

Key Takeaways
- Multi-writer CDC must globally order events from millions of independent regions, far harder than tailing a single binlog.
- TiCDC (in TiDB 8.5+) uses four independently scalable components: Upstream Adapter, Log Service, Downstream Adapter, and Coordinator.
- Global TSO ordering, multiplexed gRPC streams, and disk-backed PebbleDB storage solve the core scaling bottlenecks.
- The new architecture removes the previous 700 MB/s ceiling, enabling linear scalability beyond 250 TBs.
What Is Multi-Writer Change Data Capture (CDC)?
Change Data Capture (CDC) is a pattern for tracking and propagating data changes in real time, powering use cases like downstream synchronization, auditing, event streaming, and real-time analytics. In a single-writer CDC system (e.g., MySQL binlog, PostgreSQL WAL replication), one node handles all writes, producing a single sequential log that makes event ordering implicit. In a multi-writer CDC system, multiple nodes accept writes simultaneously. This dramatically increases throughput, but it also means there is no single log to consume. That means events must be collected from many independent sources and merged into a globally consistent order before they reach downstream consumers.
Multi-writer CDC is the infrastructure layer that makes this possible. It is essential for any distributed database that supports concurrent writes across shards or nodes, such as TiDB, CockroachDB, or Google Spanner. Without a purpose-built multi-writer CDC solution, teams are forced to build fragile, custom synchronization pipelines that are difficult to maintain and impossible to scale.
The Single-Writer Model: How Traditional Replication Works
To understand why multi-writer CDC is hard, it helps to start with the traditional model that databases like MySQL and PostgreSQL use. These systems have served the industry well for decades, but they carry inherent limitations when scaling to modern distributed workloads.
- Single source of truth: A single node handles all writes, ensuring a clear and unambiguous order of operations.
- Sequential log: Transactions are committed to a single log (e.g., MySQL binlog or PostgreSQL WAL), making event ordering implicit and straightforward. This simplicity comes at the cost of scalability.
- Linear consumption: Data flows from one producer to multiple consumers, much like a simple queue. While easy to reason about, this creates bottlenecks as write volume increases.
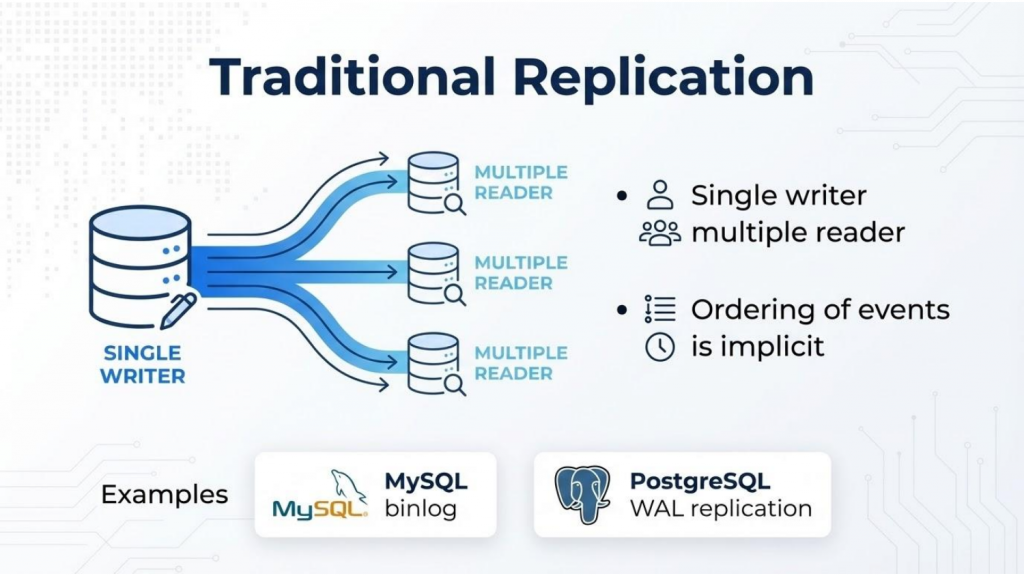
Figure 1: Traditional single-writer replication model: Single writer, multiple readers, implicit event ordering.
The TiDB Challenge: Why Distributed Writes Demand a New Approach
TiDB’s architecture is fundamentally different from traditional databases. It was designed from the ground up to be a distributed, cloud-native system that handles massive scale while maintaining strong consistency guarantees. This design creates three core challenges for CDC:
- Multi-writer capability: Multiple TiDB SQL nodes can handle writes simultaneously, dramatically increasing throughput but introducing ordering complexity. Unlike traditional systems where a single binlog provides natural ordering, TiDB must coordinate across many independent writers.
- Automatic sharding: Data is split into millions of small units called Regions (similar to tablets in Google Spanner), each managed as a Raft consensus group. This provides resilience and scalability, but means the CDC layer must track changes across independent consensus groups.
- Massive scale: A production TiDB cluster can easily reach 250+ TB with millions of Raft groups, making a single-threaded replication model impossible. The sheer volume of concurrent changes demands a fundamentally different approach to change data capture.
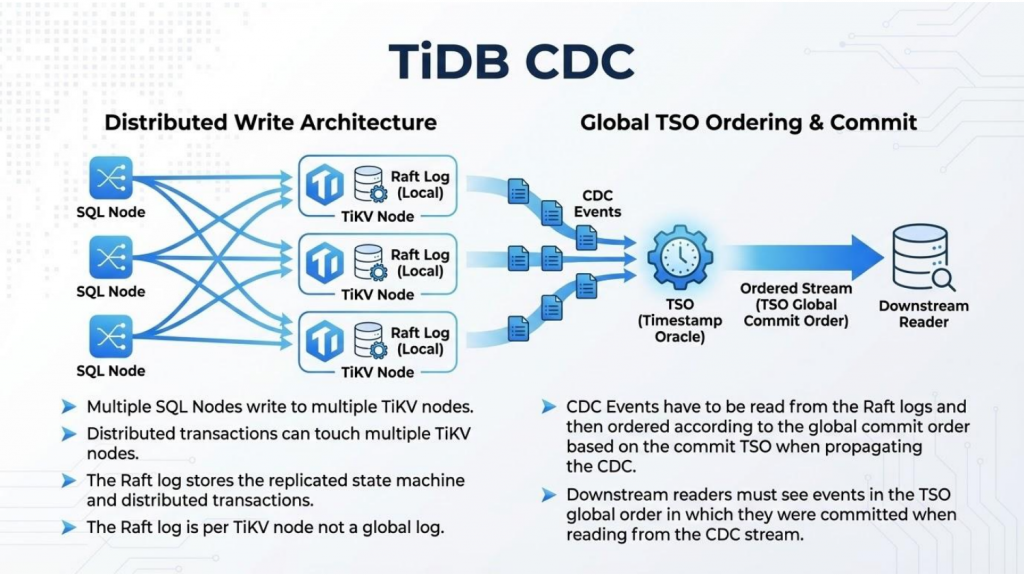
Figure 2: TiDB CDC distributed write architecture with Global TSO ordering.
The Heart of TiCDC: A Four-Component Distributed Architecture
To handle this scale, TiCDC was reimagined from a centralized node into a distributed system built on four key components, each designed to scale independently and work together seamlessly. The following table summarizes each component before we dive into detail:
| Component | Role | Scaling Model |
| Upstream Adapter | Pulls changes from TiKV storage nodes via the Coprocessor Observer pattern | Horizontal (region distribution) |
| Log Service | Persistent event storage on disk (PebbleDB); decouples collection from processing | Independent (shared across changefeeds) |
| Downstream Adapter | Data conversion and delivery to sinks (Kafka, MySQL, etc.) via Mounter + Dispatcher | Per-sink (add new sinks without core changes) |
| Coordinator | Cluster orchestration, scheduling, and metadata (etcd); control plane only, never touches data | Single instance (no data-plane load) |
Upstream Adapter
The Upstream Adapter pulls changes directly from TiKV storage nodes. It uses the Coprocessor Observer pattern to hook into RaftStore, allowing it to observe changes without intercepting Raft messages. It scales horizontally by distributing regions across multiple adapter instances.
Log Service
The Log Service is a stateful component that provides persistent event storage on disk using PebbleDB, an LSM-tree based store. By decoupling data collection from processing, it allows the system to handle massive throughput without memory overflows. Multiple changefeeds can share a single Log Service instance, significantly improving resource efficiency.
Downstream Adapter
The Downstream Adapter manages data conversion and pushes events to targets like Kafka, MySQL, or other third-party sinks. It includes specialized sub-components: the Mounter for schema resolution and the Dispatcher for routing events to appropriate destinations.
Coordinator
The Coordinator orchestrates the cluster, handles scheduling, and manages metadata in etcd. Critically, it has no data-plane responsibilities. It only handles control-plane operations like changefeed lifecycle management and workload balancing, preventing it from becoming a bottleneck.
Overcoming Engineering Challenges in Multi-Writer CDC
Building a multi-writer CDC solution at this scale requires solving several non-trivial problems. Each challenge demanded innovative solutions that balance performance, correctness, and operational simplicity.
How Does TiCDC Handle Event Ordering Across Millions of Regions?
TL;DR: TiCDC uses a Global Timestamp Oracle (TSO) to enforce total ordering and sets DDL barriers to guarantee that all preceding DML events are replicated before any schema change executes downstream.
In a multi-writer system, events arrive from millions of regions simultaneously. Without proper ordering, downstream systems could see schema changes before the data they apply to, leading to catastrophic failures. TiCDC’s solution establishes a total order across all events using the TSO. It sets a “barrier” for Data Definition Language (DDL) changes, ensuring the execution order is always DML → DDL → DML. This guarantee is critical for maintaining data integrity and preventing replication errors.
Figure 3: The DML → DDL → DML execution order ensures schema correctness.
How Does TiCDC Manage High Region Counts and Memory Pressure?
TL;DR: Multiplexed gRPC streams reduce per-region connection overhead, while disk-backed PebbleDB storage eliminates memory exhaustion even during downstream slowdowns.
At massive scale, even small per-region overhead compounds into significant resource consumption. The new architecture addresses this through two key innovations:
- Multiplexed streams: TiCDC uses a single gRPC stream per TiKV node to handle thousands of regions, dramatically reducing connection overhead. Before this optimization, each region required its own stream, leading to network amplification and connection exhaustion.
- Disk-backed storage: Events are stored in PebbleDB (an LSM-tree based store) instead of memory, allowing the system to handle massive throughput without crashing. This shift from memory to disk also enables backpressure management. This means when downstream sinks slow down, events safely accumulate on disk rather than causing out-of-memory errors.

Figure 4: Scaling challenges at 1 million regions across 3 TiKV nodes.
How Does TiCDC Handle Online Schema Changes?
TL;DR: The Mounter component tracks schema versions and applies the correct schema snapshot to each event based on its commit timestamp, even as the schema evolves concurrently.
Unlike traditional databases where schema changes might block replication, TiDB supports online DDLs that execute without locking tables. This creates a unique challenge for CDC: The schema can evolve while events are being captured and processed. TiCDC must maintain a local version of the schema to decode events correctly, even as the schema evolves in the background. The Mounter component handles this by tracking schema versions and applying the correct schema snapshot to each event based on its commit timestamp.
Architecture Evolution: From Centralized to Distributed
The journey from TiCDC’s previous architecture to the new TiDB 8.5 design represents a fundamental rethinking of how CDC should work at scale. The following table highlights the key improvements:
| Metric | Previous Architecture | New Architecture (TiDB 8.5+) |
| Max Throughput | ~700 MB/s (Owner bottleneck) | Linear scaling (no single bottleneck) |
| DDL Throughput | ~3 DDLs/second | Sub-millisecond latency, event-driven |
| Event Storage | In-memory (OOM risk) | Disk-backed (PebbleDB) |
| Processing Model | 50ms timer-based polling | Event-driven, no polling overhead |
| Changefeed Support | Limited by memory | Hundreds per cluster (shared Log Service) |
| Failure Handling | Centralized Owner = SPOF | Coordinator is control-plane only; replication continues during failures |
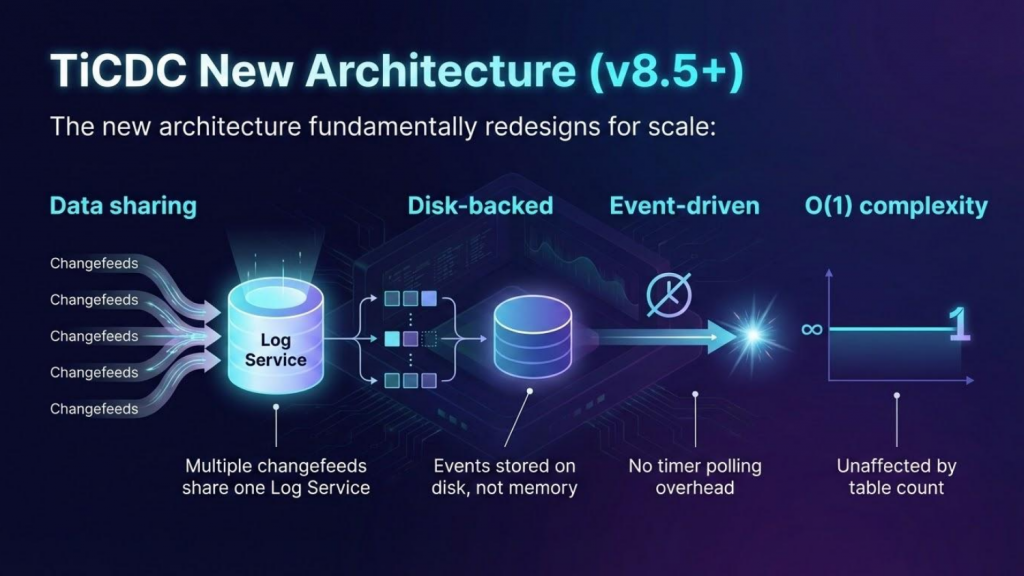
Figure 5: TiCDC new architecture (in TiDB 8.5+) with data sharing, disk-backed storage, and O(1) complexity.
Core Design Principles of the New TiCDC Architecture
The new TiCDC is built on three core architectural pillars:
Decentralization
There is no single point of failure. Services are distributed across the cluster, and the Coordinator only handles scheduling and metadata. It never touches data itself. This ensures that even if the Coordinator fails, ongoing replication continues uninterrupted.
Event-Driven Processing
The new architecture delivers high-performance processing without the overhead of timer-based polling. The previous architecture’s 50ms timer created a hard ceiling on DDL throughput. The new event-driven model achieves sub-millisecond latency for both DML and DDL changes.
Separation of Concerns
Clear boundaries between data collection, storage, and transformation allow for independent scaling. The Log Service can scale independently of the Downstream Adapter, and new sink types can be added without modifying the core collection logic.
How TiCDC Compares to Other CDC Solutions
Most widely adopted CDC tools—such as Debezium and Maxwell—were designed for single-writer databases. They consume a single binlog or WAL stream and forward events to Kafka or another message broker. This model works well for MySQL and PostgreSQL, but it fundamentally cannot support a distributed database where writes happen on many nodes simultaneously.
TiCDC differs in several important ways. First, it collects events from many TiKV nodes in parallel rather than tailing a single log. Second, it uses the Global TSO to merge those streams into a globally consistent order, something that single-source CDC tools do not need and cannot provide. Third, its disk-backed Log Service and multiplexed gRPC streams allow it to handle region counts and throughput levels that would overwhelm a Debezium connector. For teams already running TiDB, TiCDC is the native, purpose-built CDC solution; for teams evaluating distributed databases, its CDC architecture is an important differentiator to consider.
Summary: A Cloud-Native Future for Real-Time Data Replication
The journey of TiCDC shows that scaling CDC for a distributed database requires more than clever coding. It demands a fundamental shift in architecture. By moving to a distributed, disk-backed, and event-driven model, TiCDC now offers linear scalability, higher throughput, and true cloud-native readiness.
These improvements enable TiCDC to handle workloads that were previously impossible: Supporting hundreds of changefeeds on a single cluster, replicating tables with millions of partitions, and maintaining transaction integrity even during network partitions or node failures.
Further Reading
Want to dive deeper into TiCDC? Here are some additional resources to explore:
- TiCDC on GitHub: Source code, issues, and contribution guide.
- TiCDC Documentation: Setup, configuration, and operational guide.
- TiDB Architecture Overview: Understanding the distributed foundation TiCDC builds on.
- TiDB Community: Join the conversation, ask questions, and share feedback.
Experience modern data infrastructure firsthand.



TiDB Cloud Dedicated
A fully-managed cloud DBaaS for predictable workloads
TiDB Cloud Starter
A fully-managed cloud DBaaS for auto-scaling workloads