

Geo-redundancy is a disaster recovery practice that backs up data in geographically distributed data centers. This approach safeguards against incidents and guarantees business continuity. For database systems, there are mainly two ways to be geo-redundant: cold (offline) backup and hot (online) backup. Cold backup is more widely used because it’s cheaper and has less impact on online performance.
However, it’s not easy to build a cost-effective, scalable cold backup solution. There can be challenges in scalability, operations, and costs. In this article, I will offer a solution to these challenges: geo-redundancy backup with cloud storage service.
Challenges of geo-redundancy cold backup
First, let’s look at the limitations of the most commonly used cold backup solutions.
Database built-in backup capabilities
Databases are usually shipped with cold backup capabilities. They either provide tools to dump data into your local storage or to upload data to remote storage services. For databases, geo-redundancy backup is not much different from single destination backup. You simply add more remote storage destinations.

Traditional cold backup with databases
However, dumping data during backup can use a lot of bandwidth. More the destinations you specify, the more bandwidth you consume. This may significantly impact database performance. In the worst case, dumping data may exhaust most of the bandwidth, and the database stops to respond to queries. Therefore, geo-redundancy using built-in database features is probably not a scalable solution.
Database geo-redundancy + a message queue
Using a message queue (MQ) can solve this bandwidth issue. MQ is a mechanism for asynchronous interprocess communication and is widely accepted as a solution for saving bandwidth—especially when your network is constrained by concurrent data . You can put an MQ service between the database instance and the remote storage.
MQ lets you distribute data to multiple destinations to achieve geo-redundancy backup at scale. The impact on database performance will be the same as a single-destination backup. If the MQ reaches its performance bottleneck, you can add more instances to the chain.
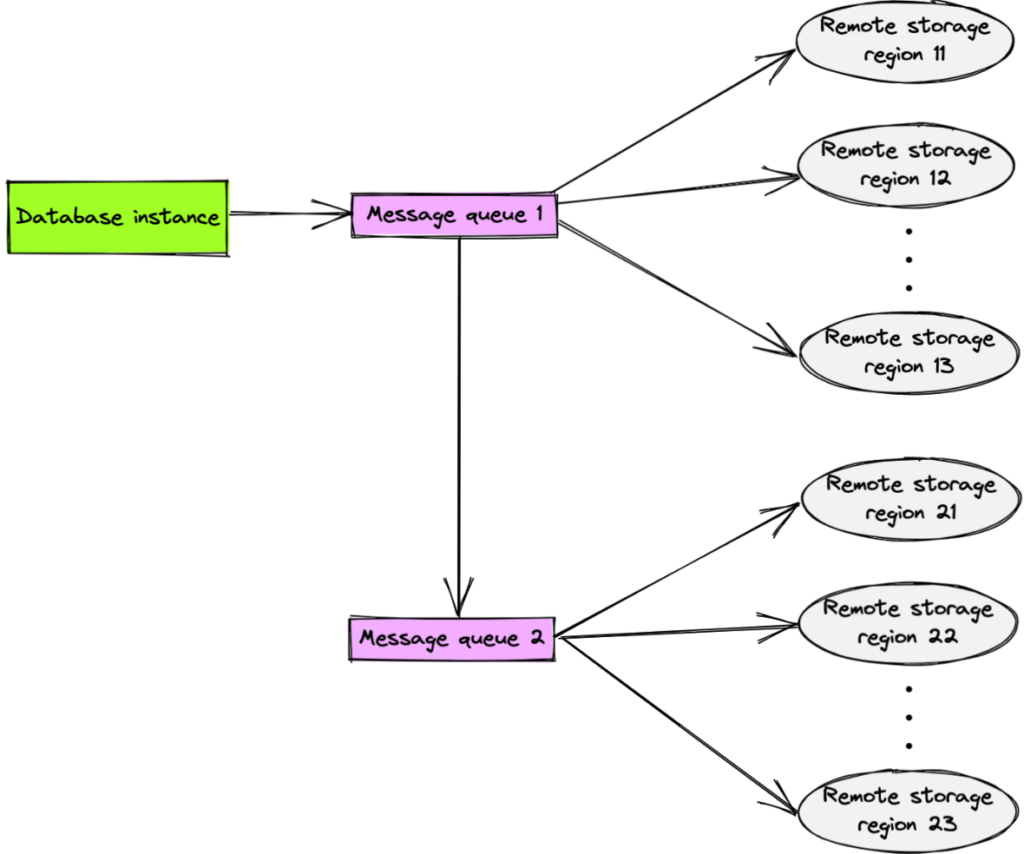
Database geo-redundancy with MQ
The MQ solution sounds good, but there are other nuts to crack. Let’s look at the steps for geo-redundancy with the MQ solution:
- Break the target data into message queue payloads.
- Feed the data to the MQ instance.
- Read the data from the MQ instance.
- Compose the payload to logical backup data.
- Send the data to the remote storage service.
As you can see, you have to develop upstream and downstream data adapting components and host MQ instances. This adds to your operational and maintenance costs and requires extra domain expertise.
Is there a simpler, cheaper solution?
Based on the above solutions and the challenges with them, our requirements are clear: we want a geo-redundant solution that’s scalable, simple, and less expensive. This naturally leads us to cloud services, which have a lower total cost of ownership, a simpler architecture, and easier maintenance. One option is a fully managed MQ service such as Confluent Cloud. It could release you from the MQ processing procedures with a scalable service on the cloud, but that was only part of the issue. You still need to develop upstream and downstream adapting components. Actually, what we need is a Storage as a Service, or to be more precisely, Cross Region Replication as a Service (CRRaaS) solution. With CRRaaS, you can store data in one region and automatically replicate it to other ones.
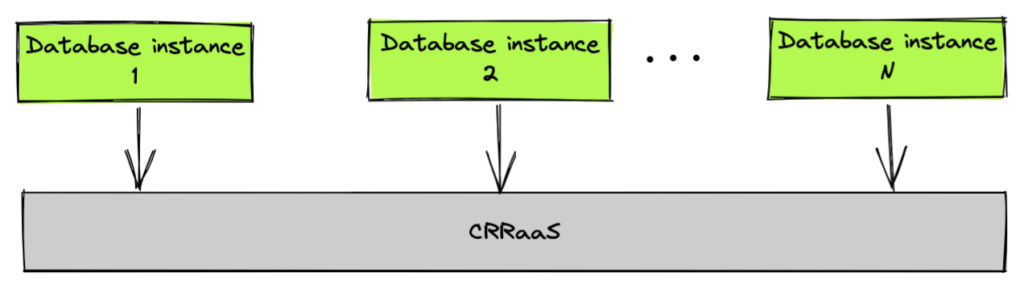
Geo-redundancy with CRRaaS
Comparing popular cloud solutions: S3 and GCS
Let’s take a look at the most widely used object storage services from cloud vendors: Amazon Simple Storage Service (S3) and Google Cloud Storage (GCS). They both have options for cross region replication. Moreover, most databases support backing up data to managed storage services, so you don’t need any data adapting components. In this section, we will compare S3 and GCS and see if they can meet our goals for geo-redundant backup.
S3
The S3 replication service includes cross-region replication. You can define replication rules between two storage buckets with versioning enabled. Amazon S3 geo-redundant replication looks like this:
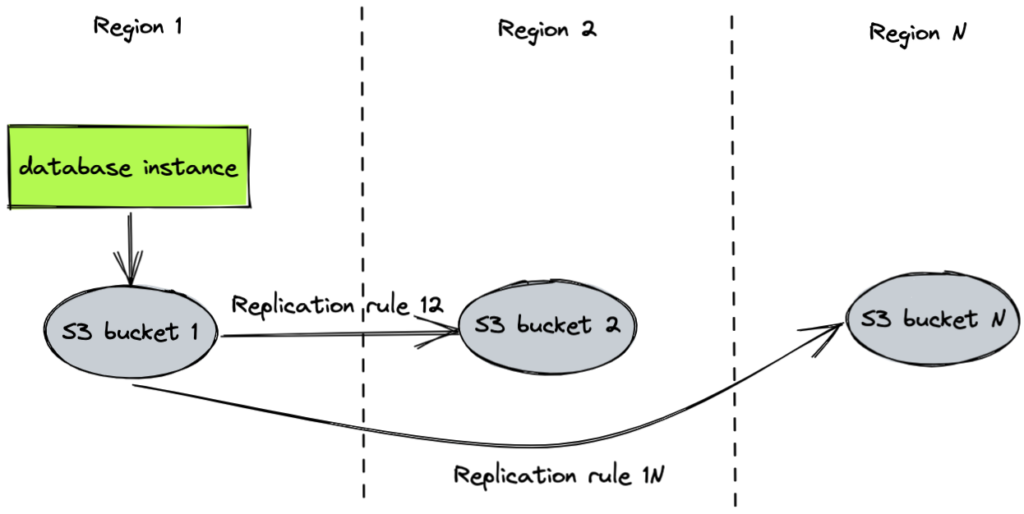
Geo-redundancy with Amazon S3
One Amazon Web Service (AWS) account can only support a maximum of 1,000 buckets. Therefore, when too many database instances require geo-redundant backup, you must define shared buckets among database instances. In addition, S3 lets you set the lifecycle configuration on a bucket for data retention to control cost.
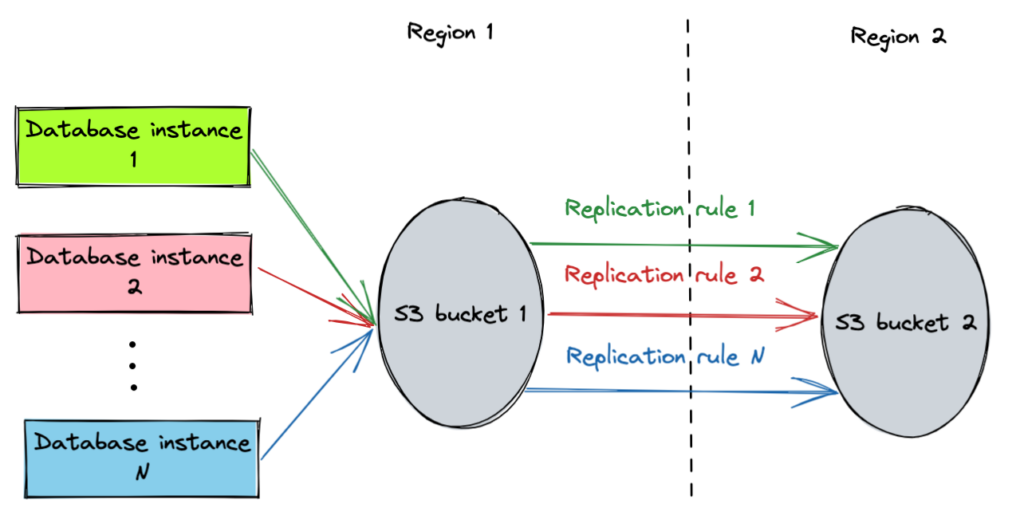
Shared buckets on Amazon S3
GCS
Instead of letting users define replication rules among storage buckets, GCS offers three bucket location types: single-region, dual-region, and multi-region. You can select dual-region or multi-region buckets to get cross region replication.
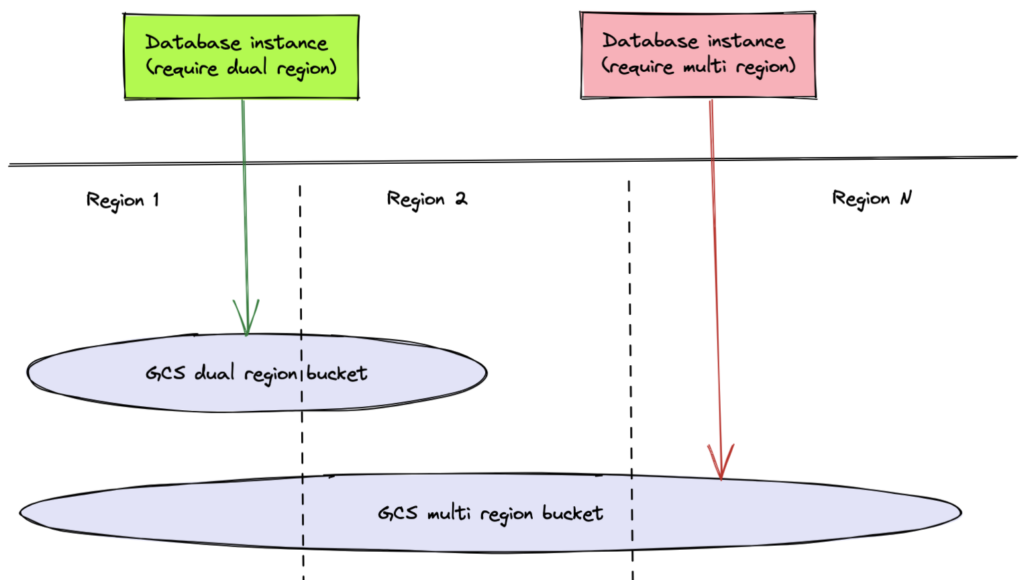
Geo-redundancy with GCS
However, you can only scale dual-region buckets to two backup destinations. To achieve geo-redundancy across more than two destinations, you must choose multi-region buckets.
Comparison
Both S3 and GCS meet our requirements from a CRRaaS perspective, and each has their own unique attributes. This table compares both solutions.
| Geo-redundancy option | S3 replication | GCS dual-region | GCS multi-region |
| SLA | 99.99% within 15 minutes | 99.9% within 15 minutes (turbo replication mode) | 99.9% within 60 minutes |
| Operation burden | Monitor replication performance Manage replication and lifecycle rules | Monitor replication performance | Monitor replication performance |
| Scalability/fault tolerance | Easily scale to any number of regions Can resist failure with N-1 regions | Data distributed in two fixed regions Can resist one-region failures | Data is distributed in two or more regions within the same continent Can resist failures with more than one regions |
| Access latency | Low latency if you access data from the same region | Low latency if you access data from the same region | Unpredictable as data might not be stored in all regions, which is invisible to users. |
S3 and GCS are managed storage services, so developers don’t have to host replication infrastructure. Here are a few things to consider before you make a choice:
- Service quality. S3 supports a Service Level Agreement (SLA) that can replicate 99.99% of new data objects in less than 15 minutes. However, GCS only guarantees to synchronize 99.9% of newly written objects within 60 minutes for multi-region mode. If you need a high Recovery Point Objective (RPO) for your system, S3 should be your choice.
- Ease of operation. GCS is more intuitive to use and selecting a bucket location type is straightforward. Its multi-region bucket greatly simplifies the geo-redundancy operation. With Amazon S3, you need to configure the replication and lifecycle rules, which makes the operation more complicated.
- Customization in fault tolerance. S3 lets you choose the number and locations of target regions for replication. In contrast, GCS offers fixed options, and fault tolerance capability is invisible to users. If your system requires high and controllable failure recovery capability, you should consider S3. For systems that do not require that level of capability, a dual-region bucket is enough.
- Access latency. Both S3 and GCS dual region buckets have predictably low latency because users know which region has a complete data copy. However, it’s unpredictable for GCS multi-region buckets because it does not guarantee all regions in a continent can access the complete data copy.
If a system needs relatively high RPO, predictable latency, and fault tolerance from one-region failures, GCS dual-region buckets can be a good fit. GCS multi-region buckets are also a good choice if you prefer simplicity and higher region failure recoverability. However, if you have very high requirements for RPO, fault tolerance, and access latency—and you want more control over them—use S3.
Summary
It is much easier to develop geo-redundant cold backup for databases with cloud services than traditional systems. However, CRRaaS solutions such as Amazon S3 or GCS won’t solve all your troubles. You must still integrate your systems with the cloud platform. If you want a whole package, then you may want to consider a Database as a Service options such as TiDB Cloud, which provides everything you would expect from a database, fully managed on the cloud.
Keep reading:
- Improve Performance and Data Availability with Elastic Block Store
- How We Reduced Multi-region Read Latency and Network Traffic by 50%
- TiDB Operator Source Code Reading (V): Backup and Restore
Try TiDB Cloud Free Now!
Get the power of a cloud-native, distributed SQL database built for real-time
analytics in a fully managed service.
(Edited By: Calvin Weng, Tom Dewan)
Spin up a database with 25 GiB free resources.



TiDB Cloud Dedicated
A fully-managed cloud DBaaS for predictable workloads
TiDB Cloud Starter
A fully-managed cloud DBaaS for auto-scaling workloads