

Peak-moment failures are never polite. In 2015, Target’s website buckled on Cyber Monday while holiday carts sat idle. Delta canceled 1,300 flights when a single software outage rippled through critical systems. Analysts have shown that just 100 ms of extra latency trims roughly 1% of revenue, while Google observed a 20% traffic drop from a mere 0.5-second delay.
Amidst the buzz of major headlines, a silent saboteur often lurks: a legacy, single-node SQL database stretched far beyond its 1980s design center.
Why Legacy SQL Engines Hit a Wall
Classic Oracle, MySQL, and PostgreSQL were engineered for single-server payroll batches and branch terminals. They assume:
- Vertical Scale – buy a bigger box.
- Rare Failovers – active/passive plus a pager.
- Fixed Schemas – transactions are cheap, migrations are painful.
Today, those assumptions implode: microservices spew millions of writes; users expect sub-second responses from Sydney to São Paulo; hardware, containers, and even entire availability zones (AZs) fail routinely. A single primary is now both a bottleneck and a single point of failure.
The Hidden P&L of Legacy SQL Databases
| Cost Vector | Financial Hit | Root Cause |
| Lost Revenue | $350K evaporated during just five minutes of Black Friday downtime at a $100M e-commerce site | Vertical-scale single primaries cannot absorb burst traffic |
| Customer Churn | +100 ms latency → –1 % sales | Replica lag, blocking schema changes |
| Compliance Pitfalls | GDPR / CPRA fines | Single-region architectures can’t guarantee data locality |
| Innovation Drag | 30–40% of engineering budget tied up in shards, hot-fixes, fire-drills | “Get-it-right-up-front” schemas and weekends spent resharding |
Distributed SQL: The Next Evolution of Legacy SQL
Instead of one beefy server, a distributed SQL database presents a single logical SQL endpoint powered by many nodes. At its core, these databases combine the consistency of traditional SQL databases with the scalability of NoSQL.
Under the hood, each data shard is managed by its own Raft consensus group, or a multi-Raft architecture. This allows many shards to process writes in parallel while preserving strong consistency, enabling massive horizontal scalability. This design powers platforms like Google Spanner and the open-source TiDB.
| Legacy SQL | Distributed SQL |
| Manual sharding; downtime to reshard | Elastic horizontal scale – just add nodes |
| Eventually-consistent replicas | Strong consistency via consensus |
| Active/Passive high availability | Multi-region, self-healing in seconds |
| OLTP or OLAP | Hybrid transactions + realtime analytics |
How Distributed SQL Works
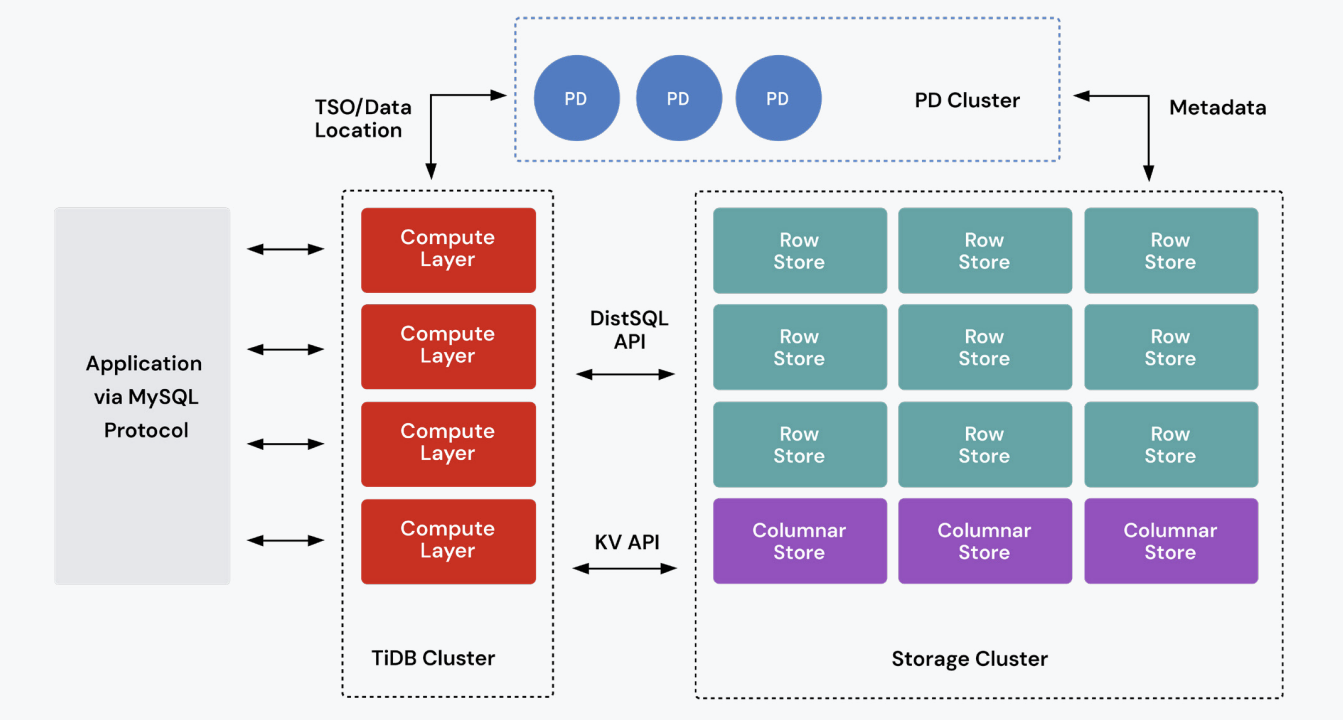
Executive takeaway: Data is automatically partitioned and safely replicated so any node loss, or entire region loss, stays invisible to customers.
For more context, let’s picture a busy restaurant on a Saturday night. In this scenario, a legacy SQL system is like a kitchen with a single chef. Every dish (appetizer, entrée, dessert) passes through that one person. It works fine at low volume, but when orders spike, the chef becomes the bottleneck. If they get overwhelmed or injured, service stalls and diners leave.
Now imagine a distributed SQL system. It’s a kitchen brigade with specialized stations: grill, sauté, pastry, cold prep. Each one handles its own orders in parallel, and an expediter (that’s Raft consensus) checks that every component is ready and correct before it hits the table. If one cook steps out, another takes their place. Customers never notice a blip.
What this really means for your database:
- Stations = shards of data distributed across multiple nodes.
- Each station can write independently, allowing throughput to scale linearly with demand.
- The expediter = Raft consensus, which ensures every transaction is consistent and committed safely.
- Swapping cooks = automatic failover and rebalancing, so node failures are invisible to users.
You still get strong consistency (like legacy SQL), but now with massive horizontal scale and real fault tolerance. This is just like a fully-functioning restaurant kitchen that keeps serving even during the rush.
Proof on the Ground
Real-world results speak louder than benchmarks. Leading companies are already proving how distributed SQL eliminates legacy limitations at scale. For example:
- Flipkart retired 700 MySQL clusters, consolidating onto an open source mysql-compatible distributed SQL database (TiDB) that now handles hundreds-of-thousands of reads/writes per second during mega-sale events.
- Catalyst rearchitected its core SaaS platform to TiDB (from PostgreSQL + Elasticsearch), achieved 60× faster query performance and reduced ops/storage cost and complexity.
- Zhihu (500 TB, 1.3 T rows) operates a single TiDB distributed SQL cluster while keeping millisecond‑level query times for large datasets.
These are tier-0 production workloads where a missed query equals lost dollars.
Is Your Legacy SQL Stack a Time Bomb?
If your team is fighting fires instead of shipping features, your legacy SQL stack might be holding you back. Here’s how:
- Are 20% dev cycles spent on schema or capacity work-arounds?
- Are you archiving “cold” data just to stop write amplification?
- Are regional expansion projects measured in quarters?
- Is a four-minute outage ≥ $50 K?
- Are data-residency fines a board-level risk?
If you nodded twice, it’s time to consider a distributed SQL database.
First Steps Toward Freedom
Modernizing your database doesn’t require a risky overhaul. You need to start small, prove impact, and scale with confidence. Here are some tips for getting started:
- Pick a high-pain service. Hot shard, global feature, or analytics sidecar.
- Run a live-migration drill. Most platforms ship bulk-load + change-stream tools that cut over with near-zero downtime.
- Set measurable goals (e.g., p99 < 100 ms at 2× TPS; failover < 30s).
- Plan coexistence. Distributed SQL speaks MySQL or Postgres wire protocols – adopt incrementally, not via big-bang.
Strategic Payoff
| Initiative | Legacy Costs | Distributed SQL Outcome |
| Going Global | 3–6 mo shard project | 1-line placement rule; live geo-rebalance |
| Product Analytics | ETL lag + DW bill | Run OLTP & real-time OLAP on same data |
| SRE Burnout | Night pages for replica lag | Self-healing architecture meets SLAs |
| Cloud Lock-In | Vendor exit fees | Open-source core, multi-cloud flexibility |
The Bottom Line
Stable checkouts don’t earn applause; they quietly grow revenue. Seamless deploys won’t trend on social-media; they free engineers to build. And the CFO will notice when the database spend flattens while traffic soars.
Waiting means continuing to scale a legacy SQL time bomb until a peak event detonates it. Upgrading to distributed SQL turns that time bomb into a foundation for continuous innovation.
Download our comparison white paper to learn how distributed SQL compares to popular legacy SQL databases such as traditional MySQL.
Experience modern data infrastructure firsthand.



TiDB Cloud Dedicated
A fully-managed cloud DBaaS for predictable workloads
TiDB Cloud Starter
A fully-managed cloud DBaaS for auto-scaling workloads