

In the areas of data management and real-time analytics, Change Data Capture (CDC) has become an indispensable tool. CDC is a software operation that enables you to monitor and record changes in your source database. From there, you can subsequently apply those changes to your target database. These changes could be new records, updates, or deletions of existing data. CDC ensures the target database stays synchronized, continuously moving and processing data as new changes occur in the source database.
In this blog post, we’ll explore the basics behind CDC. We’ll also present key benefits and patterns as well as provide a solution for getting started.
What is Change Data Capture and Why It Matters
CDC is a technique used in the field of databases and data integration. Unlike batch ETL processes, it’s designed to capture and track changes made to data in a database. It enables the identification and capture of individual changes (e.g., inserts, updates, and deletes, and even DDL changes) that occur within the source database. This allows systems to keep track of these modifications over time.
CDC is valuable in various scenarios, particularly in data replication, data warehousing, and real-time analytics, where it’s crucial to identify and propagate changes efficiently and accurately across different systems. Instead of scanning entire databases or tables for changes, CDC specifically targets and captures modified data or incremental changes in the source database, reducing the workload and processing overhead.
How Change Data Capture Works: From Database Logs to Real-Time Data Streaming
To visualize this process, imagine CDC processing alterations in a source database and then seamlessly applying these changes to the target database.
Here’s a simple example of how CDC works:
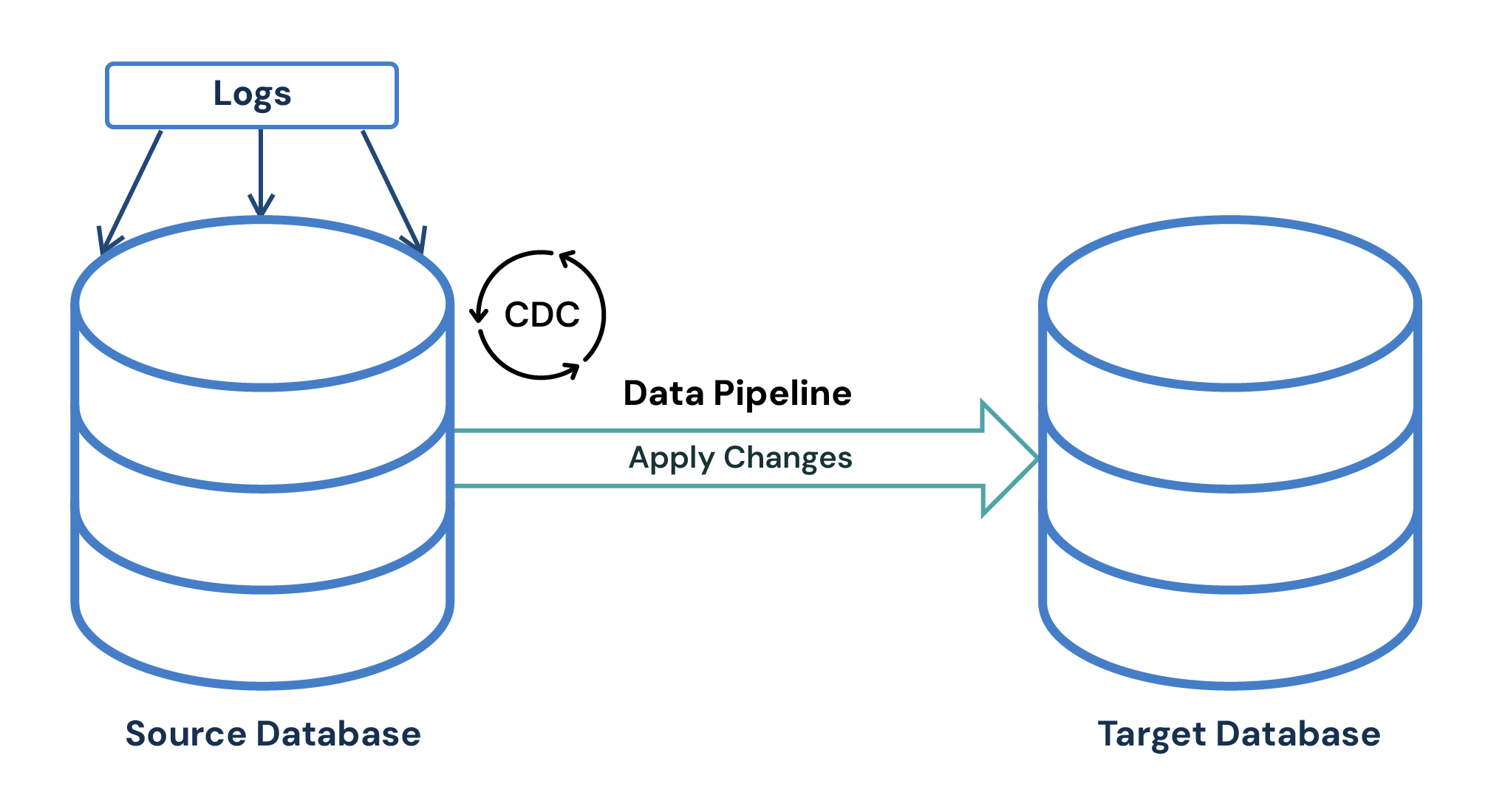
- A source database is updated with changes.
- The CDC process captures and parses the changes generated in the sequence they occur from database system logs.
- Then the CDC process applies the changes to the target database in order.
- The target database is now in sync with the source database. Note: These steps continuously repeat as long as the CDC replication is running.
Why Businesses Need CDC: Real-Time Data Pipelines and Cloud Database Synchronization
CDC is instrumental in maintaining data consistency across similar or different data platforms. It also facilitates data synchronization, enabling real-time analytics, supporting data warehousing initiatives, and ensuring that applications have access to the most up-to-date information. It does all this without the need for extensive manual intervention to keep data up to date on target data platforms.
There are several key benefits of using CDC:
- Real-time data updates: CDC captures and propagates changes as they occur to the target systems, enabling real-time access to updated data without delays. This is crucial for applications requiring real-time information.
- Offload reporting: Instead of performing resource-intensive queries directly on the source database, CDC captures changes and replicates them to a separate reporting or analytics database. This allows reporting tools and analytics processes to access the most recent data without impacting the performance or stability of the source database.
- Business continuity: CDC plays a crucial role in Disaster Recovery (DR) strategies by enabling organizations to quickly recover from data loss or system outages on the primary system. CDC facilitates data replication and synchronization between systems running across remote regions. This ensures a copy of the data remains available in the event of a disaster.
- Reduced workload: CDC reduces the workload on the source systems and optimizes network bandwidth during data transfers by capturing only the changes made to data after an initial data sync.
- Automated data synchronization: CDC facilitates seamless data synchronization between different systems or databases. This ensures all copies are updated with the latest changes without manual intervention.
Overall, Change Data Capture significantly enhances data management, facilitates efficient data integration across systems, and empowers organizations to work with current and accurate information. This contributes to better decision making and operational efficiency.
Change Data Capture Methods: Triggers vs. Log-Based Replication
There are typically two main approaches to implementing CDC:
Trigger-Based CDC (Pros & Cons)
This method involves the use of database triggers to capture changes made to source tables. Whenever an insert, update, or delete operation is performed on a specified source table, triggers are activated, and the associated changes are recorded in CDC tables or logs. Trigger-based CDC impacts database performance and causes extra overhead as it necessitates multiple write operations to the database for every inserted, updated, or deleted row.
Log-Based CDC for Scalable CDC Architecture
With this method, CDC leverages the transaction or redo logs generated by the database management system with negligible impact to performance. These logs contain a record of all changes made to the database. CDC tools or processes can read these logs, interpret the changes, and replicate them to other systems or store them for further analysis. Log-based CDC is usually the mainstream method for capturing changes in a source database.
Top CDC Use Cases: From Analytics to Kafka Integration
CDC has several use cases across various industries and applications. Here’s a list of some common ones:
- Real-Time Analytics & BI: CDC enables real-time data replication to analytics platforms or data warehouses, allowing organizations to perform analytics on the most up-to-date data without impacting the operational systems.
- Cloud Database Migration: Keep source and target in sync during cutover to TiDB or between clouds, minimizing downtime and risk.
- Event-Driven Microservices: Publish row changes as events so downstream services react immediately (notifications, fraud checks, inventory updates).
- Kafka Integration for Streaming Pipelines: Output to Apache Kafka for scalable fan-out to Flink/Spark/ksqlDB and other consumers.
- Hybrid Cloud & Data Lake Pipelines: Continuously land changes in S3/GCS/HDFS or lake formats to power ML features, archival, and cross-region analytics.
- Data Warehousing and Business Intelligence: It facilitates the extraction of transactional data from production databases to populate data warehouses, supporting reporting, analysis, and decision-making processes.
- Replication for High Availability: CDC helps in creating redundant copies of data in near real-time to ensure high availability and minimize downtime in case of system failures or disasters.
- Data Migration and System Upgrades: During system upgrades or migrations, CDC captures changes from the old system and replicates them to the new system, ensuring data consistency and minimizing downtime.
- Synchronization Across Distributed Systems: CDC synchronizes data across multiple geographically distributed systems or databases, ensuring that all systems remain consistent and up-to-date.
- Compliance and Auditing: CDC can track and capture all changes made to critical data, providing a detailed audit trail for compliance purposes, such as meeting regulatory requirements or internal policies.
These use cases demonstrate the versatility and importance of CDC in various scenarios where capturing, propagating, and applying changes in real-time or near real-time is critical for data management, analysis, and system operations.
TiDB for Change Data Capture: Distributed SQL Built for Data Replication
Many companies rely on CDC replication to synchronize their data. However, since most database providers do not offer CDC as part of their standard architecture, companies usually need to purchase and integrate third-party solutions.
At PingCAP, we’ve developed a CDC replication tool that is cost-effective and fully integrated with TiDB. Our advanced open-source distributed SQL database is purpose-built to offer an all-in-one solution for relational databases. It can cater to diverse scenarios demanding high availability, scalability, and robust consistency, especially when dealing with huge datasets. It’s a trusted database platform with over 3,000 global adopters.
TiCDC: TiDB’s Native Change Data Capture Solution
TiCDC (TiDB Change Data Capture) is a CDC solution specifically designed for TiDB.
TiCDC is a tool that captures and replicates real-time changes made to TiDB. It enables you to track and propagate various modifications, including Data Manipulation Language (DML) statements like inserts, updates, and deletes. It can do the same thing for Data Definition Language (DDL) statements such as create, drop, and alter. A source TiDB database captures these changes and then replicates them to one or more target databases.
What Is TiCDC?
TiCDC captures DML and DDL changes made in a source TiDB cluster. It then efficiently replicates them to target systems with low latency. These target systems include data warehouses, analytical databases, MySQL-compatible databases, Kafka clusters, or even other TiDB clusters.
How TiCDC Works with Kafka and Cloud Databases
Here’s an overview of how TiCDC operates:
- Change capture: TiCDC continuously monitors the TiDB cluster for changes. It does so by leveraging the TiDB redo log, which is a transactional log capturing changes made to the database.
- Change processing: After capturing changes, TiCDC processes them and organizes the data into a format suitable for replication. It ensures data consistency and maintains the exact order of changes.
- Replication: The target systems replicate the processed changes through various connectors. TiCDC supports various sink connectors, including TiDB, MySQL, and other MySQL compatible databases. These connectors allow flexibility in integrating with different data platforms.
- Data consistency: TiCDC ensures strong data consistency across different replicas and data sinks. It maintains the same data order and ensures correct sequencing of data changes. A network latency requirement between the source and target systems should be no more than 100ms to provide near real-time replication consistency. Note: TiCDC nodes can scale up to handle increased replication workload requirements.
- Fault tolerance: TiCDC’s design ensures high availability and fault-tolerance. It can recover from failures and continue replicating data without data loss. TiCDC provides second-level RPO and minute-level RTO.
- Replicating tables: TiCDC has the ability to filter specific databases, tables, DMLs, and DDLs.
- Cluster management: Using Open API, TiCDC can query task status, dynamically modify task configuration, and create or delete tasks.
In a TiDB self-managed cluster, TiCDC allows for the replication of changed data to various target systems, as shown in the below table:
| Source | Target | Replication Type |
| TiDB | TiDB | One-way / Bi-directional |
| TiDB | MySQL Compatible databases | One-way |
| TiDB | Kafka (Avro / JSON formats) | One-way |
| TiDB | AWS S3 object storage | One-way |
| TiDB | AWS Google Cloud Storage | One-way |
| TiDB | Azure Blob Storage | One-way |
| TiDB | NFS | One-way |
TiCDC Architecture for Real-Time Data Pipelines
You can see how TiCDC’s architecture works in the below diagram:

The TiDB Cluster as shown above is the source system. The data then flows from the source as follows:
- When data changes occur, the TiDB Cluster sends new change logs to the TiCDC cluster.
- The TiCDC cluster will then parse the changes from the logs.
- Finally, the configured target platform pushes and applies the parsed changes. These changes can include a TiDB Cluster, MySQL compatible database, Kafka, or a Storage object.
TiCDC Use Cases: Multi-Region Sync, Data Lakes, Streaming
TiCDC has multiple use cases in various scenarios:
- Disaster recovery: TiCDC is widely utilized by numerous customers to establish real-time replication. This replication occurs from their primary TiDB production cluster to a remote TiDB cluster or MySQL-compatible database. This configuration creates an active-passive setup, ensuring data consistency and providing a reliable disaster recovery solution. Additionally, it facilitates real-time reporting on the target database, effectively reducing the reporting overhead on the primary database.
- Real-time analytics reporting: TiCDC can feed real-time data into target analytical databases. This enables data analysts to perform real-time analytics on a continuously updated dataset.
- Data warehousing: TiCDC can keep a data warehouse up-to-date with the latest changes from the production database.
Finally, TiCDC can support multiple heterogeneous destinations such as Kakfa, which has become the default standard to power real-time analytics. Another advantage of TiCDC is that it can horizontally scale the platform based on the replication workload. This is a technical detail. However, it’s one unique aspect that makes this tool a top choice for distributed systems.
So how can we confirm if the source and target databases are in sync when using TiCDC replication? If the target is a TiDB cluster or MySQL instance, it’s recommended that we compare the data consistency using sync-diff-inspector, another TiDB tool used to compare stored data with the MySQL protocol.
Conclusion & Next Steps: Getting Started with CDC in TiDB
CDC is a powerful technique that plays a pivotal role in modern data management and analytics. TiCDC, designed specifically for TiDB, offers a robust solution for capturing and replicating changes in a distributed, highly-available database. Whether you’re working on real-time analytics, data warehousing, or data integration, TiCDC can help you keep your data synchronized and up-to-date. This will ensure you’re always working with the most current and accurate information.
Does TiCDC sound like something that could help you? For more details, please check out our official docs page to learn more and get started.
Experience modern data infrastructure firsthand.



TiDB Cloud Dedicated
A fully-managed cloud DBaaS for predictable workloads
TiDB Cloud Starter
A fully-managed cloud DBaaS for auto-scaling workloads