
Introduction





TiDB vs MySQL: Side-by-Side Comparison Table
| Criteria | TiDB | MySQL |
| Primary use | Distributed SQL / NewSQL for scale-out OLTP; MySQL-compatible; optional HTAP via TiFlash | Relational OLTP, typically single primary + replicas |
| SQL / protocol compatibility | MySQL protocol + common syntax; validate compatibility limitations in a POC | Native MySQL |
| Consistency & transactions | ACID transactions with strong consistency; supports distributed transactions (validate isolation semantics for your workload) | ACID transactions on a single primary; replication topologies vary |
| Scaling model | Horizontal scaling: add nodes; separate compute (TiDB) and storage (TiKV/TiFlash) | Scale up primary; scale reads with replicas; write scaling often requires architectural changes |
| HTAP / analytics | TiFlash columnar replicas for analytical queries on the same data via async replication | Analytics typically offloaded to a separate OLAP system/warehouse |
| Multi-region / locality | HA/topologies across failure domains; multi-region patterns possible with locality/latency tradeoffs | Multi-region patterns depend on deployment and replication approach; locality tradeoffs apply |
| Operations & reliability | HA by design in clustered deployments; backups + restore workflows; PITR available when configured | HA/DR and PITR depend on tooling and operational approach |
| Ecosystem & integrations | Kubernetes-friendly; CDC/streaming ecosystem; observability integrations | Broad ecosystem; ops patterns vary by distro/vendor tooling |
| Implementation / migration | “MySQL-compatible” reduces rewrite scope vs non-MySQL systems | N/A |
| Pricing | TiDB Self-Managed or TiDB Cloud; cost depends on topology, usage, and support | MySQL community + managed offerings; costs vary by vendor and architecture |
| Sharding burden | Sharding is handled inside the database (automatic distribution/replication), reducing app-owned shard routing and resharding work | Sharding is usually an application/ops responsibility (routing, resharding, cross-shard patterns, operational overhead) |
| Cross-partition transactions and joins | Supports distributed transactions and joins across the cluster (validate latency and contention behavior in your workload) | Strong within a single primary; cross-shard transactions/joins (if sharded) require application patterns or additional systems |
| Online schema changes (DDL) | Designed for operational continuity in clustered environments; validate online DDL duration and impact under load | Online schema change patterns vary by version/tooling; large-table changes often require careful ops planning and can become painful at scale |
| Change Data Capture (CDC) | Commonly implemented with dedicated CDC tooling (e.g., TiCDC) to stream changes to downstream systems | CDC typically relies on binlog-based approaches and tooling; ergonomics and capabilities vary by distribution and ops setup |
| Bulk data ingestion and backfills | Supports bulk-load workflows (e.g., TiDB Lightning) for large imports/backfills in controlled ways | Bulk loads are possible (LOAD DATA, batched inserts), but large backfills can pressure the primary and require careful throttling |
Table 1. Side-by-side of compatibility, scaling, consistency, HTAP, operations, and pricing.
TiDB vs MySQL Overview (Quick Take)
MySQL is typically the best choice for OLTP workloads that fit a single primary plus replicas. TiDB is built for teams that need to scale beyond that model with a distributed SQL database that preserves the MySQL developer experience while scaling out writes and storage.
TiDB in Brief: Distributed SQL + NewSQL + HTAP Database
TiDB is an open-source Distributed SQL database that is MySQL-compatible at the application layer and designed to scale out. It uses TiKV for distributed transactional storage and TiFlash columnar replicas to support HTAP workloads when you need analytics on fresh OLTP data.
MySQL in Brief: Why It’s Great—and Where MySQL Scalability Breaks
MySQL is a strong default for OLTP. As workloads grow, teams typically scale reads with replicas, while writes concentrate on the primary. When write throughput, data volume, or operational complexity outgrows the model, teams often evaluate sharding, complex HA/DR, or splitting OLTP and OLAP into separate systems.
If sharding is entering the conversation, start here: MySQL sharding: definition and alternatives.
Key Differences: When TiDB Wins vs When MySQL Wins
TiDB wins when scale introduces architectural change in MySQL, such as sharding, complex HA/DR, or splitting OLTP and OLAP into separate systems. MySQL still wins when the simplest single-primary architecture meets your performance, reliability, and growth needs.
No Manual MySQL Sharding (Elastic Scale-Out)
TiDB is built to reduce the need for application-level sharding by distributing data and load across the cluster, while keeping a single logical SQL database.
Where MySQL still wins: When your workload is still comfortably served by a single primary (plus replicas) and you want the simplest possible architecture without introducing a distributed system.
ACID Transactions + Distributed Transactions at Scale
TiDB is designed for ACID correctness at scale, including workloads that require distributed transactions. Learn more: Distributed transactions in TiDB.
Where MySQL still wins: When your transactional workload fits on a single primary and you do not need cross-node transaction coordination, which keeps latency and operational complexity lower.
HTAP Analytics with TiFlash (Fresh OLTP Data)
If you are splitting OLTP and OLAP across systems and fighting ETL lag, TiDB can serve analytical queries from TiFlash columnar replicas against the same underlying data. Learn more: HTAP databases: OLTP vs OLAP in one system.
Where MySQL still wins: When analytics needs are light (or already handled well in a separate warehouse) and you prefer to keep OLTP isolated from analytical workloads entirely.
High Availability Database + Point-in-Time Recovery (PITR)
TiDB supports high availability through Raft-based replication of data across multiple nodes, plus recovery workflows including point-in-time recovery (PITR) when configured, for teams tightening RPO/RTO.
Where MySQL still wins: When HA and recovery requirements are straightforward and you are satisfied with established MySQL HA/backup patterns, without needing Raft-replicated, distributed HA behavior across a cluster.
Cloud-Native Database Operations on Kubernetes
TiDB supports cloud-native operations and is commonly deployed and managed with Kubernetes workflows for platform teams.
Where MySQL still wins: Workloads that fit comfortably on a single primary and prefer the simplest possible operational model.
Architecture: How TiDB Scales Beyond Single-Node MySQL
TiDB scales differently because it separates SQL compute (TiDB) from distributed transactional storage (TiKV) and optional columnar analytics replicas (TiFlash), then distributes data automatically so scale does not depend on application-owned shards.
TiDB, TiKV, TiFlash, and Placement Driver: the HTAP Architecture in Plain English
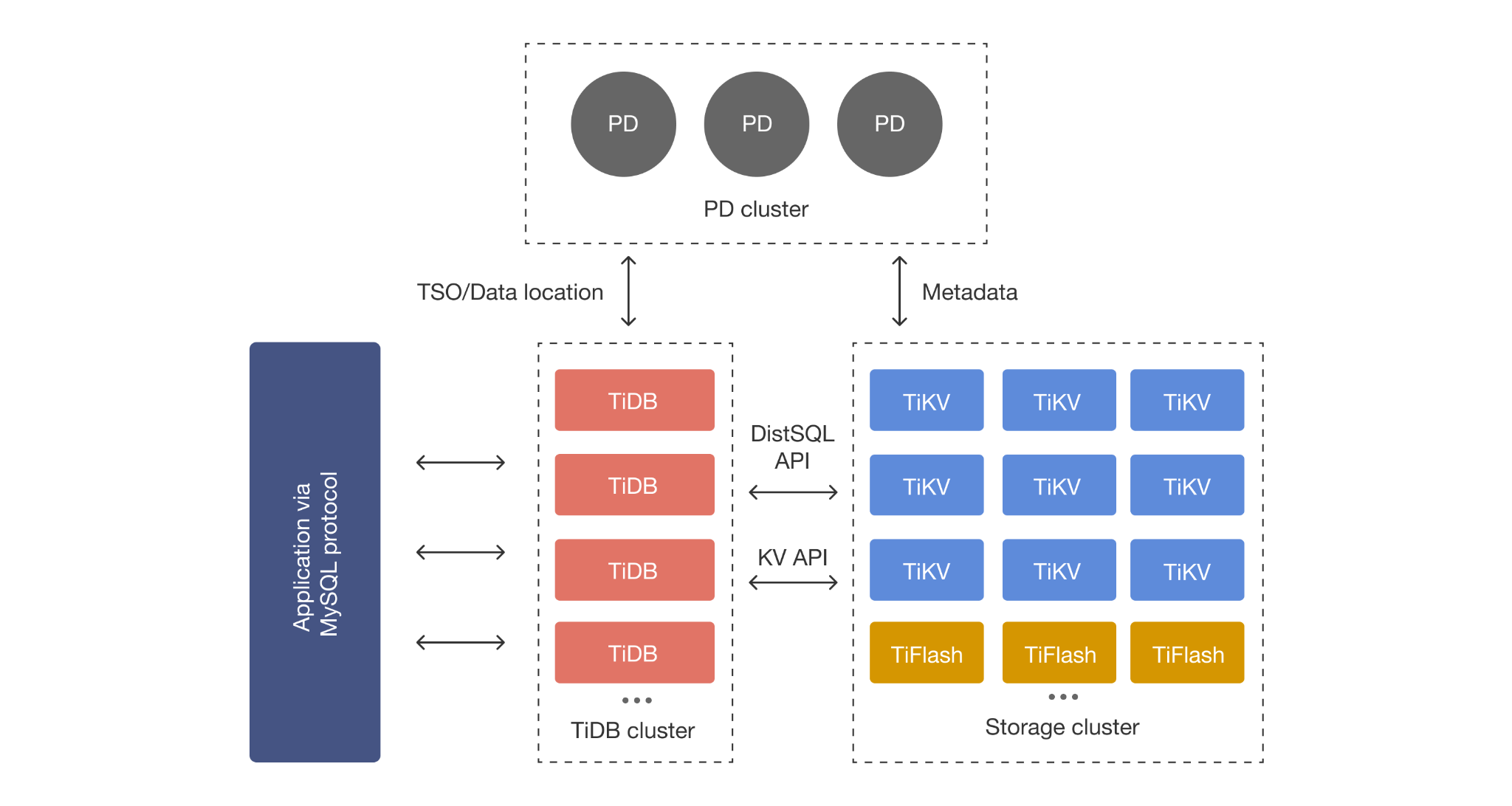
- TiDB: Stateless SQL layer for parsing, planning, and distributed execution.
- TiKV: Distributed transactional (row-oriented) storage.
- TiFlash: Columnar replicas for analytics and mixed workloads.
- Placement Driver: Cluster control plane that manages metadata and placement decisions.
Automatic Sharding and Database Partitioning (What You Manage vs TiDB)
In MySQL, once you outgrow a single primary, sharding and many partitioning decisions become application and operational responsibilities: Choosing shard keys, routing queries, resharding, and dealing with cross-shard joins and transactions.
In TiDB, the cluster handles distribution automatically. TiKV splits data into key-range Regions (tens to hundreds of MB, configurable) that are Raft-replicated across nodes, while Placement Driver (PD) schedules and rebalances Region replicas and leaders as data and traffic change. SQL partitioning remains optional and is mainly used for manageability and query pruning, not as a prerequisite for horizontal scale.
Learn more: Database partitioning (SQL partitioning) explained.
MySQL Compatibility (and Key Limitations to Validate)
TiDB is MySQL-compatible at the protocol level and supports common MySQL syntax and ecosystem tooling, but it is not “zero-effort identical.” The right way to de-risk migration is a focused POC on your heaviest queries, transaction edge cases, and operational workflows.
Protocol, Syntax, Drivers, and ORM Surface Area
TiDB is MySQL-compatible at the protocol level and supports common MySQL syntax and ecosystem tooling. You should still validate feature differences and edge cases based on your application.
POC Checklist: Query Patterns and SQL Features to Test
- Top OLTP query paths (latency under concurrency).
- Transaction patterns (contention, retries, long transactions).
- MySQL-specific SQL features you depend on such as stored procedures and triggers.
- Backups, restores, failure drills, and upgrade workflows.
Consistency & Transactions: ACID Compliance in a Distributed SQL Database
Both systems support ACID transactions, but the evaluation differs because TiDB coordinates transactions across a distributed cluster. You should validate isolation expectations, contention behavior, and failure behavior under load, because distributed coordination can add latency tradeoffs.
ACID Transactions: What Stays the Same vs MySQL
If your application depends on ACID correctness, the evaluation should focus on transactional behavior, isolation expectations, and operational behavior during failures.
Distributed Transactions: Latency and Tradeoffs to Understand
Distributed transactions introduce coordination and latency tradeoffs compared to a single-node primary. The upside is the ability to scale writes and storage while preserving a single logical SQL database.
Scaling & Performance: MySQL Scalability vs Horizontal Scaling in TiDB
MySQL scales by pushing a single primary harder and scaling reads with replicas, while TiDB scales out by adding nodes and distributing data and traffic across the cluster. The practical difference is whether scaling writes forces application sharding and operational overhead.
OLTP at Scale: Add Nodes Instead of Bigger Boxes
TiDB is designed as a horizontal scaling database. You scale by adding nodes and distributing workload across the cluster rather than relying only on vertical scaling.
MySQL Sharding vs TiDB Auto-Sharding: Operational Overhead Comparison
With MySQL sharding, teams typically own shard routing, resharding, cross-shard patterns, and operational complexity. TiDB is designed to reduce this overhead by handling data distribution inside the database.
HTAP Analytics: OLTP vs OLAP Without a Separate Warehouse
If you need analytics on fresh operational data, TiDB supports HTAP by serving analytical queries from TiFlash columnar replicas against the same underlying data. That reduces not only ETL lag, but also the security exposure and compliance overhead that comes from copying sensitive data into additional systems, plus the ongoing cost and operational burden of running two platforms. MySQL typically requires offloading analytics to a separate OLAP system or warehouse for performance and concurrency at scale.
What HTAP Means (and When It Matters)
HTAP (Hybrid Transactional and Analytical Processing) matters when you want accurate, timely analytics on operational data while minimizing data movement, attack surface, and platform sprawl. It is most valuable when you are repeatedly answering questions that depend on up-to-date production data, and when duplicating that data across systems creates risk and cost.
TiFlash: Columnar Replicas for Real-Time Analytics
TiFlash provides columnar replicas that serve analytical queries against the same underlying data, enabling mixed OLTP + OLAP patterns without exporting data to a separate warehouse for every use case.
Multi-Region & Locality: What’s Realistic for Writes and Reads
Multi-region always introduces tradeoffs between latency and consistency, so the real question is what you are optimizing for: failover resilience, read locality, or multi-region write requirements. Evaluate both TiDB and MySQL topologies based on those constraints, not marketing promises.
Single-Region HA vs Multi-Region Reads vs Multi-Region Writes
Multi-region designs always involve tradeoffs between latency and consistency. Evaluate topology patterns based on what you need most: Failover resilience, read locality, or multi-region write requirements.
Operations & Reliability: HA, Backups, and PITR
Operational reliability is defined by what happens during failures and how quickly you can recover, not just benchmark performance. Compare HA behavior during AZ failures, backup/restore workflows, and PITR requirements, because these determine your real RPO/RTO.
High Availability Database Behavior During AZ Failures
Operationally, the question is not “does it scale,” but “what happens during failures.” TiDB is commonly deployed across failure domains and designed for HA patterns that platform teams can drill and test.
Point-in-Time Recovery (PITR): What It Is and Why It Matters
PITR matters for incidents like operator error or bad deployments where restoring to a specific moment can reduce business impact.
Enterprise-Grade Security (Encryption in Transit/At Rest)
Enterprise evaluation usually requires encryption in transit and at rest. Confirm your required controls and deployment model early in the POC.
Ecosystem & Integrations: Kubernetes, CDC, and Observability
For platform teams, ecosystem fit is about day-to-day operability: Kubernetes workflows, CDC pipelines, and clean observability integration. Evaluate the tooling you will actually run in production, including upgrades, backups, failure recovery, and streaming integrations.
Kubernetes Database Operator: Deploy, Scale, Upgrade with Confidence
If your platform standard is Kubernetes, the key question is operability: Upgrade workflows, scaling, backup automation, and failure recovery.
Learn more: TiDB Operator for Kubernetes.
CDC Pipelines and Streaming Integrations (Operational + Analytics)
Modern architectures often require CDC for downstream systems, streaming pipelines, and operational analytics.
Learn more: TiCDC change data capture.
Observability Integrations
Operational confidence depends on monitoring, alerting, and tracing. Ensure the database integrates cleanly with your observability stack.
Learn more:
Implementation & Migration: Moving from MySQL to TiDB
A safe MySQL-to-TiDB migration is a three-step process: Assess compatibility, migrate and validate data correctness and performance, then choose a cutover strategy that matches your risk tolerance. The goal is to prove behavior on your workload before changing production traffic.
Step 1: Schema + Compatibility Assessment
Start by inventorying schema features, key queries, and MySQL-specific behavior your application depends on.
Step 2: Data Migration + Validation
Plan validation: Row counts, checksums, application read-path correctness, and performance under concurrency.
Step 3: Cutover Strategy (Dual-Write vs Controlled Switchover)
Choose rollout mechanics that match your risk tolerance: Staged cutover, controlled window, or dual-write, depending on constraints.
Learn more: MySQL to TiDB migration guide.
Pricing: TiDB Cloud vs Self-Managed TCO
The useful cost comparison is not list price. It is whether your architecture keeps TCO predictable as you scale, based on concrete drivers like compute, replicas, backups/PITR retention, cross-region traffic, and operational labor.
Cost Drivers to Compare (Compute, Storage, Backups, Egress, Support)
Compare total cost based on:
- Steady-state and peak compute
- Storage footprint and replicas
- Backup retention and PITR requirements
- Network egress and cross-region traffic
- Operational labor and support
Pros & Cons: TiDB and MySQL
To make the tradeoff concrete, here is what each option is objectively strong at, along with the practical constraints you should validate before committing.
Learn more: TiDB Cloud pricing.
TiDB Pros for Scale-Out OLTP + HTAP
- Distributed SQL / NewSQL design for horizontal scaling.
- ACID transactions built for scale-out systems.
- HTAP path with TiFlash columnar replicas.
- Cloud-native operations, including Kubernetes workflows.
TiDB Tradeoffs to Validate in Your Workload
- Transaction and latency tradeoffs in distributed systems.
- Compatibility edge cases based on your MySQL usage.
- Operational preferences: self-managed vs managed cloud.
MySQL Pros and Constraints at Scale
- Extremely mature ecosystem and talent pool.
- Simple single-primary operational model.
- Scaling writes and mixed workloads can push teams toward sharding, complex HA/DR, or OLTP/OLAP split.
Who Should Choose TiDB vs MySQL?
Use this section as a quick decision filter based on your scaling and operational requirements, so you can align the choice to the architecture you actually need rather than what is easiest today.
Choose TiDB if You Need Scale-Out + ACID + HTAP
Choose TiDB when you need a distributed SQL database that can scale out, preserve ACID correctness, and support HTAP patterns on the same data.
Try TiDB Cloud and spin up a MySQL-compatible TiDB cluster in minutes, so you can validate scale-out performance and HTAP analytics on your own workload.
Choose MySQL if Your Workloads Fit Single-Node + Simpler Ops
Choose MySQL when your workload fits comfortably on a single primary and your operational model stays simple.


