

Delivering truly personalized AI experiences is complex. It requires Large Language Models (LLMs) to access relevant personal or organizational information and possess the intelligence to translate needs into tangible actions. This pursuit has been a key direction in GenAI application development.
With foundational models like GPT-4o and DeepSeek-V2 becoming genuinely practical, their reasoning and execution capabilities have reached a usable state. This largely explains why many are calling 2024/2025 the “Year of the AI Agent.” However, a model’s inherent ability is only half the story. Crucially, an Agent’s effectiveness hinges on the context it’s given. That’s the core of our discussion today.
Before diving into data foundations, let me share my perspective on AI-native applications (e.g., agents or assistants):
- Flexibility: They must understand and act on relatively ambiguous inputs, unlike traditional software needing precise commands.
- Personalized Context: Their interactions and outputs must be deeply rooted in specific data and background about an individual or organization.
- Action-Oriented (Tool-Use Enabled): They need the ability to call external tools, impacting the real world, often via frameworks like the Model Context Protocol (MCP).
Consider the common executive challenge: endless briefings and a constant hunt for specific figures or project updates, often lost in a sea of documents. It’s tedious for everyone involved. You might need a single data point, but unearthing it can be a major task for your team. Historically, this necessitated dedicated assistants and data analysts.
Now, with smarter LLMs, we have an opportunity for change. As the CTO of a database company and an avid developer, my first personal project was, naturally, a digital personal assistant. Tinkering with this “toy” provided valuable insights into building data foundations for AI-native applications.
When designing such knowledge-based AI applications, many—including myself initially—think of RAG (Retrieval Augmented Generation). Practice, however, revealed a more nuanced reality. Here are some key takeaways:
1. Beyond Big Data: The Primacy of Fresh, Raw Data
In scenarios demanding rapid responses and decision support, raw, event-level data is far more valuable than its vectorized shadow. Why? We often care most about specific details, up-to-the-second data freshness (e.g., a critical customer issue this week versus last year’s satisfaction trends), and subtle nuances lost in aggregation.
Traditional “Big Data” systems, designed for large-scale batch analytics, catered to human limitations in processing raw information. AI Agents, however, can sift through and connect vast, disparate, yet incredibly fresh data points in real-time. If AI can directly access this primary data, our reliance on pre-digested, summarized reports diminishes. My digital assistant, for instance, mines insights from raw emails and JIRA tickets, not pre-prepared presentations. Vectorization is useful, but not the sole solution. In RAG, without access to original data for verification, LLMs are prone to confident “hallucinations.” Industries like HealthTech (relying on real-time epidemiological data) and LegalTech (tracking new case law) have an almost ruthless demand for data freshness.
This means your data platform must excel at ingesting and, more importantly, enabling AI Agents to efficiently access massive, continuous streams of fine-grained business data in real-time.
2. SQL: More Relevant Than Ever as the Human-AI-Data Bridge
Contrary to notions of its decline, SQL’s importance is amplified in the AI era. Here’s how:
- Standardization: AI generates SQL, humans review it, and databases execute it—our most universal language connecting these three realms.
- Trust Through Reviewability: When my AI assistant requests data, I often inspect the SQL. This transparency is vital for trust. Effective human-in-the-loop systems benefit from unambiguous languages like SQL.
- Accuracy: Correct SQL on an ACID-compliant database guarantees accurate data, a cornerstone for reliable AI output.
- Power and Flexibility: SQL’s expressive power handles complex queries, JOINs, and aggregations. Modern SQL databases, like TiDB, support diverse data types (vectors, graphs, JSON, full-text search) via SQL. Table schemas also offer AI valuable structural metadata.
- Mature Security: Databases have robust SQL-based security and access control. AI Agents can be treated as special users with clearly defined permissions, leveraging existing, solved problems.
- LLM Context Efficiency: A precise SQL query retrieving only relevant records is far more efficient for an LLM than processing massive raw datasets, improving output quality and cost.
Your AI data platform needs first-class, high-performance SQL capabilities. AI must interact with core data via SQL.
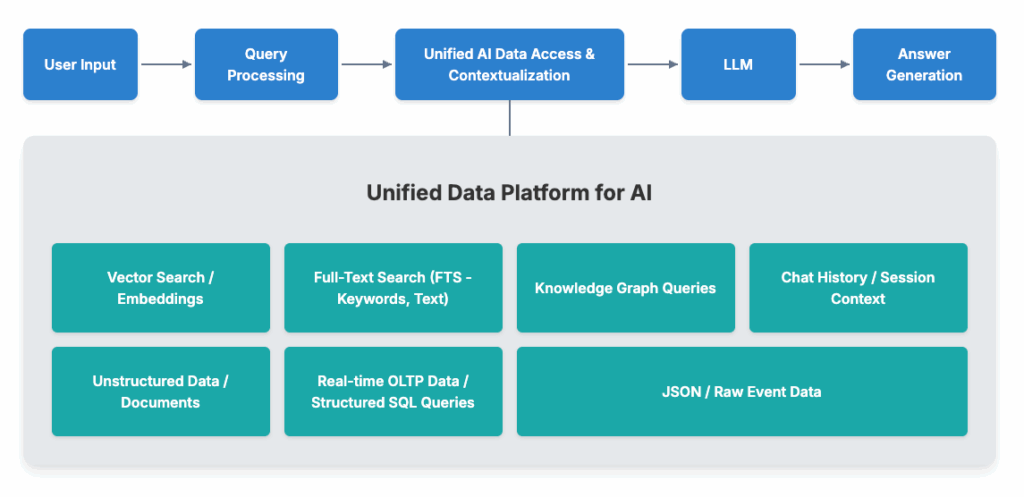
3. The Unified Platform: Essential for Comprehensive Context
While vector search is prominent, it’s just one piece of the AI data puzzle. True understanding of complex business scenarios requires AI to query and correlate across diverse data types:
- Full-Text Search (FTS): Key information often resides in specific keywords within documents, logs, or emails. For instance, finding all emails about “contract breach terms” or logs with a specific error code is often best done with FTS. My interactions with my AI Agent frequently involve text-search SQL. If you’re interested in how FTS can play a bigger role and how TiDB supports efficient FTS, the blog post “Introducing Full-Text Search for TiDB: Enhancing RAG Applications with Hybrid Search” dives deeper and is worth a read.
- Real-time Operational Data (OLTP): AI insights lose value if not based on the latest business snapshot, crucial for applications like real-time fraud detection.
- Varied Data Structures: This includes traditional structured data, semi-structured data (like JSON), and graph data, often used in RAG and knowledge graphs.
Imagine assessing a major client’s risk. An AI assistant might need to:
- Use FTS on knowledge bases and ticket systems (JIRA) for records with “urgent” or “complaint.”
- Query CRM (Salesforce) for contract status and payment history (OLTP).
- Use vector search on email archives for relevant industry discussions.
- Crucially, JOIN this disparate information (text, structured records, vectors) into a 360-degree risk view to suggest actions.
This integration is key to an AI Agent’s value. Advanced Agents might use protocols like MCP (Model Context Protocol) to access diverse external contexts. To learn more about MCP and TiDB’s data support, read “Building Intelligent AI Agents: A New Data Application Paradigm with MCP and TiDB” this blog post.
If data is siloed across specialized systems (a relational DB for CRM, a search engine for documents, a vector DB for embeddings), the AI’s task becomes a complex, fragile mess of cross-system synchronization. This is inefficient and error-prone.
Therefore, the ideal AI data platform must be unified. Not a mere collection of an OLTP database, an OLAP warehouse, a vector store, and a search engine, but a deeply integrated system. It should allow AI to use a common interface (ideally SQL-based or SQL-friendly) to seamlessly query and correlate all data types. This is TiDB’s philosophy: a unified architecture blending OLTP, OLAP, vector processing, FTS, and JSON support. This enables AI Agents to get rich, consistent context from one place, using familiar SQL, without juggling data across systems. This unified platform provides the “right context” critical for AI-native applications.
Final Thoughts: Building a Solid “Factual Foundation” for True Intelligence
To summarize: AI-native applications that drive real business value must be rooted in fresh, raw data; leverage SQL for robust interaction; and draw insights from a unified data platform capable of handling diverse data and mixed workloads.
At TiDB, we’ve always championed the power of a unified data platform, designed from day one for both high-concurrency transactions (OLTP) and real-time complex analytics (OLAP/HTAP). Now, facing the new query demands and even more mixed workloads brought by AI Agents, we are more convinced than ever that this unified design philosophy—one that can flexibly adapt to diverse needs—is more critical than ever.
So, before chasing the next big LLM, pause and examine your data foundation. Is it truly ready to fuel future intelligent applications? If these ideas resonate, and you’re looking to lay the groundwork for your AI initiatives, our new ebook, The Modern, Unified GenAI Data Stack: Your AI Data Foundation Blueprint, offers a practical blueprint.
Elevate modern apps with TiDB.



TiDB Cloud Dedicated
A fully-managed cloud DBaaS for predictable workloads
TiDB Cloud Starter
A fully-managed cloud DBaaS for auto-scaling workloads