TiDB vs YugabyteDB (2026) Comparison Guide for Platform Teams

Jump to a Section
Updated March 13, 2026 | Author: Brian Foster (Content Director) | Reviewed by: Ravish Patel (Solutions Engineer)
This guide is for database architects, platform/DevOps teams, and engineering leaders evaluating TiDB alongside YugabyteDB and trying to choose a pragmatic distributed SQL database for cloud-native, Kubernetes-first workloads. It focuses on what matters in production: Strong consistency, ACID transactions, horizontal scaling, HTAP analytics via TiFlash, and multi-region replication tradeoffs.
Verdict: Choose TiDB when you are MySQL-first and need a pragmatic distributed SQL database for scale-out writes and storage (without application-owned sharding), plus an HTAP database path via TiKV + TiFlash to run operational analytics on fresh OLTP data. Choose YugabyteDB when your ecosystem is PostgreSQL-first and you want a distributed SQL option that aligns closely to Postgres drivers/ORMs and your existing Postgres-centric workflows, and you are ready to validate distributed transactions and multi-region replication tradeoffs in a topology-faithful POC.
Key takeaways (TiDB vs YugabyteDB):
- Choose TiDB if MySQL compatibility is non-negotiable and you want to preserve existing application behavior and tooling with minimal rewrite risk.
- Choose TiDB if you need scale-out writes and storage while keeping ACID transactions and strong consistency expectations, and you want scaling to be primarily “add nodes,” not “add sharding logic.”
- Choose TiDB if you want an HTAP path using TiFlash to reduce ETL lag and avoid standing up a separate analytics system for every real-time insight use case.
- Choose YugabyteDB if your stack is PostgreSQL-first (drivers, ORMs, SQL patterns) and that compatibility surface area is the biggest migration constraint you are trying to protect.
- In both cases, run a POC that explicitly measures distributed transactions under contention, p95/p99 latency, hotspot behavior, and failure scenarios in your intended multi-region replication topology, because that is where the real tradeoffs show up.
At-a-Glance: TiDB vs YugabyteDB
| Criteria | TiDB | YugabyteDB |
|---|---|---|
| Primary use | Distributed SQL / NewSQL for scale-out OLTP with MySQL compatibility; optional HTAP database path with TiFlash | Distributed SQL database often evaluated for PostgreSQL compatibility and scale-out goals |
| SQL / protocol compatibility | MySQL compatibility focus; validate feature gaps and edge cases in a POC | PostgreSQL compatibility focus; validate dialect/feature gaps in a POC |
| Consistency & ACID transactions | Strong consistency and ACID transactions; distributed transactions are part of the model (test contention + tail latency) | Distributed transaction + consistency model should be validated with workload-specific testing |
| Scaling model | Horizontal scaling database with TiDB compute + TiKV storage separation; designed to scale without application-owned sharding | Horizontal scale-out model; compare how rebalancing and hot partitions behave under growth |
| HTAP / analytics | TiFlash columnar replicas enable HTAP analytics on fresh OLTP data (OLTP + OLAP on same data) | Many teams still use a separate OLAP system for scan-heavy analytics; evaluate mixed workload strategy |
| Multi-region replication | Multi-region replication patterns exist, but tradeoffs depend on strong consistency vs latency choices | Multi-region replication patterns exist; validate topology goals and latency/cost tradeoffs early |
| Kubernetes operations | Self-managed on Kubernetes (TiDB Operator) or managed via TiDB Cloud; compare operational overhead | Self-managed on Kubernetes (YugabyteDB Kubernetes Operator) and day-2 workflows (upgrades, backups, incident response) |
| Pricing approach | No invented numbers. Compare TCO drivers: nodes/vCPU, storage, backups retention, egress, regions, support | No invented numbers. Confirm licensing/pricing model and map it to your topology and workload shape |
What This Table Covers
The table addresses the criteria that matter most during vendor selection: SQL dialect, architecture, consistency, analytics, scaling, multi-region support, Kubernetes maturity, managed services, licensing, and sharding.
However, this table does not replace a topology-faithful POC on real schema and queries, and it won’t tell you how either system behaves under specific constraints, such as p95/p99 latency under contention, hotspot and rebalancing behavior at scale, failure-mode performance (node/AZ/region disruption), or the day-2 operational workflows your team relies on (online DDL, backups/restores, upgrades, and incident runbooks).
How to Interpret “Compatibility”
"MySQL compatibility" means TiDB speaks MySQL wire protocol, supports MySQL syntax, and works with MySQL drivers and ORMs. "PostgreSQL compatibility" means YugabyteDB’s YSQL API reuses the PostgreSQL query layer with support for PostgreSQL syntax, extensions, and drivers. Neither guarantees 100% feature parity—run your actual queries against a test cluster before committing.
TiDB vs YugabyteDB Overview
To set a baseline, here is a plain-English “category + best-fit” definition for each system so the rest of the comparison stays grounded in real usage, not labels.
TiDB in Brief
TiDB (PingCAP) is a distributed SQL database (NewSQL) designed for horizontal scaling with a MySQL-friendly application experience. It uses TiKV for distributed transactional storage and TiFlash columnar replicas for an HTAP database path when you need analytics on fresh OLTP data.
YugabyteDB in Brief
YugabyteDB is a distributed SQL database often evaluated for PostgreSQL compatibility and scale-out goals. In practice, teams validate compatibility surface area, distributed transaction behavior, and multi-region replication tradeoffs in a POC aligned to their target topology.
Jump to a Section
- At-a-Glance: TiDB vs YugabyteDB
- TiDB vs YugabyteDB Overview
- Key Differences - The 60-second takeaway
- Architecture: How TiDB and YugabyteDB Work
- SQL & App Compatibility
- Consistency, ACID Transactions, and Isolation Semantics
- Scaling & Performance
- HTAP & Analytics: OLTP + OLAP on the Same Data
- Multi-Region Replication & Resilience
- Kubernetes & Operations
- Ecosystem & Integrations
- Implementation & Migration
- Pricing & Cost Drivers
- Pros & Cons
- Who Should Choose Which?
- FAQs
- Next Steps
Key Differences: The 60-Second Takeaway
If you only read one section, make it this one. These bullets map directly to the criteria that usually determine whether a team can migrate safely and operate the system confidently at scale.
Biggest Decision Drivers for Platform Teams
- SQL dialect: TiDB speaks MySQL; YugabyteDB speaks PostgreSQL. Your existing stack is the strongest pull factor.
- HTAP analytics: TiDB includes TiFlash for real-time analytics on live data. YugabyteDB relies on external OLAP systems.
- Scaling model: TiDB separates compute and storage for independent scaling. YugabyteDB co-locates them, coupling scaling decisions.
- Multi-region writes: Latency characteristics differ based on each system’s timestamp mechanism. Validate with your write patterns.
- Kubernetes operations: TiDB Operator is purpose-built for K8s lifecycle management. YugabyteDB Kubernetes Operator streamlines the deployment and management of YugabyteDB clusters in Kubernetes environments.
- Sharding: TiDB defaults to range-based sharding; YugabyteDB defaults to hash-based. This affects range scan vs. point lookup performance.
Common Misconceptions
- "Drop-in replacement": Neither database is a zero-change drop-in for MySQL or PostgreSQL. Both require compatibility testing with your queries, stored procedures, and ORM configurations. TiDB covers a broad MySQL surface area but has documented differences in auto-increment ID allocation, certain collations, and some stored procedure features. YugabyteDB reuses the PostgreSQL engine but not every extension is fully supported.
- "Global writes without latency": Any strongly consistent distributed database incurs cross-region latency for writes that span regions. The laws of physics apply. Evaluate whether single-region primary writes with cross-region read replicas might suit your workload better than true multi-region write topologies.
- "Distributed = always faster": For small datasets on a single node, a well-tuned single-instance MySQL or PostgreSQL database outperforms any distributed system. Distributed SQL shines when data volume, availability needs, or write throughput exceed single-node capacity.
Architecture: How TiDB and YugabyteDB Work
Understanding the architectural differences helps predict how each system will behave under your specific workload. Both databases draw inspiration from Google Spanner, but they make different design trade-offs in how they separate compute from storage and handle distributed transactions.
TiDB Architecture
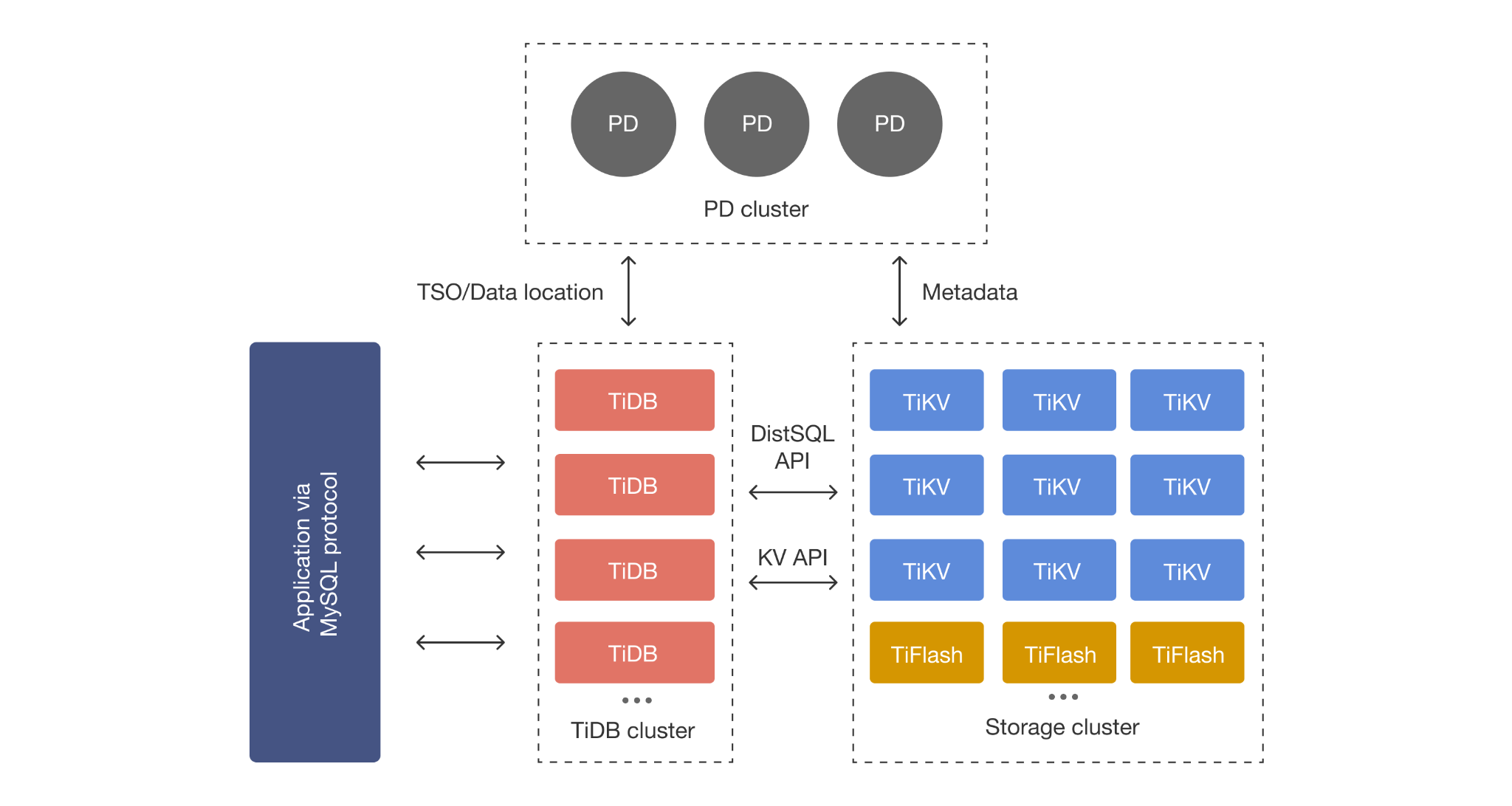
TiDB’s core components are designed to separate responsibilities:
- TiDB Server (SQL layer): Stateless nodes that parse SQL and generate distributed execution plans. Add or remove nodes without data migration.
- TiKV (row storage): Distributed transactional key-value store. Data is divided into ~256 MB Regions replicated via Raft. Default Snapshot Isolation.
- TiFlash (columnar storage): An optional columnar engine that maintains real-time replicas of selected tables. Data arrives from TiKV via Raft Learner without slowing transactional writes. The TiDB optimizer automatically chooses between TiKV (row) and TiFlash (columnar) based on cost estimates, and can even combine both in a single query for optimal performance.
- Placement Driver (PD): Cluster metadata brain—manages topology, timestamp allocation, and data scheduling.
Starting with TiDB 7.0, TiFlash also supports disaggregated storage and compute on S3-compatible object storage.
YugabyteDB Architecture
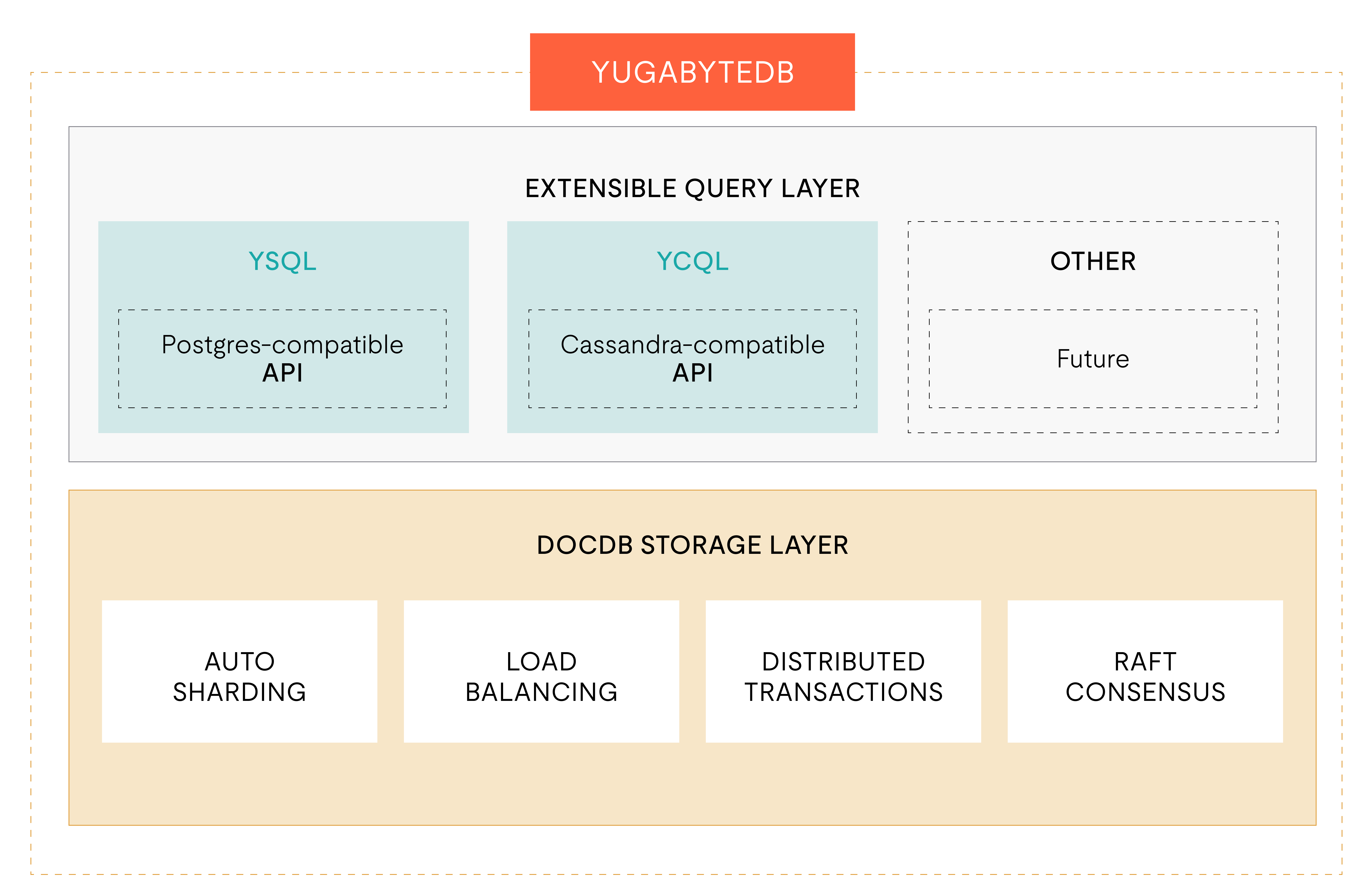
- Query Layer: YSQL reuses the PostgreSQL query engine; YCQL provides a Cassandra-compatible interface.
- DocDB (storage): Distributed document store on customized RocksDB. Data split into tablets replicated via Raft. Handles sharding, replication, and distributed ACID transactions.
- YB-Master: Manages metadata, tablet creation/splitting, schema changes, and load balancing.
Compute and storage are co-located on each YB-TServer, so the two layers cannot be scaled independently.
Distributed Transactions: What to Verify in a POC
TiDB uses a two-phase commit protocol (inspired by Percolator) with timestamps from PD. YugabyteDB uses a Spanner-inspired protocol with hybrid logical clocks. In a POC, test: Cross-shard transaction latency, conflict resolution under concurrent writes, transaction retry logic in your ORM/driver, and the throughput impact of different isolation levels.
Why Architecture Matters for OLTP Workloads vs OLAP Workloads
Both databases are optimized for OLTP. For OLAP, TiDB’s TiFlash runs analytical queries on columnar replicas without affecting transactional performance. YugabyteDB lacks a native columnar engine, so teams typically export data to a dedicated OLAP system like ClickHouse or a cloud data warehouse.
SQL & App Compatibility
Compatibility is where migration risk lives. This section makes “compatibility surface area” concrete: Drivers/ORMs, SQL dialect gaps, and the specific risk areas that can break applications in subtle ways, without making “100% compatible” claims.
TiDB: MySQL Compatibility
TiDB is highly compatible with the MySQL wire protocol and common MySQL 5.7 and 8.0 features. It supports most SQL syntax, functions, and data types. MySQL drivers and ORMs (Hibernate, Sequelize, SQLAlchemy, Django ORM, GORM) work with minimal or no changes. TiDB also supports online DDL for non-blocking schema changes.
What typically ports without changes: Standard CRUD operations, most JOIN types, subqueries, common aggregate functions, B-tree and composite indexes, and views.
What needs testing: Certain stored procedure behaviors, trigger semantics, specific character set and collation combinations, auto-increment ID allocation patterns (TiDB allocates IDs in batches for performance, so consecutive inserts may not produce strictly sequential IDs), and application code relying on MySQL-specific system variables or information\_schema nuances.
YugabyteDB: PostgreSQL Compatibility
YSQL reuses the PostgreSQL query layer, with the 2025.1 release rebasing the PostgreSQL fork from version 11.2 to 15.0. This upgrade brings support for stored generated columns, foreign keys on partitioned tables, and query execution optimizations like incremental sort and memoization.
What typically ports without changes: Standard SQL queries, PostgreSQL data types (JSONB, arrays, hstore), most popular extensions (PostGIS, pg\_trgm, pgcrypto), stored procedures, and PostgreSQL drivers and ORMs (psycopg2, node-postgres, ActiveRecord, Prisma).
What needs testing: Extensions that depend on local filesystem access, custom C extensions, very large schema migrations, full-text search configurations, and workloads relying on PostgreSQL-specific sequential scan behavior. Yugabyte reports that over 92% of PostgreSQL query patterns now run with comparable performance, but the remaining gaps may affect your specific workload.
Choosing Based on Your Current Stack
A practical decision usually starts with what you already run today. Use the guidance below as a quick filter, then prove it with a workload-aligned POC.
If You’re MySQL-First
TiDB offers the lowest migration friction. Connect using existing MySQL drivers, often without changing application code. Run your integration test suite against a TiDB cluster to surface any gaps. TiDB provides migration tools including TiDB Data Migration (DM) for ongoing replication from MySQL/MariaDB and TiDB Lightning for fast bulk data imports.
If You’re PostgreSQL-First
YugabyteDB provides the most familiar path. Use PostgreSQL drivers and ORMs directly. Yugabyte also provides YugabyteDB Voyager, a migration tool designed to facilitate schema, procedural code, and data migration from PostgreSQL, Oracle, and other databases to YugabyteDB. Test stored procedures, triggers, and extension usage against a YugabyteDB cluster to confirm compatibility.
Consistency, ACID Transactions, and Isolation Semantics
Strong consistency and ACID compliance are table stakes for distributed SQL databases. The practical differences lie in the specific isolation levels supported, how distributed transactions behave under contention, and what guarantees you can rely on during failure scenarios.
TiDB: ACID Transactions at Scale
TiDB provides full ACID support across distributed shards. Default isolation is Snapshot Isolation (Repeatable Read in MySQL terms). A two-phase commit with PD’s global timestamp oracle coordinates distributed transactions, providing strong consistency within a region and predictable OLTP behavior. For deeper background, see distributed transactions and ACID transactions in TiDB.
YugabyteDB: Transaction + Consistency Model to Validate
YugabyteDB supports Snapshot Isolation, Serializable, and Read Committed, with Read Committed the default for newer versions (v2025.2 and later). Its protocol uses hybrid logical clocks, which can operate across regions without a centralized timestamp oracle. In a POC, validate which isolation level your application requires and measure throughput impact.
Operational Impact: Latency, Contention, and Failure Scenarios
In both systems, distributed transactions add latency proportional to network round-trips between participating nodes. Cross-shard transactions are more expensive than single-shard transactions. Under write contention (multiple transactions competing for the same rows), TiDB uses pessimistic locking by default where conflicts are detected at commit time. YugabyteDB uses pessimistic locking in its default Snapshot Isolation mode. During node failures, both use Raft consensus for automatic leader election and continued service, but failover speed depends on Raft election timeout settings and cluster topology. Measure these behaviors under your specific failure injection scenarios.
Scaling & Performance (Horizontal Scaling Without Rewriting Everything)
The promise of distributed SQL is horizontal scaling: add nodes to handle more data and traffic without rewriting your application. Both TiDB and YugabyteDB deliver on this promise, but their scaling mechanics differ in important ways.
Scaling Model Comparison
TiDB’s compute-storage separation lets you scale each layer independently. Need more query throughput? Add TiDB server nodes. Need more storage capacity or write throughput? Add TiKV nodes. PD automatically rebalances data regions across the expanded cluster. This flexibility is particularly valuable for workloads where compute and storage demands grow at different rates.
YugabyteDB co-locates compute and storage on each YB-TServer node. When you add a node, you get both more compute and more storage. Tablet rebalancing happens automatically. This model is simpler to reason about but means you cannot independently scale compute without also scaling storage (and vice versa).
For a clear framing of scaling tradeoffs, see horizontal scaling database vs vertical scaling.
Performance Considerations for OLTP Workloads
Key factors: Sharding alignment with query patterns (range-sharded TiDB favors range scans; hash-sharded YugabyteDB distributes point lookups evenly), connection pooling, transaction size, contention levels, and index design.
Performance Considerations for OLAP Workloads
TiDB’s TiFlash gives it a structural advantage: Analytical queries run on columnar replicas without affecting transactional performance on TiKV. The TiDB optimizer automatically routes appropriate queries to TiFlash, and can combine row and columnar access in a single query. This is the core of TiDB’s HTAP value proposition. YugabyteDB does not include a built-in columnar engine. For heavy analytical workloads, the common pattern is to use CDC to stream data from YugabyteDB to a dedicated analytics system like ClickHouse, Snowflake, or BigQuery.
Benchmarking Checklist
Benchmarking is only useful if it reflects production.
- Versions: Use latest stable releases.
- Topology: Match node counts, instance types, and storage configs.
- Workload: Use your actual application queries, not just synthetic benchmarks.
- Sharding: Configure primary keys optimally for each system’s strategy.
- Warm-up: Allow steady state before measuring.
HTAP & Analytics: OLTP + OLAP on the Same Data
HTAP means running transactional and analytical workloads on the same database without ETL pipelines. This reduces complexity, eliminates data staleness, and lowers cost.
TiDB HTAP Approach: TiFlash for Analytical Replicas
TiDB’s HTAP architecture centers on TiFlash, a columnar storage engine that receives real-time data replication from TiKV. When you create TiFlash replicas for a table, TiDB automatically maintains a columnar copy updated as transactions commit. The replication uses the Raft consensus protocol—TiFlash replicas do not participate in leader elections and do not slow transactional writes. TiFlash provides the same Snapshot Isolation consistency as TiKV, ensuring analytical reads always see consistent, up-to-date data. The TiDB optimizer routes queries to the most efficient engine and can use both TiKV and TiFlash in a single query.
If you want a primer on why this can simplify architecture, see HTAP database for OLTP and OLAP workloads.
When TiFlash helps
TiFlash is most valuable when your team needs fresh analytics on operational data without building and maintaining a separate ETL pipeline. Common scenarios include:
- Real-time dashboards (revenue, inventory, user engagement) built directly on transactional data.
- Operational intelligence queries that join transactional tables with reference data for business decisions.
- Ad-hoc analytical queries from business analysts who need current data without waiting for batch loads.
- Mixed workloads where the same cluster serves the application and internal reporting.
When a Separate OLAP System Still Makes Sense
For petabyte-scale historical analysis, complex multi-source transformations, ML feature engineering, or long-running batch jobs, a dedicated system (Spark, Snowflake, BigQuery) remains appropriate. Many teams use TiDB with TiFlash for operational analytics plus CDC to a warehouse for deep historical analysis.
Multi-Region Replication & Resilience (Reality of Global Latency)
Multi-region deployments are increasingly important for global applications, disaster recovery, and compliance with data residency requirements. Both databases offer multi-region capabilities, but the trade-offs between consistency, latency, and operational complexity differ.
Supported Topology Patterns to Evaluate
- Single-region HA: Replicas across availability zones. Lowest latency, simplest operations.
- Multi-region reads: Primary writes in one region, read replicas elsewhere. Good for read-heavy global apps.
- Multi-region writes: Write to any region. Most complex, highest latency for consistent writes.
TiDB supports Placement Rules that allow fine-grained control over where data replicas are placed across regions. TiDB Cloud provides managed multi-region cluster deployments. YugabyteDB provides geo-partitioning for pinning data to specific regions, xCluster async replication between clusters, and synchronous replication across availability zones within a region. Both systems support read replicas for offloading read traffic to secondary regions.
Strong Consistency vs Latency: What “Multi-Region” Really Means
TiDB’s PD-based timestamps mean multi-region writes incur latency to the PD leader. YugabyteDB’s hybrid clocks reduce this dependency but still face Raft latency. Start with single-region HA and add multi-region only when business requirements demand it.
If you want a practical framework for strong consistency tradeoffs, see strong consistency and the CAP theorem (distributed systems).
Disaster Recovery Basics: RPO/RTO, Backups, and Failover Drills
Both databases support PITR, scheduled backups, and automated failover. TiDB integrates PITR into TiDB Cloud and provides BR tooling for self-managed deployments. YugabyteDB offers backup/restore via Anywhere and CLI utilities. Regardless of choice, regularly test DR procedures and document RPO/RTO targets.
Kubernetes & Operations
Day-2 operations—upgrades, backups, monitoring, incident response—are where distributed databases create the most operational load. Kubernetes-native tooling can significantly reduce this burden.
TiDB on Kubernetes: TiDB Operator + Automation Opportunities
TiDB Operator is a purpose-built Kubernetes Operator that automates the full lifecycle of TiDB clusters: Deployment, upgrades, scaling, backup, failover, and configuration changes. Originally developed by PingCAP and open-sourced in 2018, it uses Custom Resource Definitions (CRDs) to represent TiDB clusters as Kubernetes-native resources. Key capabilities include rolling upgrades with automatic rollback on failure, horizontal scaling of TiDB, TiKV, and TiFlash nodes via CR modifications, automated backup to S3-compatible storage, and native integration with Prometheus and Grafana for observability. TiDB Operator requires Kubernetes v1.24+ and uses Helm for deployment. It supports managing multiple TiDB clusters within a single Kubernetes cluster.
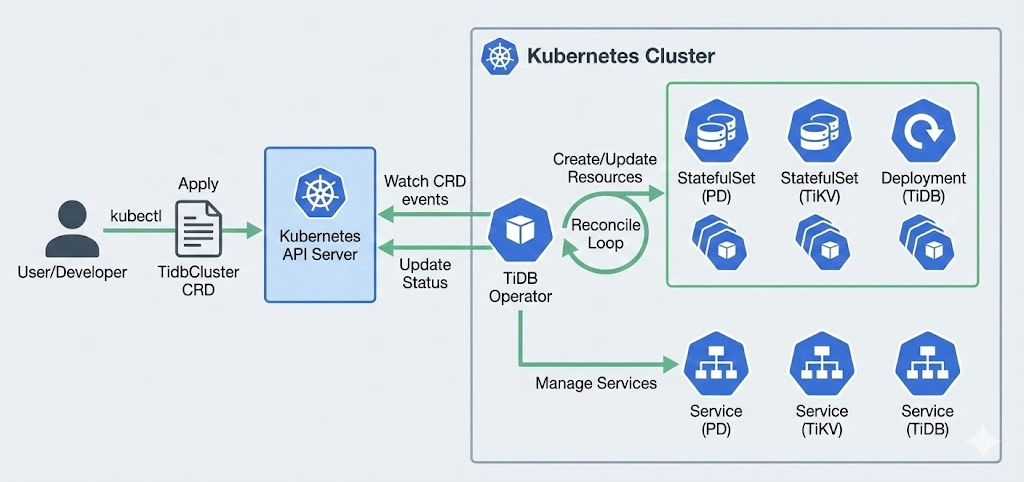
Managed Path: TiDB Cloud vs TiDB Self-Managed
TiDB Cloud managed distributed SQL database eliminates Kubernetes operational overhead entirely. PingCAP manages infrastructure provisioning, patching, upgrades, backups, and monitoring. TiDB Cloud Dedicated provides full control over node sizing and cluster configuration, while TiDB Cloud Starter offers auto-scaling, lower-touch options for smaller workloads. TiDB Cloud Essential is also a solid option for growing or production workloads that need performance, security, and scale—without the complexity of infrastructure management.
For teams that prefer full control, self-managed TiDB on Kubernetes or VMs via TiDB Operator is the recommended path. The choice depends on your team’s operational capacity, compliance requirements, and cost optimization strategy.
Operational Readiness Checklist
A production checklist should include:
- PITR and backups: Automated schedules, tested restores, documented RPO/RTO.
- Upgrades: Rolling upgrade process tested in staging.
- Monitoring: Dashboards for latency, throughput, storage, Raft health, replication lag.
- Incident playbooks: Procedures for node failures, partitions, storage full, performance degradation.
Ecosystem & Integrations (CDC, Streaming, BI, Tooling)
A database does not exist in isolation. Integration with your data pipeline, observability stack, and developer tools is critical for production readiness.
Data Movement & CDC
TiDB provides TiCDC (TiDB Change Data Capture) for streaming row-level changes to downstream systems including Apache Kafka, Apache Pulsar, MySQL, and other TiDB clusters. TiCDC supports ordering guarantees and at-least-once delivery. TiDB also offers TiDB Data Migration for ongoing replication from MySQL/MariaDB sources and TiDB Lightning for fast bulk import.
YugabyteDB supports CDC through its native change data capture feature, streaming changes to Kafka and other targets. YugabyteDB Voyager provides schema and data migration tooling from PostgreSQL, Oracle, and MySQL sources.
Observability and Reliability Tooling
TiDB integrates natively with Prometheus for metrics collection and Grafana for dashboards. TiDB Dashboard provides a built-in web UI for cluster diagnostics, slow query analysis, and key visualization. TiDB Cloud includes built-in monitoring and alerting. YugabyteDB provides Prometheus-compatible metrics endpoints, a web-based admin UI, and comprehensive monitoring through Anywhere and Aeon.
Developer Ecosystem: Drivers, ORMs, Connection Pooling
TiDB works with any MySQL-compatible driver and ORM. Officially tested integrations include JDBC (MySQL Connector/J), Go (go-sql-driver/mysql), Python (mysqlclient, PyMySQL), Node.js (mysql2), and ORMs like Hibernate, Django ORM, SQLAlchemy, Sequelize, and GORM. Connection pooling is supported by application-side pools used with MySQL connectors like JDBC or by proxies like ProxySQL.
YugabyteDB works with PostgreSQL-compatible drivers and ORMs. In addition to standard PostgreSQL drivers, Yugabyte offers topology-aware Smart Drivers that route connections to the nearest node for lower latency. Supported ORMs include ActiveRecord, Hibernate, Django ORM, Prisma, and Sequelize (via PostgreSQL dialect).
Implementation & Migration (How Teams Actually Switch)
Migrating to a distributed SQL database is a multi-phase project. Rushing the process is the most common source of production incidents. Plan carefully and validate thoroughly.
Migration Plan
- Assessment: Audit schema, queries, stored procedures, and dependencies. Identify compatibility gaps.
- Migration: Move schema, then data. TiDB: use Lightning for bulk import, DM for replication. YugabyteDB: use Voyager.
- Validation: Run full test suite. Compare results, latency, and error rates.
- Cutover: Switch production traffic with rollback plan ready.
Risk Reducers
- Dual writes: Write to both systems during validation to compare results.
- Canary deployment: Route a small percentage of production traffic first.
- Workload replay: Capture and replay production queries against the new database.
POC Success Criteria
Define success across three dimensions:
- Functional: Critical queries return correct results; stored procedures and schema migrations work.
- Performance: P50/P99 latencies meet SLA targets under peak load.
- Operations: Backup/restore, rolling upgrades, and failover meet RPO/RTO targets.
Pricing & Cost Drivers (What Changes Your Bill)
Pricing models evolve and depend on deployment choices. This section describes what typically drives cost rather than quoting specific prices that may be outdated by the time you read this.
TiDB: Self-Managed TCO vs TiDB Cloud Pricing Model
For self-managed TiDB, primary costs are infrastructure (compute, storage, network) and operational labor. TiDB is Apache 2.0 licensed with no software fees. TiDB Cloud pricing is not only node and storage based. It varies by tier: Starter is billed on RU consumption, and Essential is billed on provisioned RCUs (capacity in RU/s), in addition to drivers like node types/sizes (TiDB, TiKV, TiFlash), storage consumed, backup retention, network egress, and support tier.
TiDB Cloud Starter offers a free tier for getting started. Cost drivers that frequently surprise teams include TiFlash capacity for HTAP (additional compute and storage), cross-region network egress for multi-region deployments, backup storage retention beyond default periods, and provisioning enough RU or RCUs to cover peak concurrency and write bursts.
For the managed option, start with TiDB Cloud managed distributed SQL database.
YugabyteDB: Pricing Model to Confirm
YugabyteDB core is Apache 2.0 licensed. YugabyteDB Anywhere (management platform) is under a Polyform Free Trial license. YugabyteDB Aeon pricing is based on cluster size, instance types, storage, and cloud provider. Confirm current pricing directly with Yugabyte, as published pricing may differ from negotiated enterprise agreements. Cost drivers to watch: Multi-region replication configurations, read replica deployments, and support tier escalation.
Cost Checklist for Fair Comparison
When comparing TCO between TiDB and YugabyteDB, ensure your analysis accounts for both node-based and RU/RCU-based pricing, depending on deployment tier. Include:
- Compute costs (number and size of nodes across all layers, where applicable).
- RU consumption (TiDB Cloud Starter) and provisioned RCUs in RU/s (TiDB Cloud Essential).
- Storage costs (including replication overhead).
- Network egress (especially cross-region).
- Backup and DR storage.
- Managed service fees vs. internal operational labor.
- Support tier costs.
Both vendors offer pricing calculators. Use them with realistic workload estimates, including peak concurrency and burst profiles, so RU/RCU capacity and consumption assumptions are not understated.
Pros & Cons (Clear Tradeoffs, No Hype)
To keep the comparison selection-oriented and trustworthy, this section summarizes the best-fit scenarios and what to watch for, without making untestable claims.
TiDB Pros
- MySQL compatibility minimizes migration risk for MySQL-based applications.
- HTAP with TiFlash provides built-in real-time analytics without a separate OLAP pipeline.
- Compute-storage separation enables independent scaling of SQL processing and storage.
- TiDB Operator delivers mature, Kubernetes-native lifecycle management.
- CNCF-graduated TiKV signals strong open-source governance.
- TiDB Cloud on AWS, GCP, Microsoft Azure, and Alibaba Cloud reduces operational burden.
- Proven at scale: Adopted by 3,000+ companies globally.
TiDB Cons / Tradeoffs
- Not PostgreSQL-compatible: Teams committed to PostgreSQL face a dialect mismatch.
- Multi-region write latency: Centralized PD means writes incur latency to the PD leader’s region.
- Component complexity: TiDB, TiKV, PD, and TiFlash are more components than a monolithic database.
YugabyteDB Pros
- PostgreSQL compatibility via reused query layer provides a familiar experience.
- Multiple isolation levels: Snapshot, Serializable, and Read Committed.
- Geo-distribution: Native geo-partitioning and xCluster replication.
- Multi-API: YSQL, YCQL, plus emerging MongoDB API support.
YugabyteDB Cons / Tradeoffs
- No built-in HTAP: Analytical workloads require an external OLAP system.
- Coupled compute/storage: Cannot scale independently.
- Licensing nuance: Anywhere uses a different license than the Apache 2.0 core.
- Hash sharding default: Range scans may underperform without explicit range sharding configuration.
Who Should Choose Which? (Decision Matrix)
Use this matrix as a fast decision filter, then confirm the decision with a workload-aligned POC that includes performance, failure drills, and operational workflows.
| Scenario | TiDB | YugabyteDB |
|---|---|---|
| MySQL-based apps | Lowest migration friction | Requires query rewrite to PostgreSQL |
| HTAP (analytics on live data) | Built-in via TiFlash | Requires external OLAP |
| PostgreSQL-based apps | Requires query adaptation | Native compatibility via YSQL |
| Serializable isolation | Snapshot Isolation default | Natively supported |
| Independent compute scaling | Supported natively | Compute/storage scale together |
| Geo-partitioning | Via Placement Rules | Native support |
| Kubernetes-first ops | TiDB Operator (purpose-built) | YugabyteDB Kubernetes Operator |
If You’re Optimizing for MySQL Compatibility + Scale
TiDB is the natural choice. It provides MySQL protocol compatibility, the TiDB Operator for Kubernetes-native operations, TiFlash for real-time analytics without a separate OLAP pipeline, and a managed cloud option on AWS, GCP, Azure, and Alibaba Cloud. Migration from MySQL is well-documented with dedicated tooling including DM and Lightning.
If You’re Optimizing for PostgreSQL Compatibility + Multi-Region Needs
YugabyteDB is the natural choice. It provides deep PostgreSQL compatibility via the YSQL API, native geo-partitioning for data residency requirements, serializable isolation for workloads that need it, and Smart Drivers for topology-aware connection routing. Migration from PostgreSQL is supported by YugabyteDB Voyager.
Bottom Line
Both TiDB and YugabyteDB are mature, production-ready distributed SQL databases. Choose TiDB if your stack is MySQL-based and you need HTAP analytics with independent compute and storage scaling. Choose YugabyteDB if your stack is PostgreSQL-based and you need flexible multi-region isolation options. In either case, run a proof-of-concept with your actual workload before committing.
FAQs
TiDB is MySQL-compatible at the protocol level and supports common MySQL syntax, but it is not guaranteed to match every MySQL feature or edge case. The safest approach is a POC on your top queries, schema features, and operational workflows.
Next Steps: Validate with a Hands-On Demo / POC
The best way to evaluate TiDB is to test it with your own data and workload:
- Try TiDB Cloud: Free Starter cluster—deploy in minutes.
- Self-managed on Kubernetes: Follow the TiDB Operator quick-start guide.
- Explore HTAP: Learn how TiFlash enables real-time analytics.
- Distributed transactions: Deep-dive into ACID at scale.
- Distributed SQL explained: Why distributed SQL is the foundation for modern apps.
Ready to dive deeper? Talk with a TiDB expert to walk through your architecture and workload requirements.