

As digital services become more intelligent, personalized, and data-intensive, the infrastructure supporting them must evolve as well. Today’s applications aren’t just storing data, they’re making real-time decisions on it, often across globally distributed environments with high user concurrency and strict uptime requirements.
Amazon Aurora, a fully managed relational database from AWS, is a common choice for organizations looking to move fast in the cloud. It offers MySQL and PostgreSQL compatibility, a pay-as-you-go pricing model, and integration with other AWS services. But as workloads grow larger and more complex, Aurora’s architectural limitations begin to surface.
This blog explores five areas where Amazon Aurora falls short and why it’s often not the right fit for organizations operating at significant scale and complexity.
Amazon Aurora’s Initial Strengths
There’s a reason Amazon Aurora has seen wide adoption. Its benefits are real:
- MySQL and PostgreSQL compatibility allow for smoother migration from legacy systems.
- Fully managed infrastructure simplifies maintenance, patching, and backups.
- Storage scalability up to 128TB eliminates the need for manual provisioning.
- High read throughput via up to 15 read replicas supports read-heavy use cases.
For many teams, these advantages check the right boxes. But they come with caveats, and once you step into larger, more demanding workloads, Amazon Aurora’s architecture becomes a constraint rather than a strength.
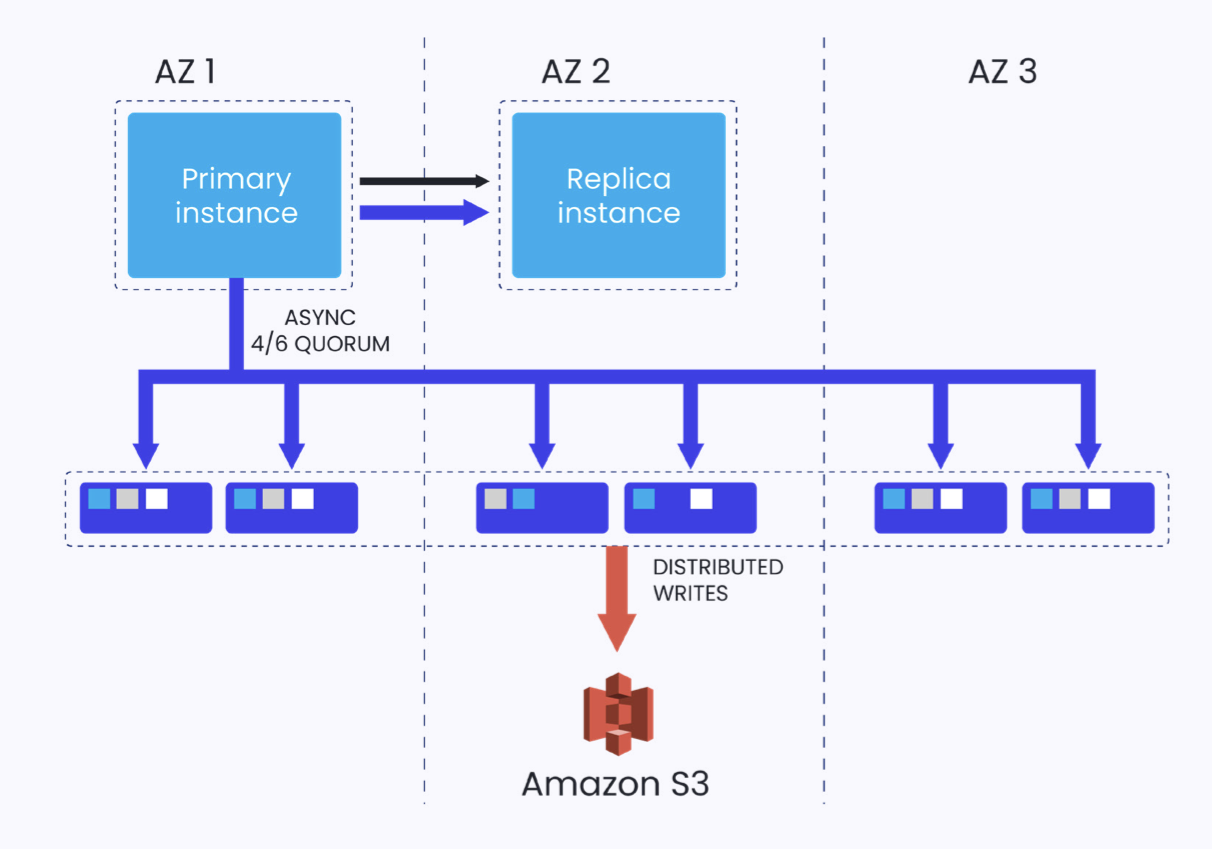
Figure 1: Amazon Aurora’s architecture
The Single-Writer Bottleneck
Amazon Aurora’s biggest limitation? Its single-writer model.
Only one instance in the Amazon Aurora cluster can handle write operations. All other replicas are read-only. This architecture introduces serious drawbacks:
- Throughput caps: Aurora hits a ceiling at around 20,000 QPS for write operations, well short of the requirements for high-ingest applications.
- Failover delays: If the primary node fails, promoting a replica can take over 120 seconds, during which write operations are blocked.
- Forced application complexity: Developers must implement read-write separation at the application layer, increasing operational overhead and room for error.
For applications like real-time payments, gaming platforms, or operational analytics, these bottlenecks are unacceptable.
Compute Doesn’t Scale with Storage
Amazon Aurora’s architecture separates storage and compute but in practice, only storage scales efficiently.
Its distributed storage backend automatically grows in 10GB increments and spans multiple Availability Zones (AZs). That’s great for durability and availability. But compute remains constrained:
- Write scalability is limited to a single primary instance.
- Read replicas share the storage layer but can’t process writes.
- There’s no native support for parallel transactional + analytical processing, forcing workarounds like ETL to external data warehouses.
The result? A system that works for read-heavy applications but struggles as data complexity or concurrency grows.
Limited Support for Real-time, Complex Workloads
While Amazon Aurora handles traditional OLTP (online transaction processing) scenarios well, it struggles with hybrid or mixed workloads. Amazon Aurora lacks native support for complex transactional and analytical processing. As a result:
- Analytical workloads must be offloaded to external systems.
- This introduces data movement delays and increases architectural complexity.
- Applications cannot run real-time analytics on live transactional data within Amazon Aurora.
This forces a trade-off between system simplicity and real-time insights, one many growing businesses can’t afford to make.
The Hidden Costs of Workarounds
To get around Amazon Aurora’s limitations, teams often patch together solutions, such as:
- Using ETL pipelines to sync with external analytical systems.
- Implementing manual read-write routing logic in application code.
- Overprovisioning compute instances to handle occasional spikes in load.
- Managing replica lag, especially under write-heavy workloads.
Each workaround adds cost, complexity, and risk. You spend more time managing architecture and less time shipping features. And when failure does occur, recovery time is still measured in minutes, not milliseconds.
Amazon Aurora in Multi-Tenant Environments: A Square Peg in a Round Hole
Amazon Aurora offers limited support for multi-tenant architectures. It lacks:
- Placement control: There’s no way to dictate where tenant data lives, which is crucial for data residency or latency-sensitive deployments.
- Resource isolation: Aurora doesn’t let you assign CPU/memory quotas per tenant. Noisy neighbors can degrade performance for others.
- Workload fairness: You can’t enforce tenant-level SLAs at the database level, pushing complexity up to the app or orchestration layer.
These gaps make Amazon Aurora a poor fit for SaaS companies and platforms serving multiple clients from the same backend. As you scale tenants, you scale headaches.
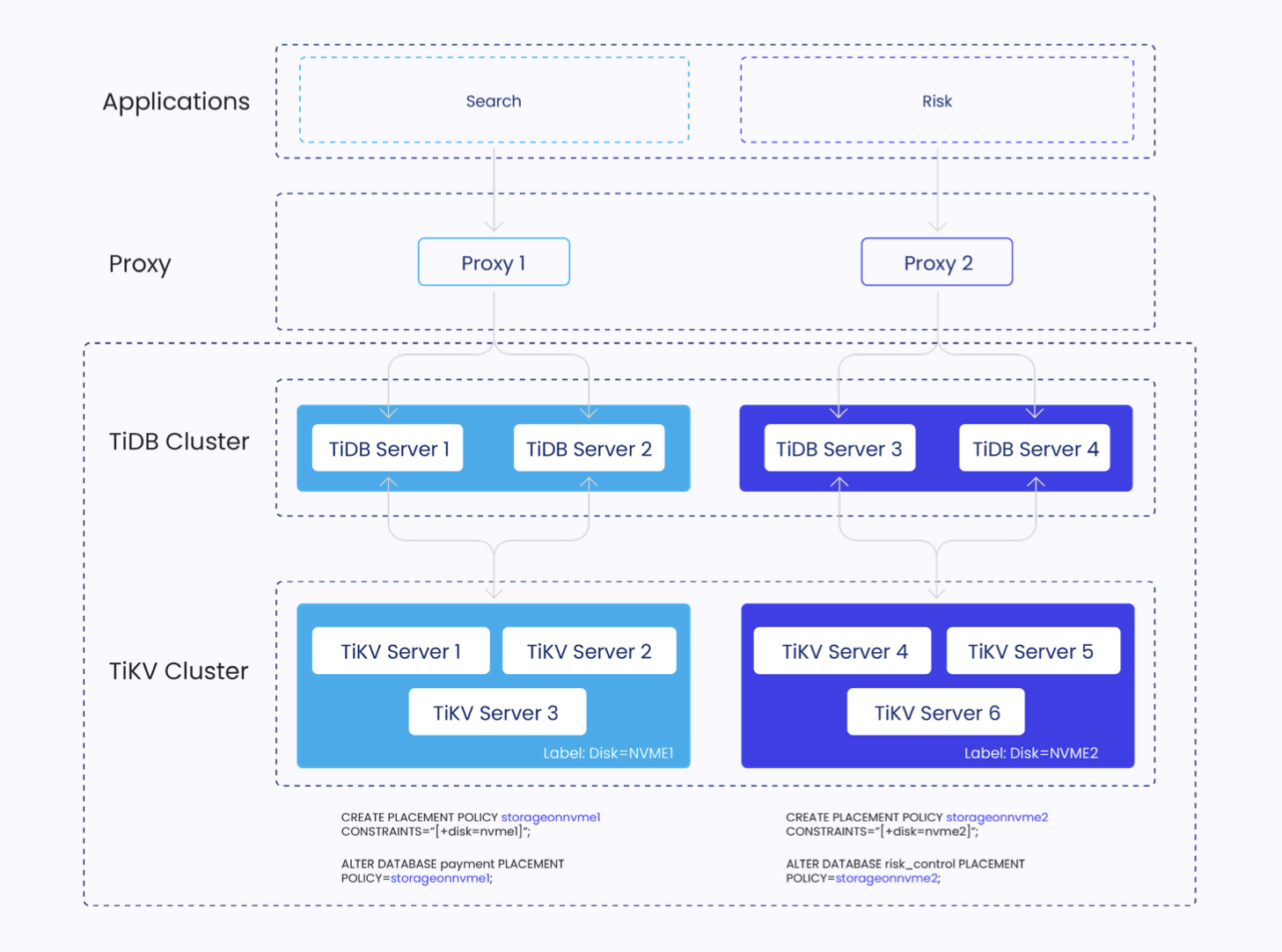
Figure 2: TiDB deployment in Multi-Tenant Environments
What to Look for in a Modern Database?
Modern applications require more than just managed infrastructure and decent read performance. They need:
- Multi-writer support, to eliminate bottlenecks.
- Horizontal scalability across reads, writes, and analytics.
- Real-time transactional and analytical processing.
- Granular control over resources and data placement.
- Fast recovery and built-in fault tolerance.
Amazon Aurora delivers on some but not all of these needs. And in the areas where it falls short, the consequences are felt quickly as businesses scale.
TiDB as an Amazon Aurora Alternative
If you’ve hit the ceiling with Amazon Aurora or are planning for a future that goes beyond 20,000 QPS, it may be time to explore alternatives.
TiDB, an open-source, MySQL-compatible distributed SQL database, is built for the kinds of workloads that bring Amazon Aurora to its knees:
- 300,000+ QPS write throughput in internal benchmarks
- Multi-writer, multi-reader architecture
- Built-in HTAP capabilities with TiFlash for real-time analytics
- Fine-grained multi-tenancy controls, including Placement Rules and Resource Control
- Faster recovery (30s RTO) and automatic failover without disruption
TiDB doesn’t just scale data. It scales intelligence, resilience, and operational flexibility.
Amazon Aurora Works, Until it Doesn’t
Amazon Aurora is a strong choice for small-to-medium, read-heavy workloads inside the AWS ecosystem. But for high-scale, write-intensive, or real-time applications, its architectural limitations become unavoidable. Performance ceilings, failover risks, and workarounds start to pile up just when you need your infrastructure to be most reliable.
If you’re evaluating long-term scalability and want a data layer that can keep up with growing complexity, it may be time to explore alternatives like TiDB, purpose- built for scale, resilience, and real-time analytics. Businesses are increasingly reliant on robust and scalable database solutions to manage their growing data needs.
Download our comparison white paper for a more in-depth view of critical features, capabilities, and architecture.
Spin up a database with 25 GiB free resources.



TiDB Cloud Dedicated
A fully-managed cloud DBaaS for predictable workloads
TiDB Cloud Starter
A fully-managed cloud DBaaS for auto-scaling workloads