

At PingCAP, we strive to make TiDB your all-in-one AI database, capable of handling any workload seamlessly to fulfill the demand of the fast-evolving AI ecosystem. With vector search already available in TiDB, we are now excited to announce the native support for full-text search (beta) in TiDB Cloud Serverless(now called Starter) clusters.
Full-text search allows you to search for specific keywords in text data. In AI scenarios, by retrieving content via both vector search and full-text search (a.k.a. hybrid search), you can search for more relevant contents. This will yield better responses for your Retrieval-Augmented Generation (RAG) applications.
This blog will walk you through the details of how full-text search delivers improved search quality in RAG applications, and how you can use TiDB full-text search now.
Core Benefits
- Multi-lingual support: TiDB supports searching text in a variety of languages with high quality (using BM25 scoring) while not needing to specify what the language it is. The supported languages include English, Japanese, Chinese, Korean, and more. Additionally, you can store contents of different languages altogether in the same table. This is especially valuable for GenAI SaaS services as your customers may want to store content in arbitrary languages.
- One database for all: TiDB handles both structured and unstructured data all in one database. It also exposes extensive query interfaces via SQL, Python, or your favorite programming languages. Take GraphRAG apps as an example: TiDB can host everything including source documents, graphs, text chunks, embedding vectors. What’s more, TiDB SQL enables cross-query capabilities, like “find the knowledge graph path that is semantically closest to the given query and return its 2nd degree neighbor nodes and the corresponding text chunks”.
- Reduce operational overhead and costs: GenAI apps often have usage peaks and troughs according to online traffic and user demand. We know this — TiDB Cloud Serverless is fully managed and follows the pay-as-you-go pricing model, allowing you to only pay for what you use, thus reducing the cost when your users are sleeping.
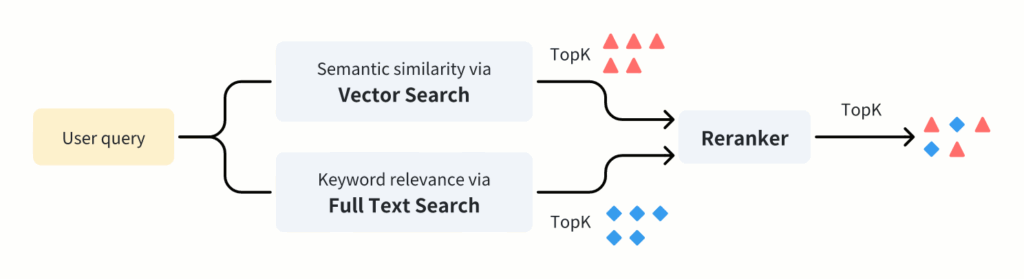
How Does Full Text Search + Vector Search Improve AI Responses?
To understand why a hybrid approach is beneficial, let’s first take a look at the differences between vector search and full-text search.
Vector Search
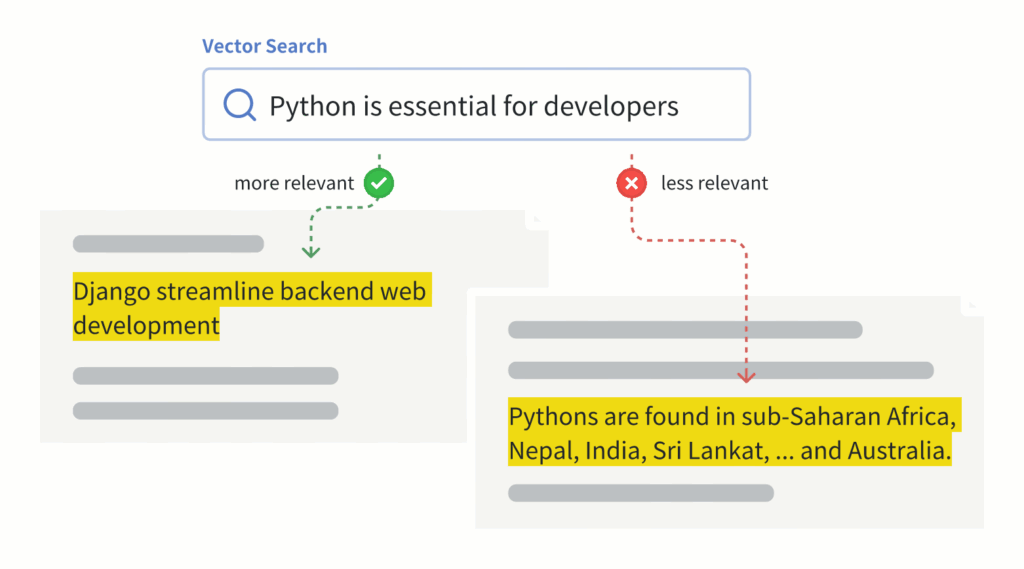
Vector search uses vector embeddings to represent the meaning of words and phrases. It captures semantic relationships and can find similar content based on context.
For example, “Python” represents a programming language, but it can also refer to a snake. When you run a vector search for a query like ‘Python is essential for developers,’ TiDB interprets ‘Python’ as the programming language—not the snake—and returns more relevant results, even if the word ‘Python’ doesn’t appear explicitly in the content.
Full-Text Search
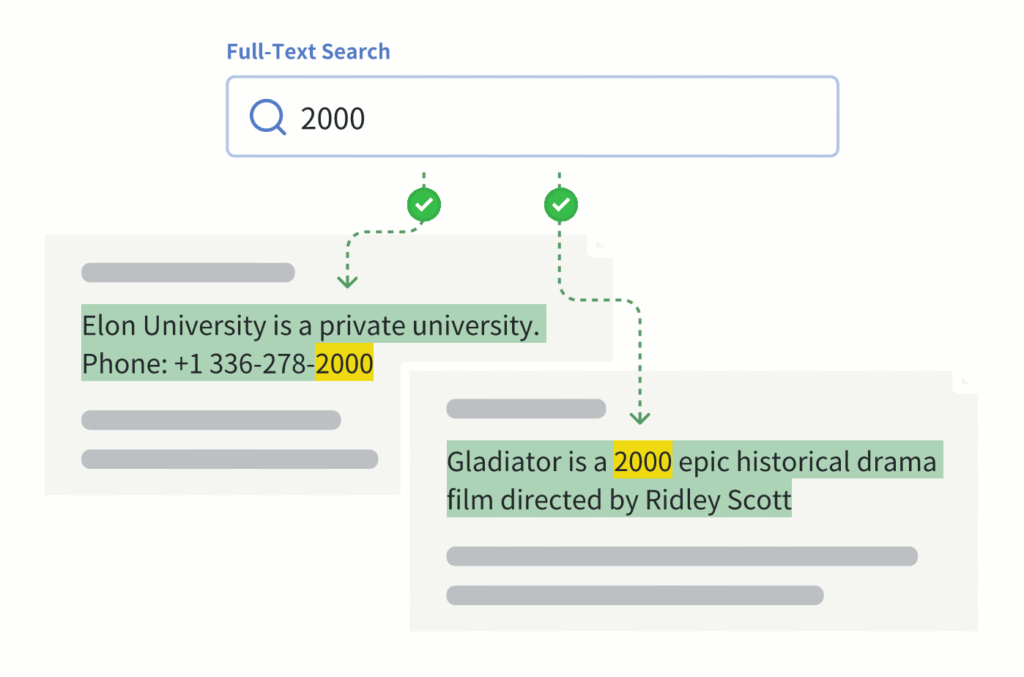
Full-text search relies on keyword matching. It looks for exact matches of each word in the text. It is especially useful for finding specific IDs (e.g., “deepseek-r1”), product names (e.g., “iPhone 15”), numbers, email addresses, or other precise information, where vector search will fail to return relevant results.
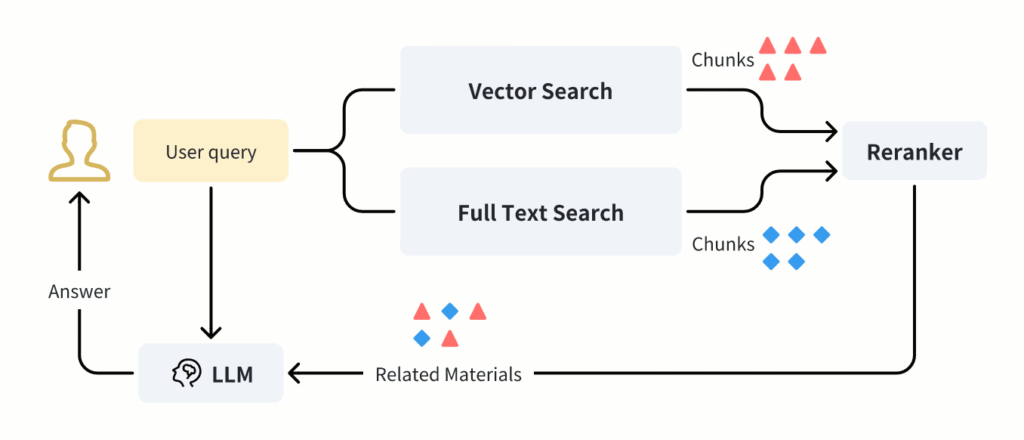
RAG works by retrieving relevant documents from a large corpus according to the user query. It then generates responses based on those documents using Large Language Models (LLMs). The retrieval process is crucial for the quality of the generated responses.
User queries vary in their nature. Some queries are more semantic, while others are more keyword-based. By combining vector search and full-text search (i.e., hybrid search), RAG applications can leverage the strengths of both methods to improve the retrieval process. This ensures the most relevant documents are found and used for response generation. As a result, it yields more accurate and contextually relevant responses.
Get Started Using Python
The following tutorial demonstrates how to use full-text search in TiDB Cloud Serverless clusters with the pytidb Python SDK. This SDK provides friendly APIs to use vector search, full-text search, and hybrid search, making it easy to build AI applications on TiDB.
Create a TiDB Cloud Serverless Cluster in eu-central-1 Region
Full-text search is available in TiDB Cloud Serverless clusters of limited regions. If you don’t have one, follow the steps below to create a TiDB Cloud Serverless cluster for free:
- If you do not have a TiDB Cloud account, click here to sign up for an account.
- Log in to your TiDB Cloud account.
- On the Clusters page, click Create Cluster.
- On the Create Cluster page, Starter or Serverless is selected by default. Select the AWS – Frankfurt (eu-central-1) region because currently full-text search is only available in limited regions.
- Click Create to create a TiDB Cloud Serverless cluster.
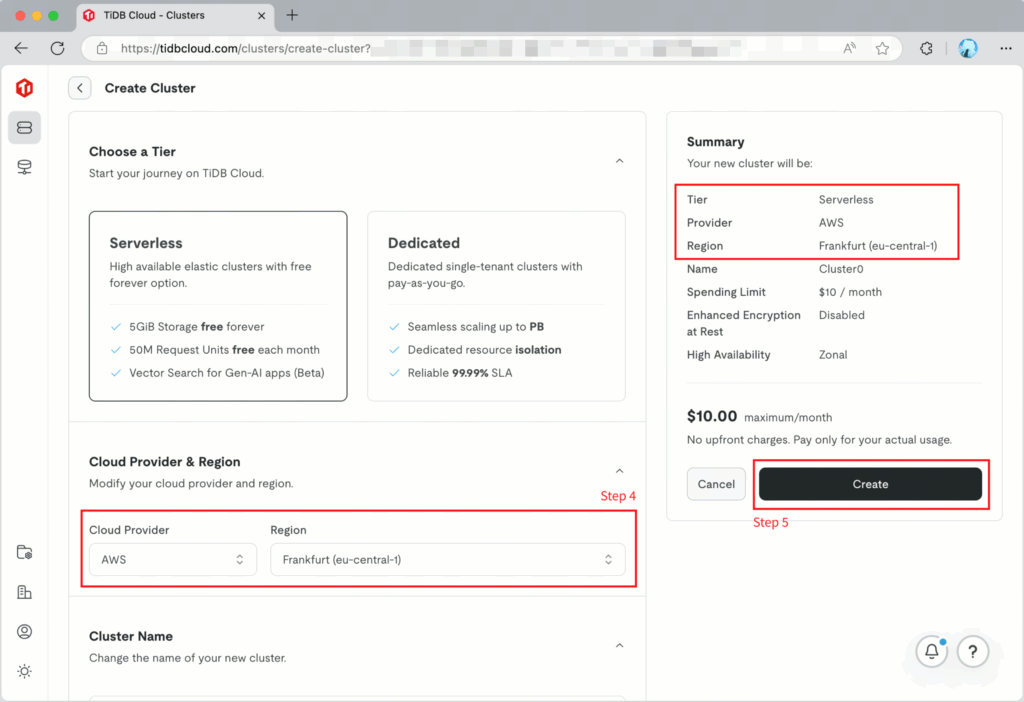
- Your TiDB Cloud Serverless cluster will be created in approximately 30 seconds.
Install pytidb SDK
pip install 'pytidb[models]'
# If you only need basic capabilities:
# pip install pytidbConnect to TiDB Cloud Serverless
from pytidb import TiDBClient
db = TiDBClient.connect(
host="gateway01.eu-central-1.prod.aws.tidbcloud.com",
port=4000,
username="xxxxxxxxxxxxx.root",
password="xxxxxxx",
database="test",
)The connection parameters to your cluster can be retrieved from the TiDB Cloud console:
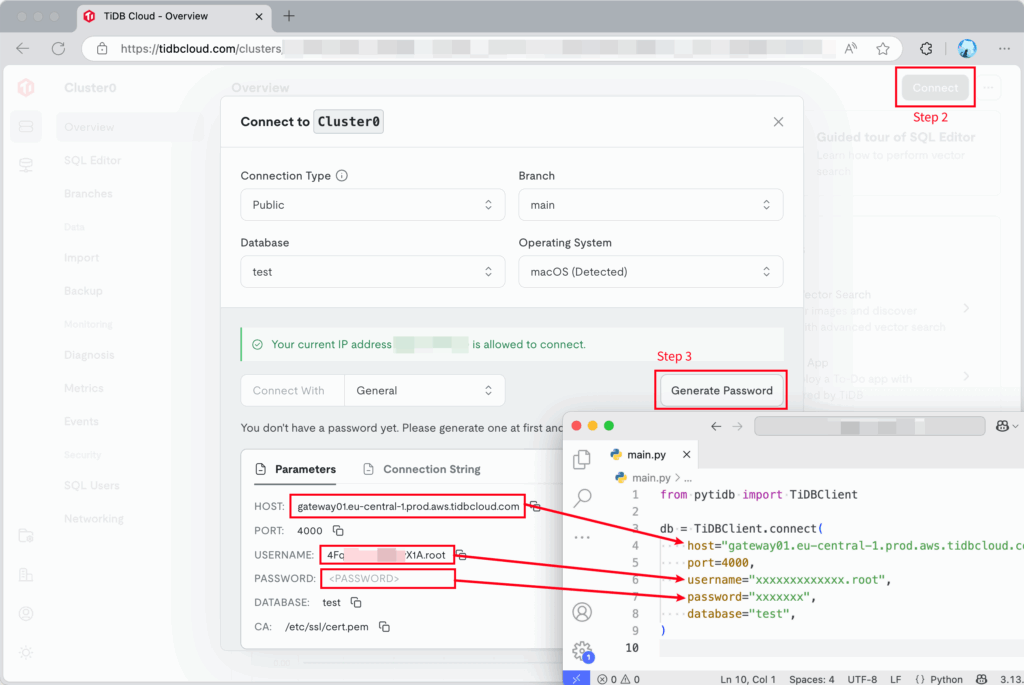
- Navigate to the Clusters page, and then click the name of your target cluster to go to its overview page.
- Click Connect in the upper-right corner. A connection dialog is displayed, with connection parameters listed.
- Click Generate Password to generate a new random password if this is your first time connecting to your cluster. The generated password will not show again. If you do not set a password, you cannot connect to the cluster.
- Fill the connection parameters into your code.
Create a table with full-text index and insert some sample data
To demonstrate TiDB’s hybrid-language search capabilities, we use several good names related to “bluetooth earphone” in multi-language (Japanese and English) as the sample data:
from pytidb.schema import TableModel, Field
from pytidb.datatype import Text
class StockItem(TableModel, table=True):
id: int = Field(primary_key=True)
title: str = Field(sa_type=Text)
table = db.create_table(schema=StockItem)
table.create_fts_index("title")
table.bulk_insert([
{"id": 1, "title": "イヤホン bluetooth ワイヤレスイヤホン "},
{"id": 2, "title": "完全ワイヤレスイヤホン/ウルトラノイズキャンセリング 2.0 "},
{"id": 3, "title": "ワイヤレス ヘッドホン Bluetooth 5.3 65時間再生 ヘッドホン 40mm HD "},
{"id": 4, "title": "楽器用 オンイヤーヘッドホン 密閉型【国内正規品】"},
{"id": 5, "title": "ワイヤレスイヤホン ハイブリッドANC搭载 40dBまでアクティブノイズキャンセル"},
{"id": 6, "title": "Lightweight Bluetooth Earbuds with 48 Hours Playtime"},
{"id": 7, "title": "True Wireless Noise Cancelling Earbuds - Compatible with Apple & Android, Built-in Microphone"},
{"id": 8, "title": "In-Ear Earbud Headphones with Mic, Black"},
{"id": 9, "title": "Wired Headphones, HD Bass Driven Audio, Lightweight Aluminum Wired in Ear Earbud Headphones"},
{"id": 10, "title": "LED Light Bar, Music Sync RGB Light Bar, USB Ambient Lamp"},
])Perform a full-text search
print(table.search("bluetoothイヤホン", search_type="fulltext").limit(3))The query results are ordered by relevance, with the most relevant documents first:
[
{"id": 1, "title": "イヤホン bluetooth ワイヤレスイヤホン "},
{"id": 6, "title": "Lightweight Bluetooth Earbuds with 48 Hours Playtime"},
{"id": 2, "title": "完全ワイヤレスイヤホン/ウルトラノイズキャンセリング 2.0 "},
]Please refer to the following TiDB documentation for the most up-to-date information:
And also pytidb documentation and examples.
What’s Next
TiDB’s full-text search feature is currently in beta, and we will continuously improve its performance and usability. For example:
- Better out-of-box search result for CJK languages
- Easier to use and more flexible APIs
- Better performance and scalability when used with multiple conditions
- Availability for TiDB self-managed clusters
We are excited to see what you build with TiDB’s full-text search and vector search capabilities. If you have any questions or feedback, please join our community on Discord. Your input helps us make TiDB better for everyone.
EBook
The Modern, Unified GenAI Data Stack: Your AI Data Foundation Blueprint



TiDB Cloud Dedicated
A fully-managed cloud DBaaS for predictable workloads
TiDB Cloud Starter
A fully-managed cloud DBaaS for auto-scaling workloads