

Whether you’re processing thousands of concurrent writes per second or scaling out infrastructure to meet a burst in demand, latency spikes can undermine user experience, reliability, and trust. At PingCAP, we obsess over these details. Our mission is to help teams build and scale confidently on distributed SQL. This post highlights how a subtle performance challenge deep inside our storage engine—write stalls during data ingestion—could ripple across workloads in production and impact TiKV write latency.
In this blog, we’ll dive deep into how RocksDB, Raft, and TiKV interact, and how we solved this write stall challenge through two key optimizations that now eliminate those stalls without compromising correctness.
When Bulk Data Ingestion Slows Down TiKV Write Latency
TiDB, a distributed SQL database, scales effortlessly with modern applications. Under the hood, it separates compute and storage to optimize for performance and flexibility. TiKV, an open-source distributed key-value engine, serves as the storage layer powering TiDB’s transactional workloads.
Whenever TiDB needs to move large amounts of data—for example, during Region migration, cluster rebalancing, or scaling operations—it relies on TiKV to load that data quickly and reliably.
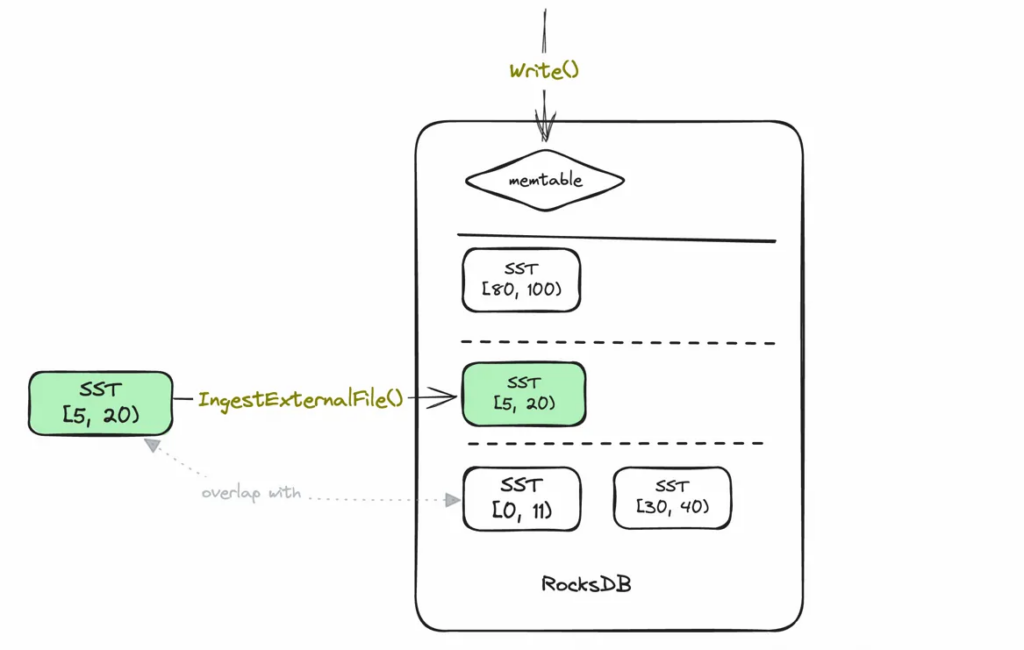
TiKV uses RocksDB as its embedded storage engine. When large volumes of data need to be loaded, it uses a method called IngestExternalFile(), which directly imports Sorted String Table (SST) files into storage. This approach bypasses the normal write path, reducing memory pressure and minimizing compaction overhead. RocksDB’s ingestion process is designed for speed and efficiency — especially compared to writing data through the foreground path.
But this speed comes with a catch. To maintain sequence number consistency in RocksDB’s log-structured merge tree (LSM-tree), the ingestion process temporarily blocks all foreground writes. This temporary pause is known as a write stall.
In isolation, a short stall might not matter. But all Regions (logical partitions of data) on the same TiKV node share a single RocksDB instance. So when one Region triggers a write stall, every Region on that node is affected—even if they’re unrelated. During large migrations or cluster scaling, this can lead to widespread write latency spikes, affecting the performance of otherwise unrelated workloads.
Why Sequence Numbers Matter to TiKV Write Latency
In RocksDB’s log-structured merge tree (LSM-tree), data exists across multiple levels. To preserve consistency and ensure fast, correct reads, RocksDB assigns a global sequence number to every write.
These sequence numbers are especially important during SST (Sorted String Table) ingestion. SSTs are immutable, sorted files used by RocksDB to store data efficiently on disk. When new SST files are ingested via IngestExternalFile(), they must fit into the sequence number ordering rules that RocksDB enforces.
Specifically:
- A key stored in a lower level (like L0) must have a higher sequence number than any version of that key in a higher level (like L6).
- This ordering allows RocksDB to return the latest value quickly without scanning deeper levels unnecessarily.
- It also prevents stale or partial reads when scanning across SSTs.
To enforce this, RocksDB follows strict steps during ingestion:
- Overlapping keys before ingestion: If a key in the new SST overlaps with one in the MemTable, RocksDB first flushes the MemTable to L0. The flushed data receives a sequence number, and the SST is placed at the same level but assigned a higher sequence number.
- Overlapping keys during ingestion: RocksDB triggers a write stall, pausing all foreground writes. This acts like a lock, ensuring that all keys in the SST receive a consistent global sequence number.
- Overlapping keys after ingestion: Once the SST is ingested and writes resume, any new writes to the same key will go to the MemTable and receive a newer sequence number.
This process guarantees that reads always reflect the most up-to-date state and prevents mixing old and new versions of the same key in scan results.
To maintain read correctness, RocksDB enforces that ingested SSTs must have higher sequence numbers than any overlapping data at lower levels. This is enforced via a write stall to preserve consistency.
First TiKV Write Latency Optimization: Skip the Flush, Cut the Stall
One of the primary contributors to write stall duration during SST ingestion is flushing the MemTable. Flushing is an expensive I/O operation that takes time and temporarily blocks all writes. Since IngestExternalFile() may trigger a flush if it detects overlapping key ranges in the MemTable, it often extends the stall unnecessarily.
To address this, TiKV implemented an optimization in TiKV#3775, using a RocksDB feature called allow_blocking_flush.
How It Works
Instead of letting RocksDB decide when to flush during ingestion, TiKV now:
- First attempts ingestion with
allow_blocking_flush = false. If no flush is needed, ingestion proceeds immediately. - If the ingestion fails due to a required flush, TiKV manually flushes the MemTable outside of the write stall.
- It then retries ingestion with
allow_blocking_flush = true, which now succeeds without triggering additional stalls.
The Impact
After removing the MemTable flush from the ingestion path, write stall duration improved significantly—up to 100 times faster in worst-case scenarios.

Second TiKV Write Latency Optimization: Eliminate the Stall Entirely
While the first optimization dramatically reduced the duration of write stalls, they could still occur. The next question was: Can we eliminate the write stall completely?
The Assumption: Sequential Writes via Raft
TiKV uses the Raft consensus protocol, which enforces sequential commits per Region. Under normal conditions, only one thread writes to a Region at a time, whether during:
- Region creation (ingesting SSTs),
- Normal operation (handling client writes), or
- Region destruction (clean-up).
This single-threaded write behavior means we can safely assume that no overlapping writes occur during ingestion—except in one edge case.
The Exception: Compaction-Filter Garbage Collection
TiKV implements MVCC (multi-version concurrency control) garbage collection using RocksDB’s compaction filter mechanism. This operates outside of Raft, directly at the RocksDB layer.
Here’s where the complication arises:
TiKV uses multiple column families (CFs)—separate logical partitions within a single RocksDB instance. Each CF stores a different type of data:
- The Default CF holds user data (the actual values).
- The Write CF stores version metadata, such as commit timestamps, which determine key validity.
- The Lock CF handles transactional state.
During GC, the compaction filter runs on the Write CF, identifying and discarding outdated versions of keys. But to complete cleanup, TiKV also needs to delete the corresponding values in the Default CF, which requires calling RocksDB’s Write() method. These deletions happen as foreground writes—outside the Raft layer—and can potentially overlap with SST ingestion.
This breaks the single-writer assumption and introduces a potential race condition.
The Solution: Ingest Without Blocking Writes
To eliminate write stalls while preserving correctness, TiKV introduced two key changes:
Enable Ingestion with allow_write = true
A new option was added in RocksDB#400, allowing ingestion to proceed without triggering a write stall. When allow_write = true, it’s up to the RocksDB user (TiKV) to ensure no overlapping writes occur during ingestion.
Add Range Latches for Safety
To enforce that guarantee, TiKV added range latches in TiKV#18096. Before SST ingestion or GC begins, the process must acquire a lock on the relevant key range. This ensures:
- Foreground writes triggered by GC won’t interfere with ingestion.
IngestExternalFile()can safely run withallow_write = trueand avoid the write stall entirely.
The Impact
With these changes, TiKV can now safely ingest SSTs without blocking writes—dramatically improving tail latency and write performance under load.
Results from TPCC Benchmark
- P9999 write thread wait time dropped by over 90% (25ms → 2ms)

- P99 write latency dropped by more than 50% (2–4ms → 1ms)

Conclusion
What began as a subtle storage-layer challenge—write stalls triggered during SST ingestion—turned into a meaningful performance breakthrough for TiKV.
By taking a deep look at how RocksDB handles sequence number consistency and designing targeted optimizations, the TiKV team delivered two key improvements:
- Reduced write stall duration by moving MemTable flushes outside of the ingestion path (via
allow_blocking_flush = false) - Eliminated write stalls entirely by coordinating compaction-filter GC and ingestion through
allow_write = trueand range latches
These changes had a measurable impact:
- Maximum write duration improved by nearly 100x
- P9999 write wait time dropped by over 90%
- P99 write latency reduced by more than half
Together, these optimizations help TiKV deliver the kind of predictable, scalable write performance that teams expect from a distributed database — even under pressure from Region migration, garbage collection, or cluster scale-out.
If you’re building on TiKV or TiDB, and performance stability during data movement or scaling is critical to your workloads, these optimizations are already working for you. And if you’re tackling similar issues in your own system, we hope this post gave you a helpful lens into the tradeoffs and solutions that worked for us.
We’re always refining and sharing what we learn — if you have any questions, please feel free to connect with us on Twitter, LinkedIn, or through our Slack Channel.
Experience modern data infrastructure firsthand.



TiDB Cloud Dedicated
A fully-managed cloud DBaaS for predictable workloads
TiDB Cloud Starter
A fully-managed cloud DBaaS for auto-scaling workloads