

Key Takeaways
- A single agent step reads state, retrieves memory, checks a fact, and writes a decision. Across six systems, that means six round trips and a stale read.
- A stale read in an app is a page refresh. In an agent, it is a wrong decision already taken.
- The properties agents demand (scale, cheap concurrency, online change, isolation, one engine, branching) are the marks of a well-built operational database.
- Consolidating ten systems into one distributed SQL engine removes the sync boundaries entirely.
Agentic AI did not create a new kind of database. It revealed which ones were already built for it.
Across 2026 so far, a wave of large software companies have cut tens of thousands of roles and explained the cuts in nearly identical language: Too many layers of leadership, too many coordination-heavy roles, a need to merge products and ship AI faster. The framing is usually cost. The substance is architecture.
The layoffs are a cost line. The reorgs are an architecture decision, and the architecture decision is the one worth studying. The same force flattening those org charts is collapsing the data stack behind every AI agent being built right now. That force has a name: Conway’s Law.
The argument of this post is simple. The properties a database for AI agents demands are not new, and the teams shipping agents fastest are consolidating ten data systems into one.
Conway’s Law, and the Reverse Gear
Mel Conway’s 1968 observation is that organizations ship systems that copy their own communication structure. Four product teams produce four codebases, four data models, and four auth systems. The org chart becomes the schema.
Agentic AI runs this backward. A single intelligent layer cannot sit on top of four data models that do not share schemas or a way to query each other. So you pick the consolidated architecture first, and the organization reshapes to match it. The reorg is the org catching up to a decision already made in the data layer. That is the structure underneath the entire 2026 restructuring wave: A move from siloed teams on separate data models to composable platforms on a shared data layer.
Why “Horizontal, Not Siloed” Is a Data-Layer Problem
Horizontal sounds like an org slogan until you look at the stack the siloed org produced. A typical production AI feature touches a primary transactional database, a pile of read replicas, a caching layer, a search cluster, an analytics warehouse, a vector database, a document store, and the ETL and CDC pipelines stitching them together.
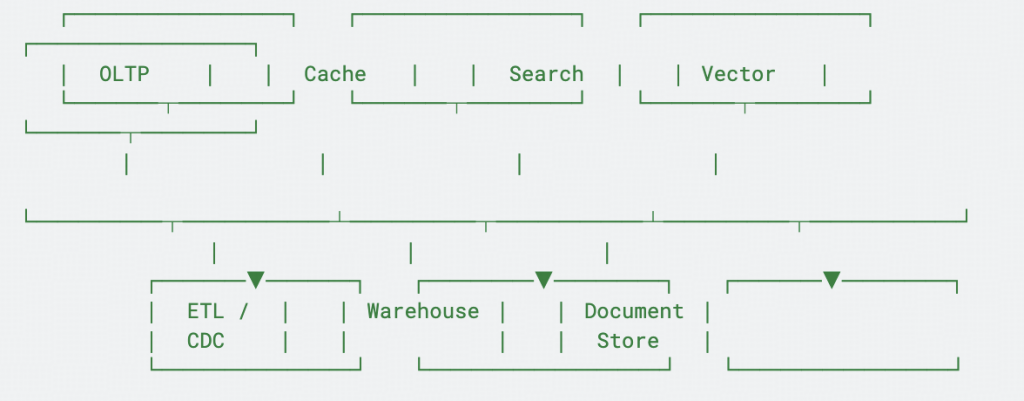
Look at the arrows, not the boxes. Every arrow is a sync job, a consistency boundary where one side is stale, and a coordination-heavy role whose entire purpose is reconciliation. That is the same synchronous bottleneck the reorg memos keep describing, one layer down in the stack.
The consolidation play is to compress those estates. The caching, transactional, and analytical estates, plus vector, search, and document, collapse into one engine that holds them on the same data under the same guarantees.
Why AI Agents Break the Siloed Stack
Agents take this from expensive to broken. A single agent step often reads its own state, retrieves relevant memory, pulls a fact from a knowledge base, checks an aggregate, and writes a decision back, all before it produces the next token. Spread across six systems, that is six round trips and at least one window where the agent reads memory that has not finished syncing and acts on it anyway.
In a human-facing app, a stale read is a page refresh. In an agent, a stale read is a wrong decision already taken, and a bug you cannot reproduce because the agent has moved three steps past it. Then multiply by thousands of agents, each demanding isolation so one agent’s writes never corrupt another’s state. Provisioning a tenant across six systems for thousands of concurrent agents is not a stack. It is a standing incident.
Database Consolidation for AI Agents: The Right Engine, Not a New One
Here is the part the hype cycle gets backward. Agentic AI did not invent a new category of database. It walked into a building that distributed SQL had already finished constructing.
The properties an agent platform demands are not novel. They are the properties a serious operational database has been judged on for a decade. TiDB earned them in high-volume transactional production systems, long before anyone was running a fleet of agents. The agentic workload simply turned each of those old strengths into a hard requirement.
Scale and Performance
Agent fleets generate enormous aggregate data and relentless write pressure. TiDB was built for petabyte scale in a single cluster, with horizontal write scaling, high throughput, and low latency. That was already a hard requirement for high-volume fintech and e-commerce years ago. It is now the floor for an always-on agent population that never sleeps and never stops writing.
Concurrency That Was Already Cheap
An agent fleet is, more than anything, a concurrency problem. Thousands of agents act at once, each opening sessions, firing queries, and writing state in parallel. TiDB’s SQL layer was built for that long before agents existed, because it is written in Go and leans on goroutines, Go’s lightweight concurrency primitive, rather than heavyweight operating-system threads. A thread-per-connection database pays a real cost for every concurrent client. Goroutines cost almost nothing to create, so a single TiDB node can fan out across very large numbers of concurrent sessions, and a single query can split into goroutines that hit many storage regions in parallel instead of scanning them one after another.
There is a clean rhyme here. Goroutines made cheap concurrency the default in Go by replacing a heavyweight unit, the thread, with a lightweight one. TiDB does the same thing one level up, replacing the heavyweight database instance with a lightweight branch or compute allocation, so you can run thousands where you used to run dozens. Cheap concurrency at the language level, cheap instances at the infrastructure level. Agentic AI rewards both, because it asks for everything at once.
Availability and Online Change
Agents evolve their own schemas constantly. An agent adding a column or an index at three in the morning cannot wait for a maintenance window, because there is no window in an agent’s world. TiDB’s 24/7 availability with online DDL and online upgrades was originally about never taking a payments system down. The same machinery is exactly what lets agents reshape their data continuously while the cluster stays up.
Many Objects, Large Tables, Schema per Agent
A single TiDB cluster supports a very large number of database objects and very large tables. That capability used to be about consolidating sprawling legacy estates into one place. With agentic AI, it becomes something sharper: Schema per agent task. Each agent, each app, and each branch gets its own isolated schema inside one cluster, so one agent’s heavy DDL or runaway query never touches its neighbors.
Multi-Tenancy and Resource Control
Thousands of agents sharing one platform is the noisy-neighbor problem at extreme fan-out. TiDB’s multi-tenant capabilities and resource control cap consumption per workload and meter cost per agent, tenant, or branch. Resource isolation was always how you ran mixed workloads safely on shared infrastructure. Now it is how you keep one expensive agent from blowing the budget for everyone else.
One Engine: Omni-Model and HTAP
This is the consolidation itself. TiDB is omni-model: Relational, vector, full-text, and document in the same SQL. Its HTAP (hybrid transactional/analytical processing) design carries the transactional and analytical estates in one system through TiFlash, which means an agent can read fresh analytics on the same data it just wrote, with no ETL and no second system to fall out of sync. HTAP was built so businesses could run real-time reporting without standing up a separate warehouse. For agents it means reasoning over live state instead of stale extracts.
Branching
TiDB supports instantaneous copy-on-write branching, a point-in-time fork of a database the way Git forks code. Branching matured as a safe way to test risky changes against real data. Agents use it to fork their own state, try an approach, and merge or discard the result without touching production, thousands of them at once.
TiDB X, and the End of Waiting for Data Movement
Underneath all of this is the architecture shift that turns a capable database into an agent-speed one.
TiDB always separated the stateless SQL compute layer from the TiKV storage layer, and the cluster was shared-nothing. That was a real strength, but the data lived on the local disks of the storage nodes, as Raft-replicated regions. Growth had a physical cost. Adding a node or relieving a hot region meant the placement driver had to rebalance, copying region replicas across the network before the cluster could carry load evenly. The compute layer was elastic, but the data underneath still had to move, and you waited for it to land.
TiDB X removes that wait by changing the storage substrate. Compute and storage stay decoupled, but the source of truth now lives in shared object storage. Compute attaches to that common backbone instead of owning a slice of the data. A new node, database, or branch does not need region replicas shipped to it first. It attaches to data already in object storage and starts serving. Rebalancing stops being a data-movement project, and spinning up ten thousand isolated databases becomes a lightweight compute allocation, ready in seconds.
That is the difference between elasticity you plan for and elasticity you can use in the middle of a spike. Agent traffic arrives without warning. A data layer that must relocate data before it can grow is always a step behind. One where compute attaches to storage in place keeps pace.
Read these properties again and notice what is missing. Nothing was bolted on for a demo. Every one predates agentic AI. Teams that built their database right for the operational world built it right for the agent world too. AI did not change the requirements. It stopped letting anyone fake them.
Database Consolidation for AI Agents: What This Looks Like in Production
Two examples make the pattern concrete.
Dify, a no-code GenAI platform, had grown into a sprawl of nearly half a million isolated database containers, one per developer dataset, holding relational data, embeddings, documents, and chat history across separate systems. Consolidating all of it into a single TiDB system, with vector search and document storage living next to operational data in the same SQL, cut their infrastructure cost by 80% and their operational overhead by 90%. The win was not a faster database. It was the disappearance of the sync boundaries between half a million of them.
Manus runs an agent platform where the agents themselves create the databases. Its model fans out from tenants to apps to clusters and branches, and its agents spin up tens of thousands of isolated TiDB clusters in parallel, each ready in seconds, each with its own evolving schema, each able to branch its own state to test a change. That is every property above working at once: Compute attaching to shared storage with no data movement to wait on, schema per agent, online DDL, cheap concurrency, HTAP and vector in one engine, and per-agent cost visibility through resource metering. The platform did not assemble a bespoke agent database. It ran on the operational one that already did these things.
The Honest Edge
Consolidation is not a magic word, and should not be pitched like one. Inside one engine, different capabilities sit on different consistency models, and the skill is choosing on purpose.
TiDB’s transactional path is strongly consistent, with Raft consensus, distributed ACID, and read-your-own-write the instant you write. Its search and vector indexing layer is eventually consistent, seconds behind writes, like a search engine’s refresh interval. For memory retrieval, seconds-fresh is fine. For an agent that must see the credit it just deducted, use the strongly consistent path. The value of one engine is that you choose the model per workload instead of reconciling a separate product per workload.
Now run it back up to the org chart. Once one team owns one data layer, the coordination roles that existed only to keep ten systems agreeing have nothing left to do. The sync jobs are gone because there is nothing to sync. The architecture flattened, so the org can flatten. That is Conway’s Law in reverse, one layer down in the stack. Consolidation is not a database decision. It is an org decision wearing a schema.
If you are building agents, count the databases in your architecture diagram. That number forecasts your future org chart: a coordination role for every sync boundary, a team for every silo, a negotiation for every arrow. The teams shipping AI fastest are driving that number toward one. And one is achievable not because someone shipped an AI database this year, but because the properties agents demand were already the marks of a database built right.
One database, not ten.
Stand up a consolidation layer on TiDB Cloud Starter in minutes, run vectors and transactions in the same query, and watch a sync job you used to maintain cease to exist. Get started today.
Experience modern data infrastructure firsthand.



TiDB Cloud Dedicated
A fully-managed cloud DBaaS for predictable workloads
TiDB Cloud Starter
A fully-managed cloud DBaaS for auto-scaling workloads