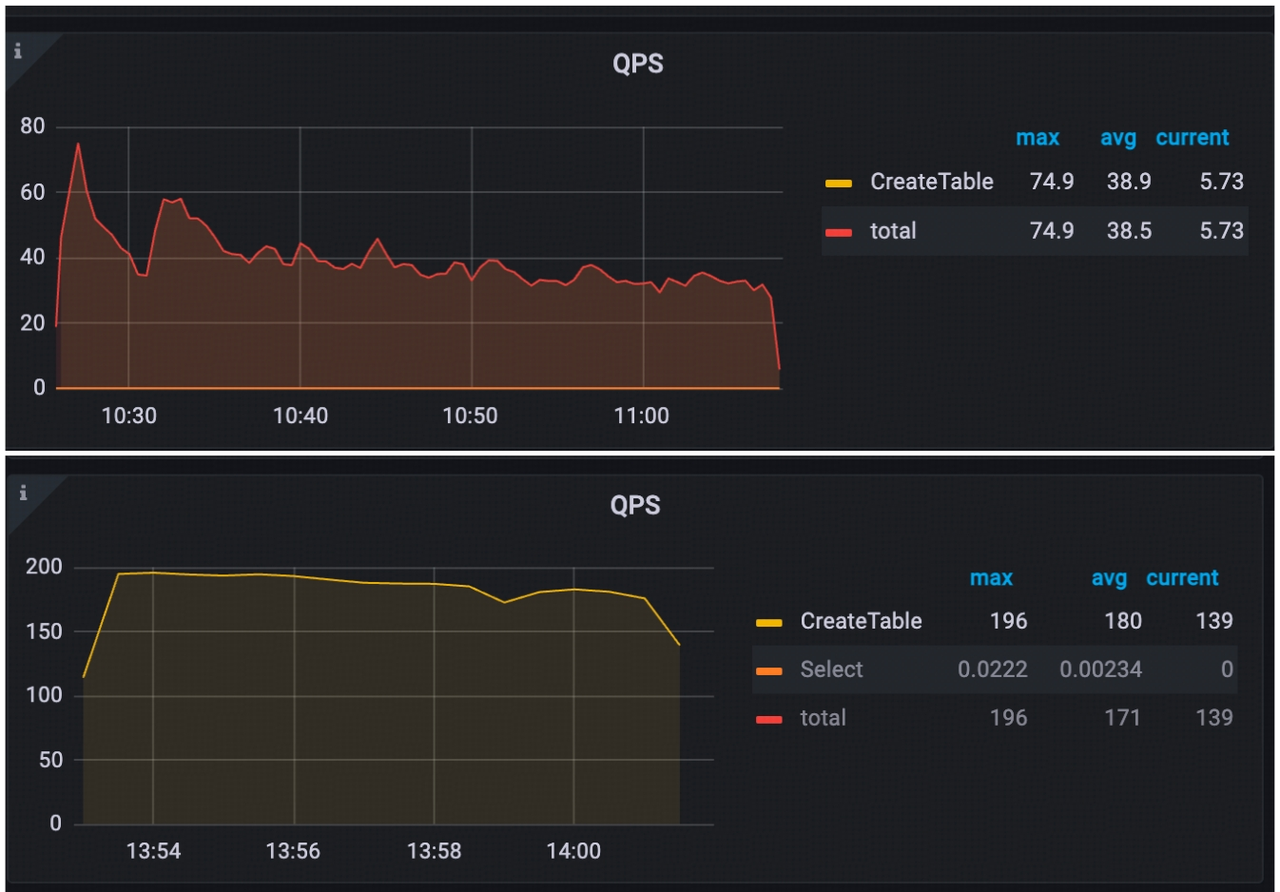
Figure 3: QPS in TiDB 8.2 and TiDB 8.3.
Additionally, enabling Fast Create Table functionality further doubled the QPS of DDL operations, significantly enhancing overall system throughput.
TiDB 8.5: Benchmarking Against MySQL and Aurora
To comprehensively evaluate DDL performance in TiDB 8.5, we set up a dedicated test cluster with the following hardware specifications:
| Node type | Number | Specifications |
| PD | 1 | 8C16G |
| TiDB | 3 | 16C32G |
| TiKV | 3 | 8C32G |
The test results are as follows:
| Operations | TiDB 7.5 | TiDB 8.5 | Description |
| Create 100K tables | 3h49m | 11m (20X faster)4m (50X faster) if Fast Create Table enabled | Create tables inside a single DB |
| Create 1M tables | more than 2 days | 1h30m (50X faster) | Create 10K schemas, each containing 100 tables |
| Create 100K schemas | 8h27m | 15m (32X faster) | |
| 100K add-column | 6h11m | 32m (11X faster) | All tables created inside a single DB |
Benchmark Comparison: TiDB vs. MySQL vs. Amazon Aurora
In direct comparisons with MySQL and Amazon Aurora, TiDB demonstrated superior scalability for large-scale DDL operations.Benchmark Comparison: TiDB vs. MySQL vs. Amazon Aurora
In direct comparisons with MySQL and Amazon Aurora, TiDB demonstrated superior scalability for large-scale DDL operations.
| EC2 to run general DDL | c5a.2xlarge (8c16g) |
| Amazon Aurora | db.r6g.2xlarge (8c64g)Aurora I/O-OptimizedAurora MySQL 3.05.2 (compatible with MySQL 8.0.32) |
| MySQL | db.m5.2xlarge (8c32g)AWS RDS MySQLMySQL 8.0.39Single DB instanceStandard classes (includes m classes)Provisioned IOPS SSD (io2) |
Benchmark test results:
| Operations | TiDB 8.5 | Amazon Aurora | MySQL |
| Create 100 tables for 10 DBs (1M total) | 1h30m | 1h24m | 1h46m |
| Create 1M tables in 4 DBs | 2h10m | 1h59m | 2h15m |
| Create 100K tables in a single DB | 8m55s | 8m31s | 12m41s |
| Add 1 column for 100K tables | 31m47 | 13m35 | 6m3 |
These results confirm TiDB’s enhanced DDL execution capabilities, demonstrating significant improvements over previous versions while achieving competitive performance against traditional databases. This progress lays a strong foundation for TiDB’s continued innovation in distributed database technology.
Summary of Benchmark Findings
The results validate TiDB’s substantial improvements in DDL execution performance while maintaining high scalability.
- TiDB’s multi-tenant capabilities allow it to handle millions of tables efficiently.
- Faster schema operations mean quicker feature rollouts for SaaS providers.
- DDL performance now rivals top cloud databases like Aurora while preserving TiDB’s distributed flexibility.
What’s Next for TiDB DDL Execution?
Moving forward, our focus will be on three key areas:
- Refining the DDL Architecture: We aim to simplify the framework, making it more intuitive and easier to maintain while enhancing its adaptability to evolving workloads.
- Futher Enhancing Stability and Performance: By further optimizing scheduling mechanisms, metadata management, and parallel execution strategies, we will ensure TiDB continues to meet the demands of high-performance workloads.
- Building a High-Throughput Distributed Execution Subsystem: Our ultimate goal is to develop a next-generation DDL execution system with high linear scalability, ensuring efficient processing of schema changes across distributed environments.
Our long-term goal is to develop a fully distributed, parallelized DDL execution framework with:
- Optimized transaction handling to improve the reliability of schema changes
- Intelligent resource scheduling to dynamically allocate resources based on workload demands
- Linear scalability to support rapid growth in multi-tenant environments
How You Can Get Involved
We invite the TiDB community, database developers, and contributors to help shape the future of DDL execution. Your insights, feedback, and contributions play a crucial role in refining our approach and driving continuous innovation.
Join us in advancing TiDB’s DDL capabilities—visit our GitHub repository to contribute, sign up for TiDB Cloud Serverless to start using TiDB today for free, or contact us to connect with our team!
Spin up a database with 25 GiB free resources.



TiDB Cloud Dedicated
A fully-managed cloud DBaaS for predictable workloads
TiDB Cloud Starter
A fully-managed cloud DBaaS for auto-scaling workloads